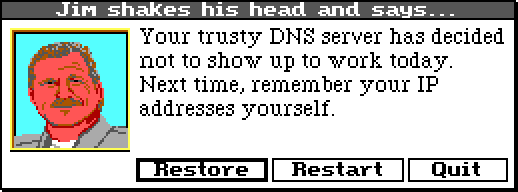
-
Since I’m not a huge user of iCloud, the fact that I only have 5 GB doesn’t offend me. But seeing the breakdown of my storage usage, I can understand why people think Apple is being unreasonable here. To use up 80% of the available storage and leave a measly 1 GB for personal use is not great.
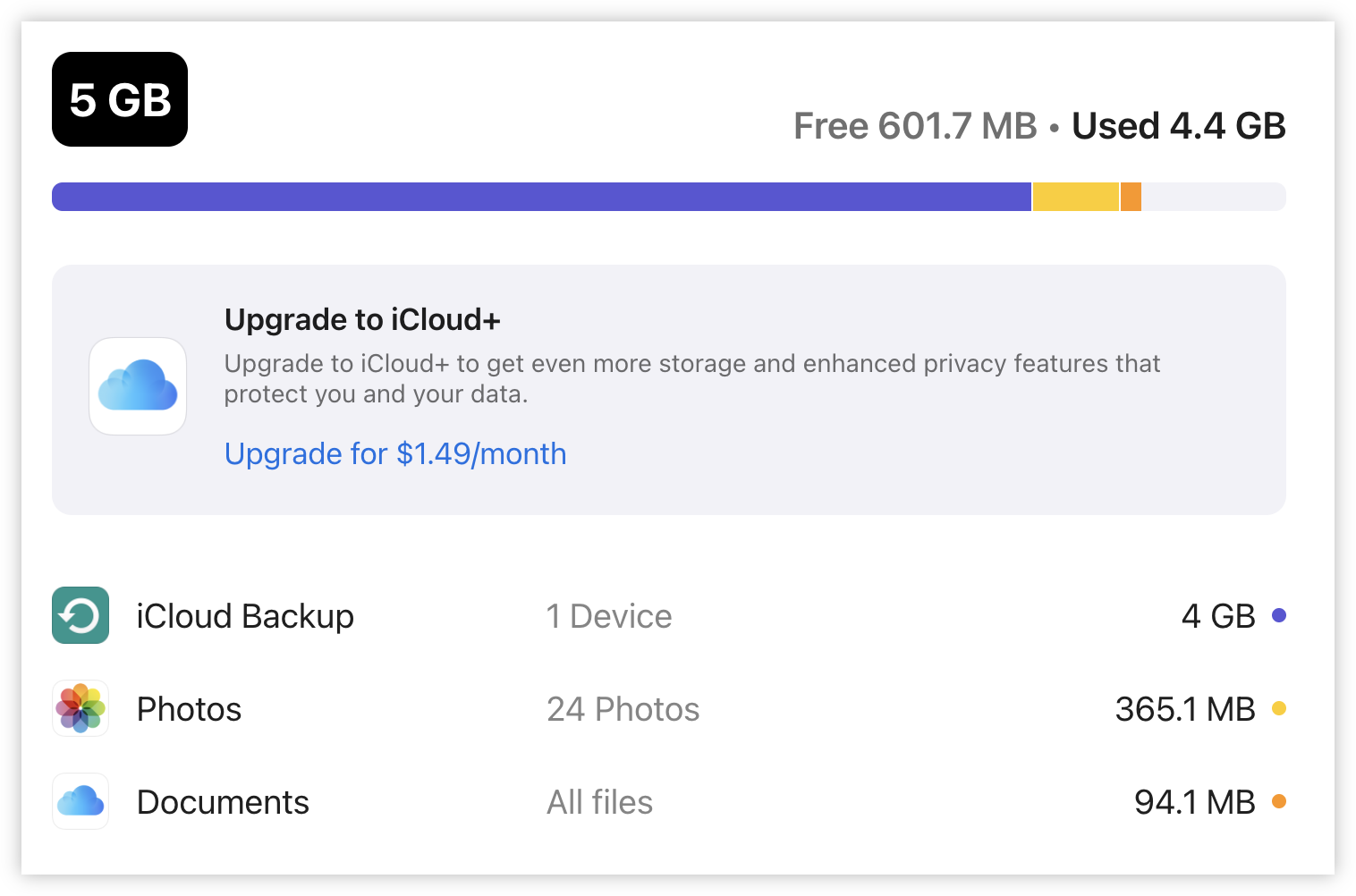 screenshots
screenshots -
Logged into the iCloud web-portal for the first time today (I completely forgot that there was a web portal). I don’t know if this is a thing many people use, but it’s… okay. A little slow, but potentially useful for those times when you can’t access something via native apps.
