
-
First Impressions of Eleventy
I tend to use Hugo whenever I need a static site. But my magpie tendencies have driven me to take a look at Eleventy, and I can definitely see the appeal.
Going through the Eleventy quick-start guide, I’m quite impressed with how easy it was to setup a bespoke layout for a single site. I’ve done similar things in a few Hugo sites and while I wouldn’t describe it as “hard”, it’s certainly more involved. Hugo’s decent, but it feels quite… engineered. That’s not necessarily a bad thing: putting together something using one of the pre-built themes is quite straightforward. But going beyond a few theme customisations involves a fair bit of work compare to Eleventy.
Continue reading → -
2023 Song of The Year
Well, believe it or not, my standing Christmas Eve Mass organ gig has come around once more1, so it’s time to decide on this year’s Song of The Year. This is the second post in this series, so please see last year’s post on what this nonsense is all about.
This year’s nominees are (not too many this year):
- Wooden Ship, from Antarctica — Suit for guitar and orchestra by Nigel Westlake.
- Penguin Ballet, from Antarctica — Suit for guitar and orchestra by Nigel Westlake. Not really a new track for me, but I’m including it here anyway as it’s been many years since I last heard it2.
And the winner is: Wooden Ship by Nigel Westlake 👏
Continue reading → -
Test Creek: A Test Story With Evergreen.ink
Had a play with Evergreen.ink this afternoon. It was pretty fun. Made myself a test story called Test Creek which you can try out (the story was written by me but all the images were done using DALL-E).
The experience was quite intuitive. I’ve yet to try out the advanced features, like the Sapling scripting engine, but the basics are really approachable for anyone not interested with any of that.
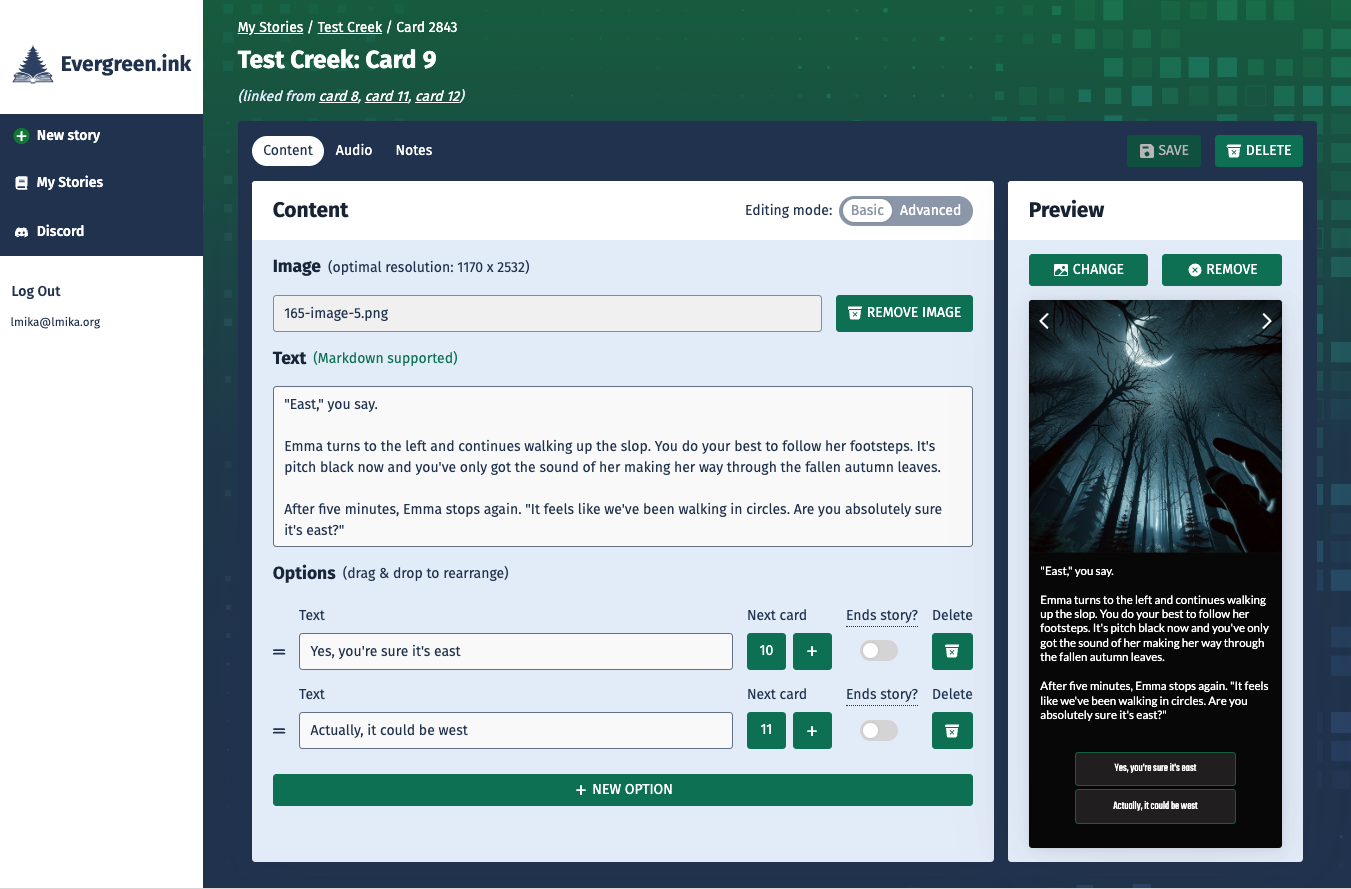
I would recommend not writing too much on a single card. Keep it to maybe two or three paragraphs. Otherwise the text will start to flow over the image, like it does on one of the cards in this story. Evergreen.ink does keep the text legible with a translucent background. But still, it’s just too much text.
