
-
I tried ChatGPT for the first time this morning. I needed a shell script which will downscale a bunch of JPEG images in a directory. I’m perfectly capable of writing one myself, but that would mean poking through the ImageMagick docs trying to remember which of the several zillion arguments is used to reduce the image size. Having one written for me by ChatGPT saved about 15 minutes of this (it wasn’t exactly what I wanted, I did need to tweak it a little).
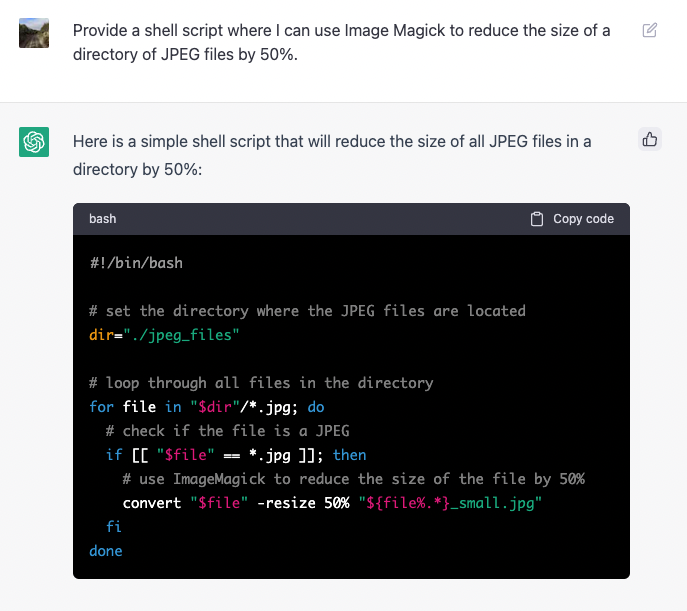
I don’t know what the future holds with AIs like this, and I acknowledge that it has had an effect on some peoples’ living (heck, it may have an effect on mine). But I really can’t deny the utility it provided this morning.
-
Flights and accomodation for the Europe trip booked. It’s been hanging around my to-do list for the last two months. Good to finally check that off.
-
I suspect, in a world where companies are replacing staff with AIs, that the organisations that choose to keep the humans on will have the competitive advantage. You can’t form a connection with a machine.
-
New Stuff Setup Weekend
A bunch of new stuff I’ve bought has arrived recently and this is the weekend I finally get around to setting it up. New Furniture The largest one is a new couch. I’ve been sitting on a second-hand two seater that my parents gave me when I’ve moved out. It did the job but it was getting quite old and saggy, and I’ve been finding myself wanting to have something larger that I can lie across. Continue reading →
-
Spotify Video Follow-up
Some follow-up from my post about Spotify videos. I looked into this a little and from what I understand they’re not full videos but “short looping video clips that play during certain songs,” at least according to this website. So I guess my initial belief is incorrect. Spotify might have music videos (they’re a bunch of articles about them thinking about it in 2020-21) but this looks to be completely different. Continue reading →
-
I just realised there’s a downside to cross-posting my Micro.blog posts to Mastodon: I can’t use hashtags ironically anymore. Not that I’m in the habit of doing so, but the occasional one would be nice.
Hmm, how to adapt? £thinking
-
Toying with the idea of cancelling my Spotify subscription. There are a number of reasons for this, but one that really gets to me is the insistent need to show video when playing a song. And there’s no way to turn it off anywhere (I tried looking for one).
I listen to music when I’m walking or driving or doing something that needs my visual attention. But even if I am in a position to stare at my phone, I don’t want to be watching music videos. So why is my bandwidth being wasted streaming a video when an MP3 will do?
So obnoxious it borders on being offensive.
-
Trying out Keyboard Maestro to automate some niggly things I occasionally need to do. Got my first macro working, which converts a selected string
FromCamelCasetoUPPER_SNAKE_CASE.
So far I’m impressed. Looking forward to finding other things I can automate away with this.
-
I don’t know what I need to do to get Swift Packages working.
It never seems to work for me. The option to add dependencies are in the menu, but when I try to use them, they error out or cannot resolve the dependencies for some reason.
This is in addition to not being able to see or edit “Package.swift” as a text file, which I thought was the whole thing with this.
Is it the version of Xcode I’m using? Does it work for anyone outside of Apple? Libraries are being released with Swift Package support so it must work for someone.
-
Read my last post during lunch to see how well it read. Couldn’t get past the third paragraph without thinking: wow, this is really boring. Rewriting it helped a little, but it’s still rather dull. Maybe it’s the topic?
In either case, it’s something I need to work on. 🧑💻
-
On Higher Order Functions In Go
It’s a bit surprising that higher-order functions like map and filter have not caught on in Go. They seemed to have caught on quickly when they were added to Java. One of the long standing issues back then was the clunky and verbose approach to writing closures. Java 8 fixed this with the introduction of the lambda (the -> operator). Suddenly, what once took multiple lines of boilerplate could be done in a single expression. Continue reading →
-
Spent the last week updating my travel blog a bit. Started writing about the the trips around the south pacific I took for work almost 10 years ago. I’ve been wanting to write about this for a while, before I forget most of it. I’m glad that I’ve finally got around to doing so.
