-
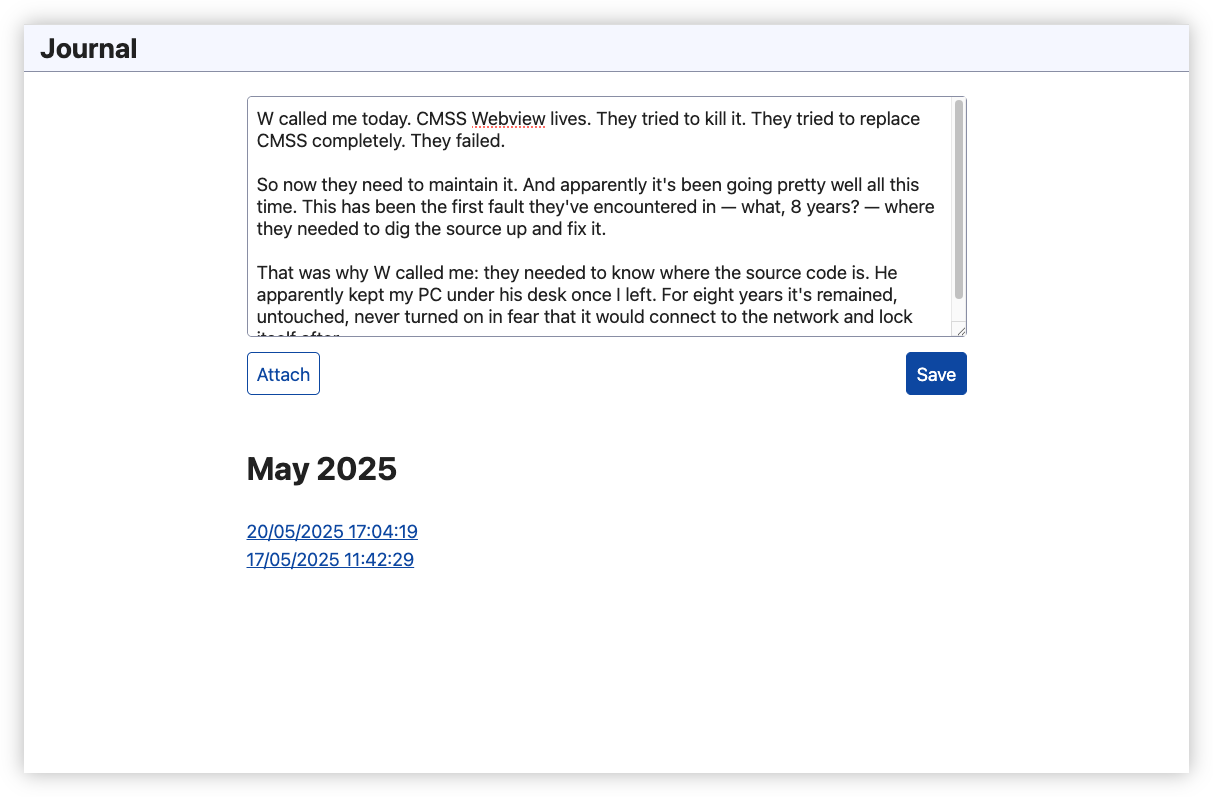
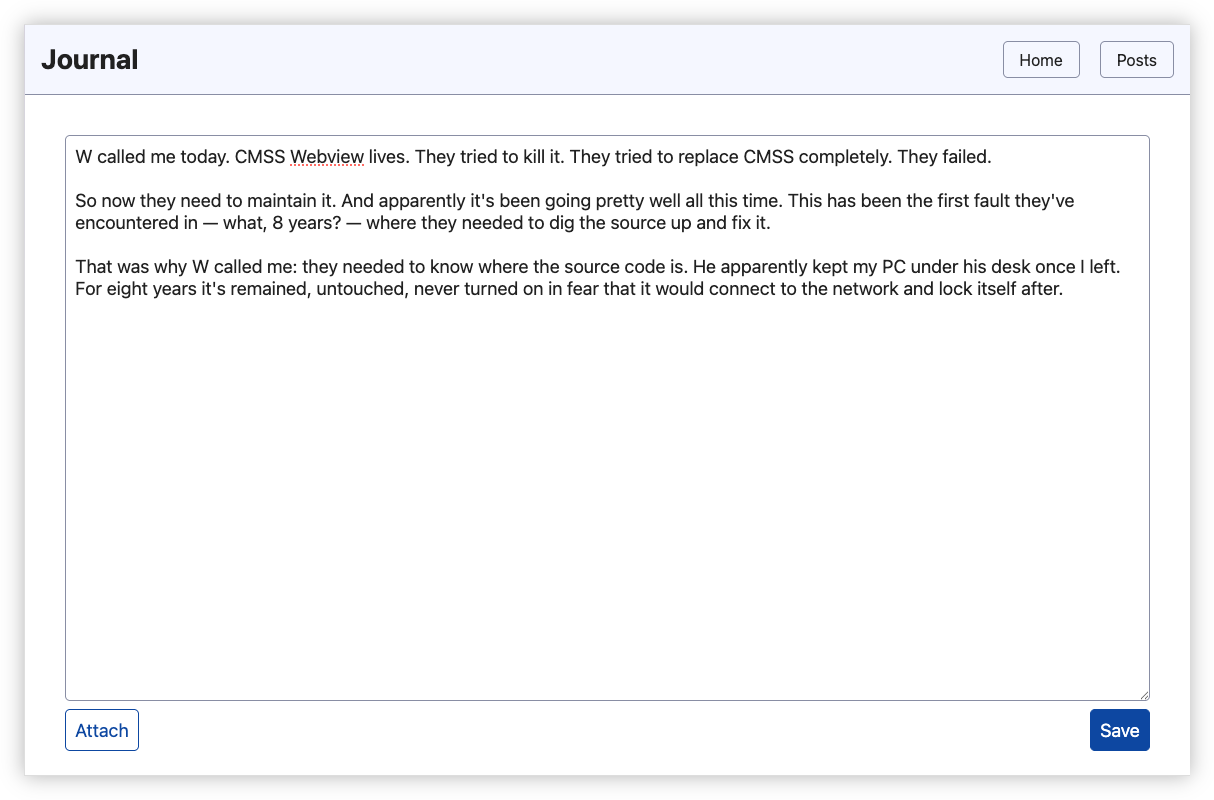
Had a reason to write a journal entry today, which meant I had a reason to work on the journaling app. Biggest change was moving the entry list to a separate page and supersizing the text-area to allow for larger entries. Good thing too: today’s was going to need all the space it could get.
-
If only joining new Discord servers is enough to satisfy the “get out more” goal I set for myself. It induces the same feelings I get when I walk into a room of people I don’t know all getting along. 😬
-
Day 5: reflection
#mbjune

-
Working on that Godot game again, mainly coming up with mechanics for a new level 2. This is what I’ve got so far: a mine tethered to a balloon. Their idle state is just bobbing up and down, but I am planning a variant which will drop their payload and fly away when the player is nearby.

-
I’m gonna miss these malfunctioning 1st gen Myki readers when they eventually get replaced.

-
Encapsulation In Software Development Is Underrated
Encapsulation is something object-oriented programming got right. Continue reading →
-
Day 4: nostalgia
A bit of a personal one today: the back room of my Nonna’s house, taken 11 years ago while she was in the process of moving out. Many things in this photo that are nostalgic in their own right. The house has been demolished and Nonna has past on, so I’m glad I have this. #mbjune

-
Me, exactly a month ago, about how I didn’t care for page transitions:
Anyway, that’s the feeling at the moment. Maybe I’ll come around.
I think I’m coming around.
-
Spent most of the day hitting my head against the wall trying to get this damn service to work. I came up with a version which I thought would work, to a degree. But then I handed it to the testers: fail, fail, fail, fail, fail. Argh! I guess it’s back to the wall tomorrow. 😫
-
Day 3: shadow
#mbjune

-
I wonder if stations can benefit from installing high tables. Seating is useful, but it’d also be useful if I had access to a surface to temporarily place a coffee or wet umbrella when I get something from my bag.