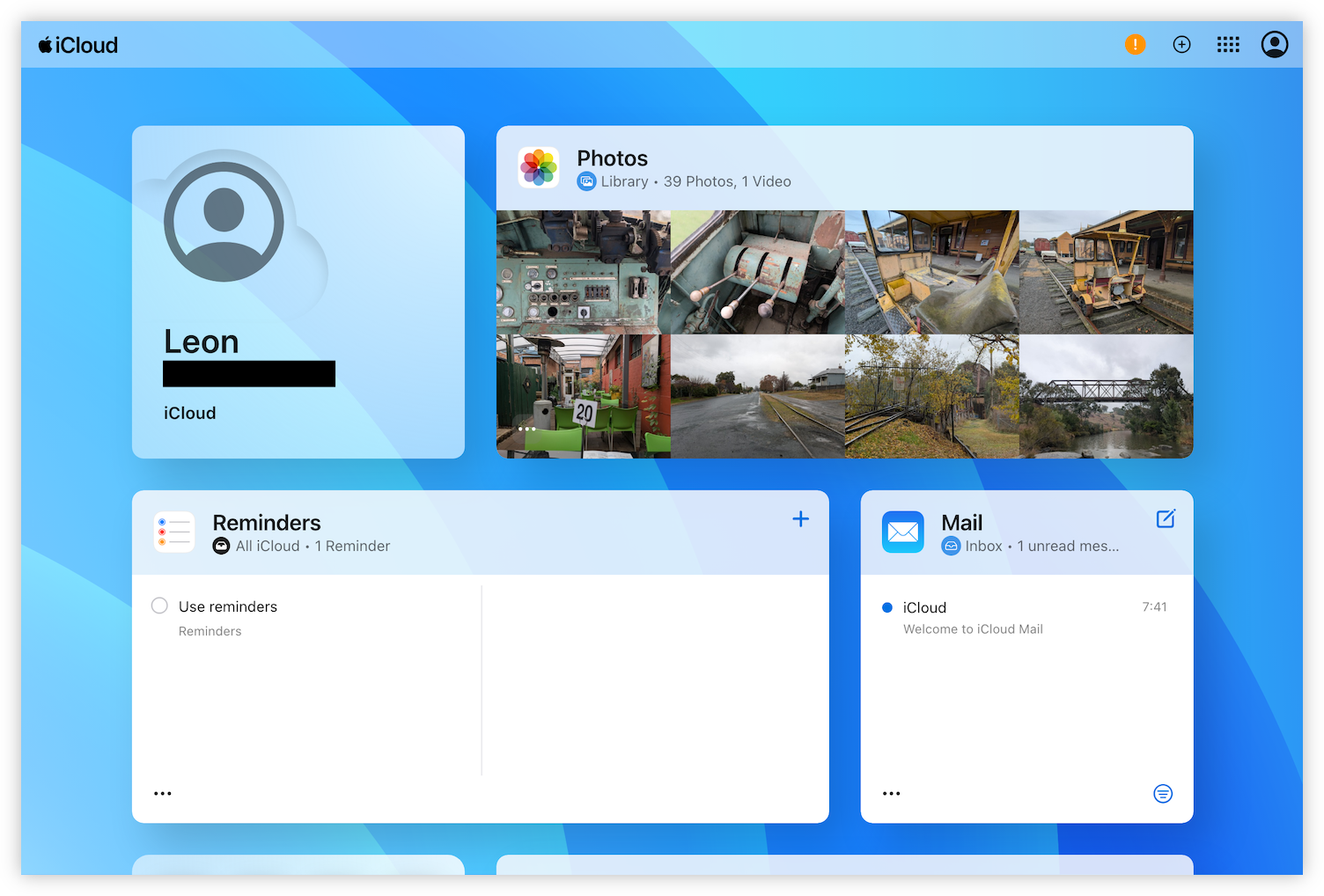
There is also a sense that it’s a little flimsy, that if you push too hard it will fall over. Can’t quite put my finger on why that is, but I think it’s all the small, thin fonts and pale colours. Just feels a little fragile.
screenshots -
Kind of wished Mail.app kept your email rules when you choose to sign out of iCloud. I did just that on my work laptop, and today I found all my rules got clobbered. Good thing I documented at least one of them, so I didn’t loose too much. But it’s still data loss, and I rather it didn’t happen.