Continue reading → -
Best, First, Favourite
On Reconcilable Difference #221, Merlin and John introduced the concept of “Best, First, Favourite”. For a particular category, which would you consider the best (i.e. closest to a perfect representation of that category, in however you define it), which would you recommend someone who’s interested in starting should experience first, and which one is your favourite.
I thought it was a fun idea, so I’ve put together a few of my own.
Continue reading → -
Idea For Mainboard Mayhem: A Remote Pickup
Sort of in-between projects at the moment so I’m doing a bit of light stuff on Mainboard Mayhem. I had an idea for a new element: a remote control which, when picked up, will allow the player to toggle walls and tanks using the keyboard, much like the green and blue buttons.
I used ChatGGT to come up with some artwork, and it produced something that was pretty decent.

Prompt: pixel art of a remote control with a single red button styled like the tiles found in Chips Challange, rotated 45 degrees to the right. Only issue was that the image was huge — 1024 x 1024 — and the tiles in Mainboard Mayhem were only 32 x 32.
Continue reading → -
A Few Thoughts On Using iA Presenter
Well the “big presentation” was today, the one I thought would be a good canditate for trying out iA Presenter. And after spending the last couple of weeks preparing for it, I’d thought it would be good time to give my thoughts on how it worked for me.
First, I must say that I can appreciate using an app that is opinionated. This is not a drop-in replacement for Keynote1: the app really does try and steer you towards a particular presenting style. They’re quite upfront with this: the example shown on first launch outlines how to prepare the slides and why writing out the entire presentation in full, while leaving slides as the role of accenting your points, makes for better presentation.
Continue reading → -
Resurrecting Untraveller And Finishing The RA-V Mission Posts
It’s been 10 years to the day when I had the opportunity to tour the Pacific as part of my job at the Bureau of Meteorology, the so call “RA-V Missions”. This last month or so, I’ve been writing about them in my journal, trying to get it all down before I forget. I had grand plans of publishing them on a travel blog, which I shelved a couple of months ago.
Continue reading → -
Defaults
I see that Gabz, Robb, and Manique — along with many others — have posted their defaults after listening to Hemispheric Views 097 - Duel of the Defaults!, which was a really fun episode. I thought I’d do the same.
- Mail Client: Fastmail. Web-app on the desktop and app on mobile
- Mail Server: Fastmail
- Notes: Obsidian for work. It was Obsidian for personal use but I’m trying out Notion at the moment.
- To-Do: Obsidian/Notion (todos go in as notes)
- Photo Shooting: Android camera app
- Photo Management: Google Photos
- Calendar: Google Calendar
- Cloud file storage: Google Drive
- RSS: Feedbin. I mainly read it with NetNewsWire but I also use the web-app.
- Contacts: Android contacts app.
- Browser: Safari, Vivaldi
- Chat: Mainly still use Android Messanger for SMS but started using WhatsApp more
- Bookmarks: Linkding running on Pikapods.
- Read It Later: None, but if I were to start, I’d probably try out Feedbin’s RIL service.
- Word Processing: n/a
- Spreadsheets: Google Sheets, Numbers (I don’t do a lot of spreadsheeting)
- Presentations: Keynote, but giving iA Presenter a try at the moment.
- Shopping Lists: Google Keep
- Meal Planning: n/a
- Budgeting & Personal Finance: n/a
- News: ABC1 News, in a web-browser
- Music: Alto (my own music app), Spotify
- Podcasts: Pocketcasts
- Password Management: 1Password
- Photo Editing: Google Photo
- Weather: Bureau of Meterology website.