-
A watched kettle never boils, and a watched clock will not get the train arriving sooner (sadly).
-
Making A Long Form Posts Category In Micro.blog
I use the Categories feature of Micro.blog to organise the types of posts I make on this site. One of the categories I have on this blog is called Long Form Posts, which I use to file all the posts I have that have titles. This is done automatically, such that I don’t have to think about adding a post to this category once I’ve written it1. It’s a little hard to find the relevant features in Micro. Continue reading →
-
I, Developer
There was a bit of a discussion on Mastodon and various blogs about how best to call someone who writes code for fun or profit. I’ll spare you the prologue of how this discussion that has been going on since the start of the profession itself: I’m sure you’ve heard it all before. But hearing one of these terms today got me thinking about this, and I thought I’d say what my preferences are. Continue reading →
-
Pro tip: don’t have a sprint planning meeting with the hiccups. I’ve tried it today and it’s just didn’t work out.
-
Mahjong Score Card Device
I’ve recently started playing Mahjong with my family. We’ve learnt how to play a couple of years ago and grown to like it a great deal. I’m not sure if you’re familiar with how the game is scored, and while it’s not complicated, there’s a lot of looking things up which can make scoring a little tedious. So my dad put together a Mahjong scoring tool in Excel. You enter what each player got at the end of a round — 2 exposed pungs of twos, 1 hidden kong of eights, and a pair of dragons, for example — and it will determine the scores of the round and add them to the running totals. Continue reading →
-
Tried doing some electronics this morning. Not much to show for it apart from some reading, designing, and driving to Jaycar to grab some components. This really is an activity where I’m still quite a novice.
-
OS/2 Dreaming
I’ve been thinking of OS/2 recently. Yes, the ill fated OS that IBM built with Microsoft. Re-reading the Ars Technica write-up of it and listening to the Flashback episode again fills me with nostalgia. Truth is that a lot of my early experiences with computing began with OS/2. Dad was working somewhere that used it, and I had a chance to play with it whenever he bought his laptop home. We had a plain old DOS home computer as well but it wasn’t as powerful or exciting as the laptop as dad’s laptop. Continue reading →
-
Follow-up to my last post: you can turn off committing after conflict resolution in GoLand by clicking “Modify options” in the Merge dialog and selecting “Do not commit the merge result.” This should display the
--no-commitflag.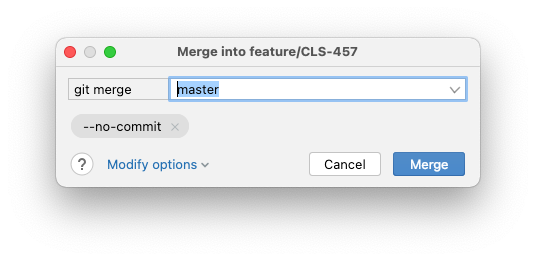
Ok, I admit it’s pretty close to how it works on the command line; although not when you have conflicts, and the only time I merge in GoLand instead of the command line is when I need to resolve conflicts (I prefer the diff/merge tools there). But to be fair to GoLand, it doesn’t know about my merging preferences.
-
I don’t understand code editors that think they know when to commit changes “better” than I do.
GoLand is guilty of this. I just finished resolving merge conflicts, but instead of letting me make sure the resolved conflicts actually build and pass the test, GoLand just commits them as soon as I’ve finished picking the hunks I want to use. This means any fixes I need to make cannot go into the merge commit. That commit is now unstable.
One could argue that this is the proper way to do things, that the merge commit should only contain conflict resolutions and nothing else. I don’t agree. I’m bound to make mistakes while resolving conflict, and I want to make sure what I’m committing is actually working code. It probably doesn’t matter in the grand scheme of things, and it wouldn’t be the first time I make a commit with dodgy code. But I’d like to reduce the number of times that happens if I possibly can.
Besides, conflicts in Go imports or module versions I can usually fixed by running tools. I tend to resolve these conflicts quickly, expecting to get errors and duplicates that I can fix with a couple of commands (they usually need to be formatted anyway). I can’t do this if the code editor decides when to actually commit the changes.
Stage the resolved conflicts all you like, but let me actually commit them when I say so.
-
This hollow is hot property at the moment. It was occupied by a couple of kookaburra chicks about a month ago. They’ve since flown the nest. Now a pair of rainbow lorikeets are interested in it.

-
It kills me that Pinboard doesn’t automatically set the title of a bookmark if you add one without it. So easy to fetch the page and get it from there. It can be a setting if privacy/costs are a concern. But really, having this feature would be a massive usability improvement.