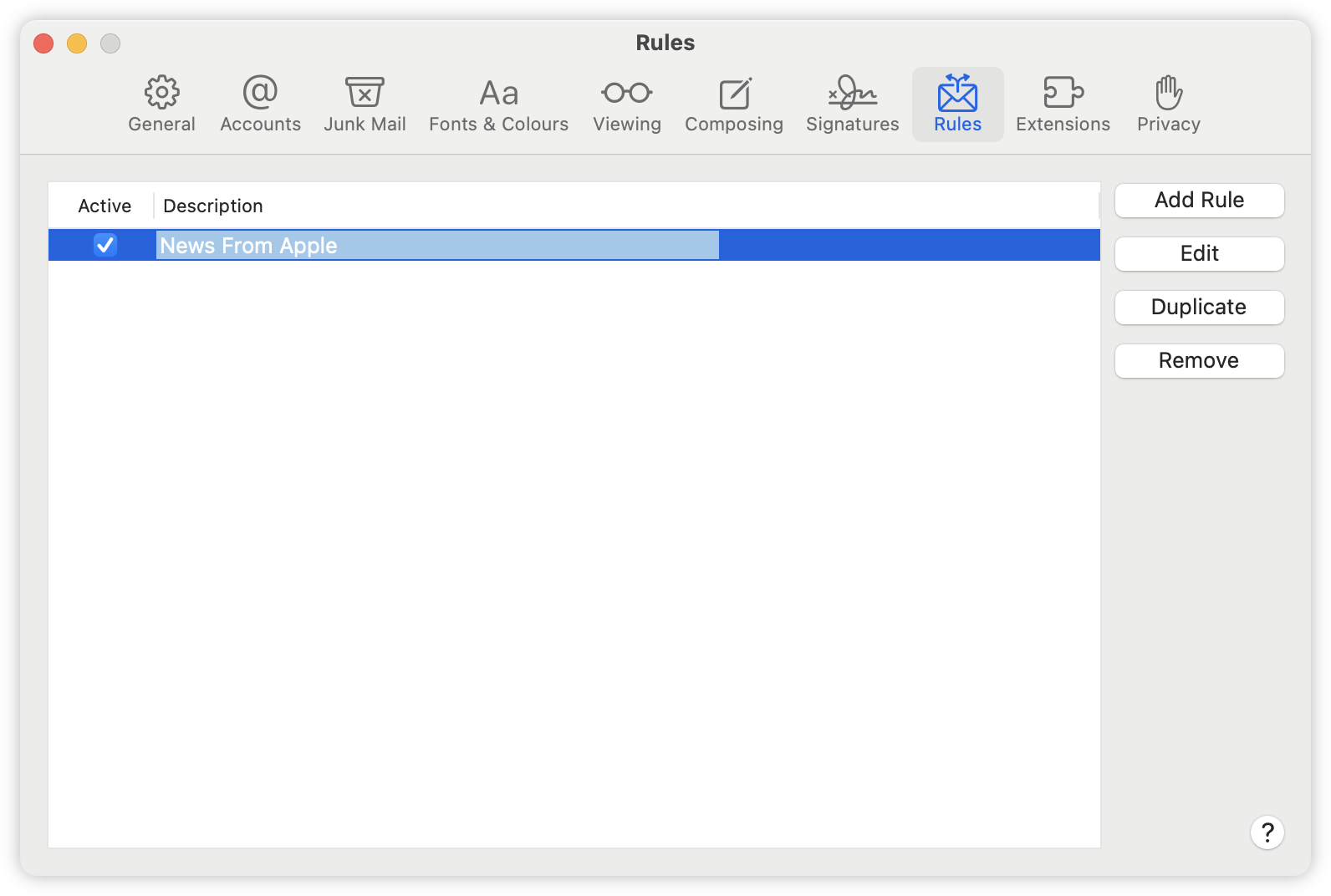 screenshots
screenshots -
It’s the simple things in life that give you joy, like the one I’m currently experiencing: being in a warm bakery on a cold morning.
-
Work email spam is so weird. Seeing emails from vendors with pitches for stuff, as if I have any decision power over anything. Maybe they’re hoping that I’ll forward it to my boss or something. Or maybe I’m just flattering myself, and they’re simply phishing attempts.