- Social Clients: Tusky (Mastodon)
- Code Editor: GoLand (Jetbrains in general), Android Studios, or XCode
- Text Editor: Nova
- Hard Quiz Expert Subject: Probably the music of Mike Oldfield.
Scored myself based on the rules of the game and came up with 44 points. It was a little tricky as I’ve got both feet in separate ecosystems.
Continue reading → -
Why I Like Go
This question was posed to me in the Hemispheric Views Discord the other day. It’s a bit notable that I didn’t have an answer written down for this already, seeing that I do have pretty concrete reasons for why I really like Go. So I figured it was time to write them out.
I should preface this by saying that by liking Go it doesn’t mean I don’t use or like any other languages. I don’t fully understand those that need to dislike other languages like they’re football teams. “Right tool for the job” and all that. But I do have a soft-spot for Go and it tends to be my go-to language for any new projects or scripting tasks.
Continue reading → -
Work Email Spam
Opened my work email this morning and received a greeting from the following spam messages:
- Webinar to “overcome the fear of public speaking” from some HR Training mob
- A training course on “accelerating innovation in data science an ML” (there’re a few emails about AI here)
- Webinars from Stripe, Slack, and Cloudflare about how other companies are using them
- Weekly updates about what’s happening on our Confluence wiki (this probably could be useful… maybe? But our wiki is so large that most updates are about things other teams are working on)
- A training course on some legal mandates about hiring (honestly, my email must’ve appeared on some mailing list for HR professionals)
- Another webinar from the first training mob about dealing with “employees from hell”
Marked all as read, closed email, and opened Slack.
Continue reading → -
Links About Blogging
-
Pixel Phones Are Not Dog-food, and That's a Problem
John Gruber on the Pixel 8 launch event:
It’s also impossible not to comment on just how much less interest there is in Google’s Pixel ecosystem. […] On the one hand I’m tempted to say the difference is just commensurate with how much better at hardware Apple is than Google. But I think there’s more to it than that. There’s something ineffable about it. There are aspects of marketshare traction — in any market — that can’t be explained by side-by-side product comparisons alone.
Continue reading → -
Your Dev Environment is Not Your Production Environment
There will be certain things you’re going to need to do in your development environments that you should never do in production. That’s pretty much a given: playing around with user’s data or potentially doing something that will cause an incident is generally not a good idea.
But there are things you shouldn’t do in prod that you may need to do in dev. And make no mistake, there may be a legitimate need to do these things. Using Auth0 and only have a limited number of emails available for your test environment? You may need a way to quickly reset a user. Support billing in multiple countries and need to do a test in one of them? You’ll need a way to change the user’s countries.
Continue reading → -
Electrification of Melbourne Suburban Railways Plaque
Found this plaque while passing through Southern Cross station this morning.

I didn’t have time to read it, and the subject matter looks really interesting to me (Trains? Power Lines? What’s not to love? 😀). I also don’t know how long it’ll be up for, and I’ve been burned in the past of not capturing something when I had the chance.
So I’m posting photos of it here for posterity reasons. Enjoy.
Continue reading → -
Alternative Day Four Photo
I had an alternative idea for today’s photo challenge, which is “orange”. I was hoping to post a photo of something related to Melbourne’s busses.
You see, PTV has designated different colour for different modes of transport. Blue for metro trains, purple for regional trains, green for trams, and orange for busses. And from my experience using the service, they’re pretty consistent with adhering to this design language:

Anyway, they’re doing train works along my rail line over the past few weeks and this morning I noticed this sign (forgive the lighting, it was before dawn):
Continue reading → -
Mainboard Mayhem
Project update on Mainboard Mayhem, my Chip’s Challenge fan game. I didn’t get it finished in time for the release deadline, which was last weekend. I blame work for that. We’re going through a bit of a crunch at the moment, and there was a need to work on the weekend.
The good news is that there wasn’t much left to do, and after a few more evenings, I’m please to say that it’s done. The game is finish, and ready for release.
Continue reading → -
Early Version of This Blog
I was looking for something in GitHub the other day when I found the repository for the first iteration of this blog. I was curious as to how it looked and I’d thought that I’d boot it up and post a few screenshots of it.1
It started life as a Hugo site. There a two reasons for that, with the first being that I didn’t have the patients to style a website from scratch, and Hugo came with some pretty nice templates. I chose the Vienna template, which seems to have fallen out date: many of the template variables no longer work with a modern version of Hugo. I’m also please to see that I did end up customising the header image — a photo taken in Macedon of the train line to Bendigo — although that’s pretty much all I customised.