-
I found Jason’s position about Apple adding gambling odds to their sports app a little odd (no pun intended). Not to say that he endorses it — he definitely does not — but I would’ve thought he’d recognise that people buying Apples products expect a premium experience. And that adding such, one might say, “vulgar” features to their app, degrades that experience.
Or at least this probably how I’d feel about it. I don’t watch sports, so this has little impact on my experience. But if I did, I’d probably find the whole thing rather dirty. I can’t stand all these awful sports betting apps.
-
If I had a dollar for every time I mix up
brew updateandbrew upgrade, I’d probably be able to quit my job. -
🔗 Simon Willison: No build frontend is so much more fun
If you’ve found web development frustrating over the past 5-10 years, here’s something that has worked worked great for me: give yourself permission to avoid any form of frontend build system. […] The joy came flooding back to me! It turns out browser APIs are really good now.
None of my frontend projects are used for “real” things, so I’m not speaking from authority here. But I don’t care: I still think the worst part of frontend development are all the crummy build tools. Remove them all and web development can be really fun.
-
Rubberducking: Of Brass and Browsers
🦆: Did you hear about The Browser Company? L: Oh yeah, I heard the CEO wrote a letter about Arc. 🦆: Yeah, did you ever use Arc? L: Nah. Probably won’t now that it seems like they’ve stopped work on it. Heard it was pretty nice thought. 🦆: Yeah, I heard Scott Forstall had an early look at it. L: Oh yeah, and how he compared it to a saxophone and recommended making it more like a piano. Continue reading →
-