-
📘 Devlog
Blogging Tools — Category Fixer
Adding an RSS feed parser and in-app notifications to build a feature to triage image posts that don’t have a category. Continue reading →
-
I posit to you that those that complain about the state of the web haven’t actually experience the web, or not enought of it. They spend all their time in closed platforms, consuming algorithmic feeds and not making nor following links, and get turned off by the ensittification of it all. It’s like travelling overseas, spending all your time at or around the hotel, coming home, then telling others that your trip was pretty boring.
-
Don’t want to say much about Apple’s lawsuit against Jon Prosser other than that it’s not a good look.
Might be that Apple has lost all sense of optics, as evident in the string of “success” they had in their recent advertising. So let me clue them in on something: Apple, you are no longer the underdog. If I’m going to see headlines saying “Apple sues X” where X is anything other than Microsoft, Google, Meta, or the US Government, I’m just going to think that you’re throwing your weight around trying to hurt or stop someone way smaller than you.
I’m sure Apple thinks they deserve it. Might be that they do. But that’s the downside of money and power: you come off as the big guy, and it’s hard to solicit any sympathy for you if you’re going at someone smaller, no matter how justified (you think) it is.
Anyway, that’s all I’ll say about this for now.
-
It’s funny how blogging can feel like you’re writing to everyone and no-one at the same time.
-
Listening to a podcast where the guest recounted a story of a young person saying that they “watch a lot of podcasts,” and I just sighed with despondency.
Same podcast where the guest is giving book and app recommendations. Are there links to these in the show notes? Well no, but they are in a post on their Substack. Is the link to their Substack in the show notes? Well no, but their Substack is called “yada yada etc.” You can probably find a link to it by going to Twitter (by following the link that is in the show notes).
Ah, sigh. I think I’m just spoilt by those that give a damn about the podcasting medium.
-
Someone needs to teach washing machine microcontroller engineers about non-volatile memory, so they can build machines that remember the last cycle and wash options. At the very least, they could be better in selecting good defaults. “Cottons” is not a good default if “everyday” is the mode I want.
-
I keep forgetting that the written word has different expectations around contractions. I’d probably speak aloud something that sounds like “the same round here”. But I need to remember to write that as around or ‘round. Being ‘round here is different from being round here (but still applicable 😉).
-
About 9 years ago, while visiting the USA on a work trip, I went to the Elephant & Castle in Washington, DC. Someone recommended it to me, but I was frankly underwhelmed: not what you’d typically get at a pub around here. Today I learnt that it’s actually a chain of pubs, which probably explains it.
-
Just one of those weeks where nothing is working at all. Computers, transport, the gym. Probably should just write this one off and regroup next week.
-
Eyeing this course on screencasting. Might be a good skill to develop. I’ve recorded a few screencasts for work in the past and not only did I find it a good reference to share to others, it was fun to do.
Via: Chris Coyier
-
Should turn in my software development credentials right now. Thought I fixed a bug which failed QA because it didn’t work when multiple items were submitted. I didn’t test submitting multiple items, I only tested singles. Effin’ amateur hour! 🤦
-
🔗 MacSparky: A Remarkable, Unremarkable Thing
We often talk about how people can’t put their phones down while in line at the market, but what about during moments of joy? When taking in a theme park with your family, at the beach, or on vacation? Those moments are found solely in your immersion in the now.
A thought-provoking post.
links -
It’s striking how few Substack writers have setup their own domain name. Every link I see in the post I’m reading bar one is
something.substack.com. Is it just too difficult to do? I thought that service attracted those that want to go out on their own. This feels like going halfway. -
Oof! Interviewing always takes it out of me. And I’m not even the one being interviewed. 😩
-
Train line outage is still ongoing. Apparently there’s been a derailment due to pantographs getting entangled in the overhead wires. So the new rolling stock experience continues. Today’s is a brief ride in a Siemens, complete with driver pointing out landmarks of interest.
 photos
photos -
Got lucked into getting a Comeng train. Haven’t ridden one of these in years. They’re being retired so may be one of the last times I get to ride them.

 photos
photos -
Making lemonade out of the lemons that is a total outage of my train line by seeing areas of the network that are completely new to me.

 photos
photos


![Meme of the ending screen of Metroid 1, which is a pixelated character stands on a textured surface against a starry night sky, accompanied by a congratulatory and cautionary message in bold, yellow text. Message is as follows: Great!! You fulfiled [sic] your mission. It will revive peace in Slack. But, it may be invaded by the other releases. Pray for a true peace in Slack!](https://cdn.uploads.micro.blog/25293/2025/friday-release-meme.png)