Continue reading → -
On Tools and Automation
The thing about building tools to automate your work is that it’s hard to justify doing so when you’re in the thick of it. Easy to see all the time you save in the aggregate, but when you’re faced with the task in your day to day, you’re just as likely to say “I can build a tool which will let me do this task in a couple of seconds, but it’ll take me an hour to build it verses the 5 minutes it’ll take for me to just do the task.”
Continue reading → -
🔗 XML is the future - Bite code!
I wanted to write something about fads in the software development industry when the post about Amazon Prime Video moving away from micro-services back to monoliths was making the rounds. A lot of the motivation towards micro-services can be traced back to Amazon’s preaching about them being the best way to architect scalable software. Having a team from Amazon saying “micro-services didn’t work; we went back to a monolith and it was more scalable and cheaper to run” is, frankly, a bit like the Pope renouncing his Catholic faith.
I didn’t say anything at the time as doing so seemed like jumping on the fad wagon along with everyone else, but I have to agree with this article that this following along with the crowd is quite pervasive in the circuits I travel in. I did witness the tail end of the XML fad when I first started working. My first job had all the good stuff: XML for data and configuration, XSLT to render HTML and to ingest HL71, XForms for customisable forms. We may have used XSD somewhere as well. Good thing we stopped short of SOAP.
The whole feeling that XML was the answer to any problem was quite pervasive, and with only a few evangelists, it was enough to drive the team in a particular direction. And I wish I could say that I was above it all, but that would be a lie. I drank the cool-aid like many others about the virtues of XML.
But here lies the seductive thing about these technology fads: they’re not without their merits. There were cases where XML was the answer, just like there are cases where micro-services are. The trap is assuming that just because it worked before, it would work again, 100% of the time in fact, even if the problem is different. After all, Amazon or whatever is using it, and they’re successful. And you do want to see this project succeed, right? Especially when we’re pouring all this money into it and your job is on the line, hmm?
Thus, teams are using micro-services, Kubernetes, 50 different middleware and sidecar containers, and pages and pages of configuration to build a service where the total amount of data can be loaded into an SQLite3 database2. And so it goes.
So we’ll see what would come of it all. I hope there is a move away from micro-services back to simpler forms of software designs; one where the architecture can fit entirely in one’s head. Of course, just as this article says, they’ll probably be an overcorrection, and a whole set of new problems arise when micro-services are ditched in favour of monoliths. I only hope that, should teams decide to do this, they do so with both eyes open and avoid the pitfalls these fads can lay for them.
-
Code First, Tests After
Still doing the code first, tests after at work and I’m really starting to see the benefits from it. Test driven development is fine, but most of our recent issues — excess logging or errors that are false positives — have nothing to do with buggy business logic. It’s true that you can catch these in unit tests (although I find them to be the worst possible tests to write) but I think you gain a lot more just from launching the application and seeing it run.
Continue reading → -
On The Reddit Strike
Ben Thompson has been writing about the Reddit strike in his daily updates. I like this excerpt from the one he wrote yesterday:
Reddit is miffed that Google and OpenAI are taking its data, but Huffman and team didn’t create that data: Reddit’s users did, under the watchful eyes of Reddit’s unpaid mod workforce. In other words, my strong suspicion is that what undergirds everything that is happening this week is widespread angst and irritation that everything that was supposed to be special about the web, particularly the bit where it gives everyone a voice, has turned out to be nothing more than grist to be fought over by millionaires and billionaires.
Continue reading → -
Truthful Travel Talk
It’s time to be honest: I think overseas travel is wasted on me.
We were driving down from Antibes to Genova today. It was a nice trip, complete with picturesque towns passing us by as we drove along the motorway. My friend was oohing and ahhing at each one: remaking about how nice it would be to see them, stay in them for a while. He was also remarking on what we would do when we arrived at our destination. There was just this air of enthusiasm about the whole thing.
Continue reading → -
Where Have I Been
-
Full Width Notes In Obsidian
More custom styling of Obsidian today. This snippet turns off fixed-width display of notes, so that they can span the entire window. Useful if you’re dealing with a bunch of wide tables, as I am right now.
body { --file-line-width: 100%; } div.cm-sizer { margin-left: 0 !important; margin-right: 0 !important; }I wish I could say credit goes to ChatGPT, but the answer it gave wasn’t completely correct (although it was close). The way I got this was by enabling the developer tools — which you can do from the View menu — and just going through the HTML DOM to find the relevant CSS class. I guess this means that this’ll break the minute Obsidian decides to change their class names, but I guess we’ll cross that bridge when we come to it.
Continue reading → -
F5 To Run
While going through my archive about a month ago, I found all my old Basic programs I wrote when I was going through school. I had a lot of fun working on them back in the day, and I though it would be nice to preserve them in some way. Maybe even make them runnable in the browser, much like what the Wayback Machine did with the more well-known DOS programs.
Continue reading →