I hear Apple executives have decline John Gruber’s invitation to his live Talk Show. This may end up being a good thing. The executives were always so guarded, it felt like an interview with a politician. Having someone outside that bubbles will probably make for a much better show.
-
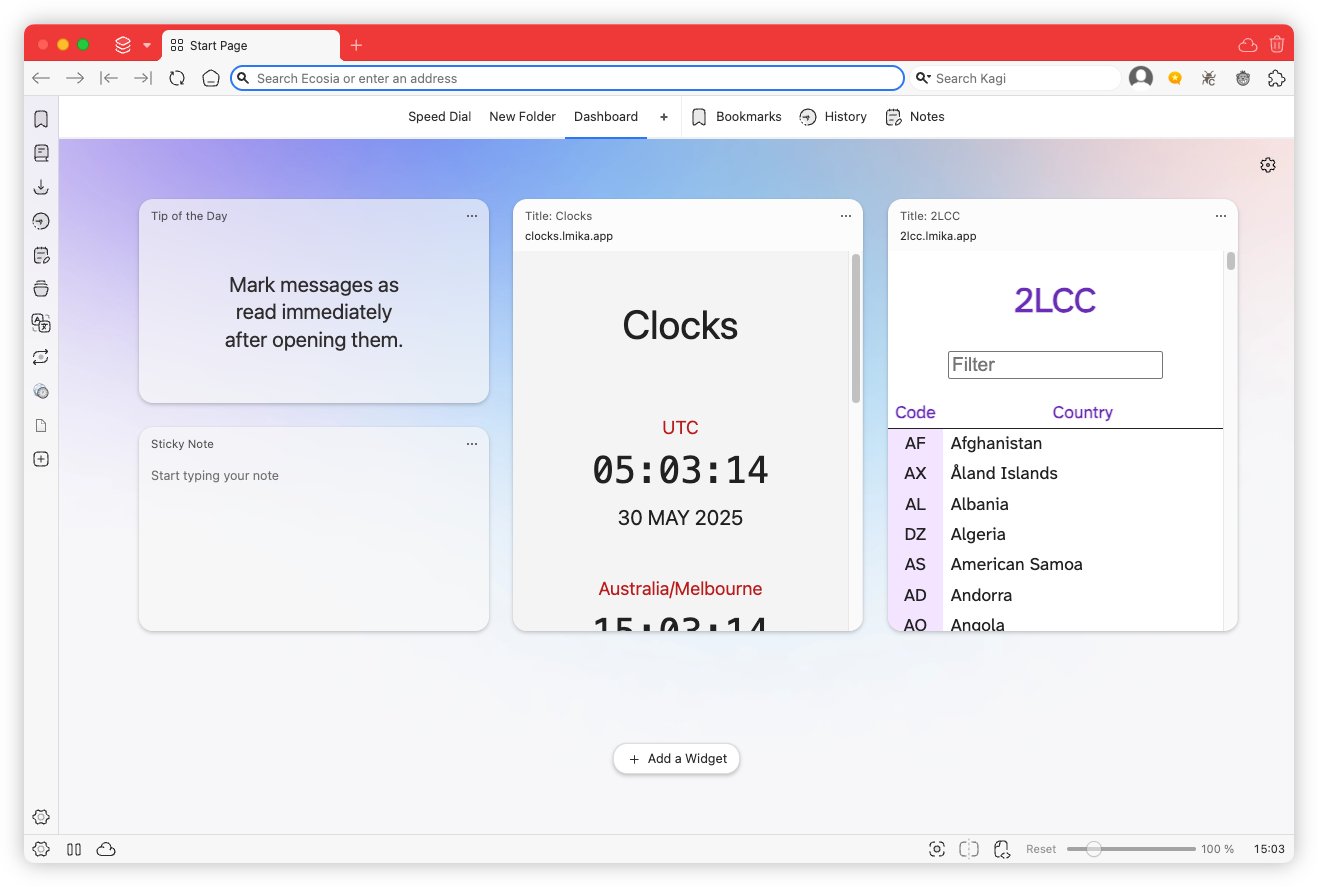
TIL that Vivaldi has a dashboard of sorts. I discovered it by accident: I created a new tab, and while moving my mouse to the URL bar, I clicked too early and revealed it. Could make a nice canvas for those little web tools I use for work.
-
So Apple wants to get serious about gaming, eh? Here’s a suggestion for them: instead of spending dev resources on new, dedicated gaming apps, see if you can get a game from 2010 running at more than 10 FPS with all the visual settings set to low.
-
Enjoyed the interview with Kagi’s founder Vladimir Prelovac on Manton’s Timetable podcast. Motivated me to sign up and give Kagi a try. Let’s see this thing the cool kids online are raving about.
-
Getting pinged on all sides at the moment. So tempting to reply with something like:
Thank you for messaging Leon. You are currently number
2in the queue.But no, I won’t. I’ll be good. 😀
-
“Get out more” goal for May failed. ❌
Oh, I’m still slipping on this goal. 😩
-
I find it amusing that vandals are tagging this wall with chalk. Their graffiti stays up for a few days before the cleaners come with what I assume are industrial-strength erasers. 😄

-
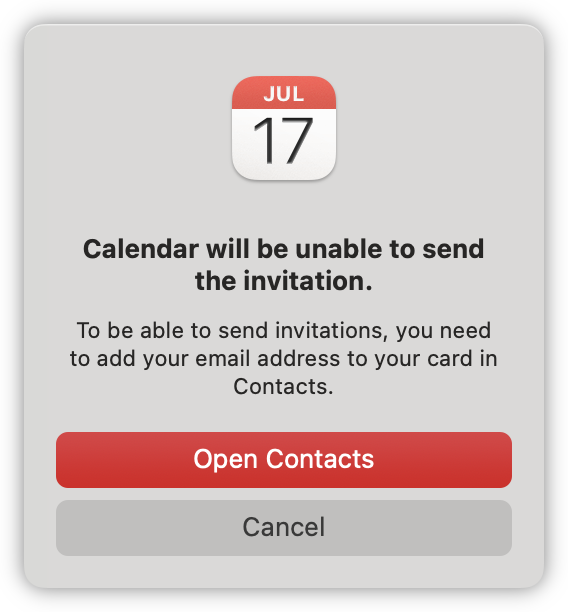
Dear MacOS devs,
Since you already know the email address I’m trying to invite — you included it as an auto-complete suggestion after all — may I suggest that you show a New Contact form pre-filled with said address when I click “Open Contacts” here? Saves me a click and a copy-paste.
Cheers.