
-
📘 Devlog
Other Project Updates
A few updates of some other projects I worked on recently.
Webtools saw some love as I needed some tooling made to make the icon easy to include in the Well Read Flutter project itself. Android expects the logo of a specific size, so I “commissioned” an Android Icon Resizer, which will take one or more PNG files, resize them to what Android expects, and prepare them in a ZIP that could be extracted at the route of the
Continue reading →res/mipmapdirectory. It will also produce a small preview of the icon, rendering it in a circle so you can see how it looks on the device. It’s background savvy, layering the icon over the PNG with “background” in the filename. -
Over the weekend, curious to know how well it’ll do, I asked ChatGPT to generate some code in UCL, the toy language I sometimes write about here. I asked it to product a script that would print out the Fibonacci sequence up to a given value. It didn’t do too well, producing a script which looked like a strange hybrid between TCL and shell.
This was somewhat expected. What wasn’t expected was to see UCL pop up as a topic within Pulse the next day:
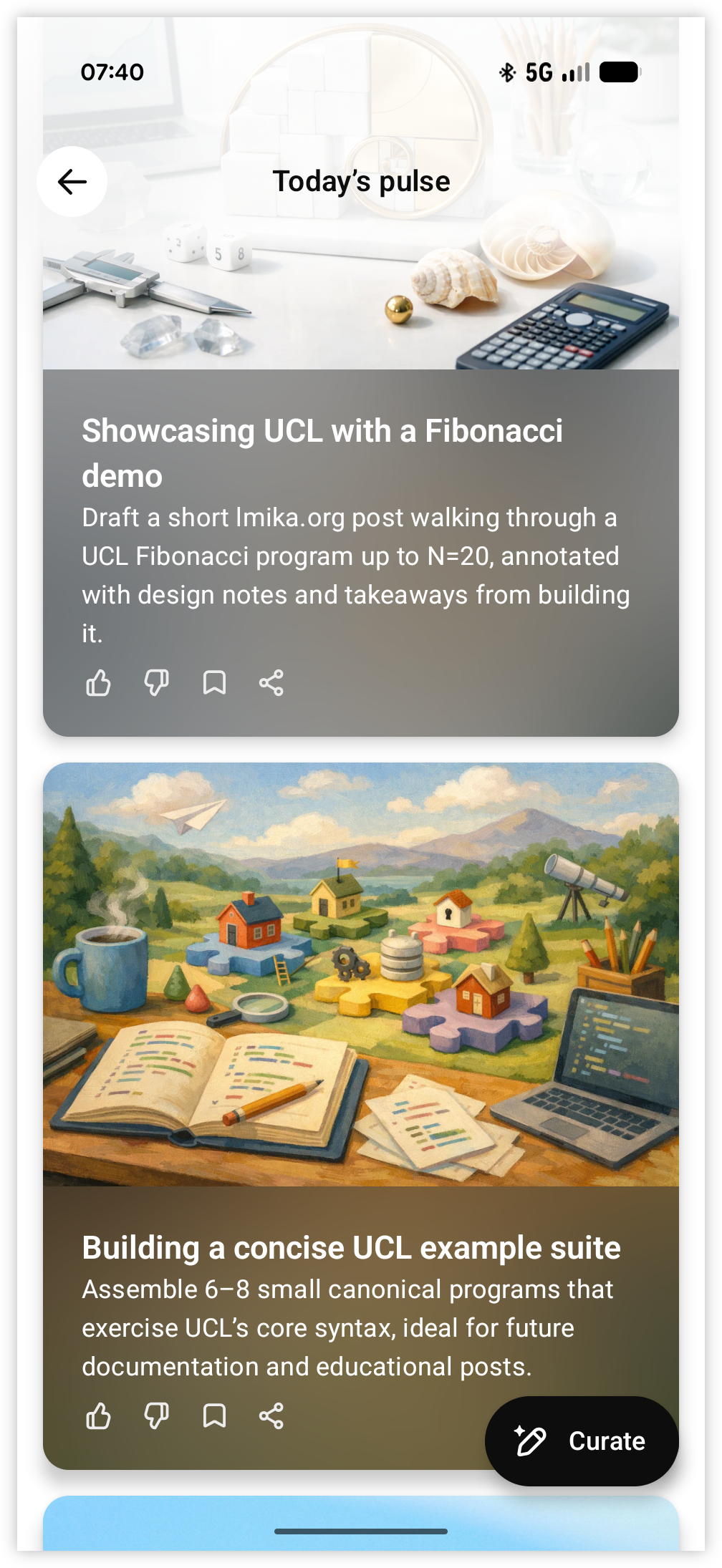
Very amusing.
-
Was not expecting to spend yesterday morning working on Dequoter, my Boop clone. Opened it up to do some light work and when I looked up, a couple of hours have passed. Added a few more processors to deal with lines, such as splitting and joining on commas. Added a status bar for processes that return information rather than filter text, such as returning a line count.
Also integrated UCL, because of course I did. Added two commands: a
UCL: Evaluatewhich executes the input as a UCL script and displays the response in the status bar, and aUCL: Replacewhich replaces the UCL script with it’s output. This makes it possible to generate text from scripts, like a bunch of lines to test out the line count processor:map (seq 20) { |n| "Line $n" } | strs:join "\n"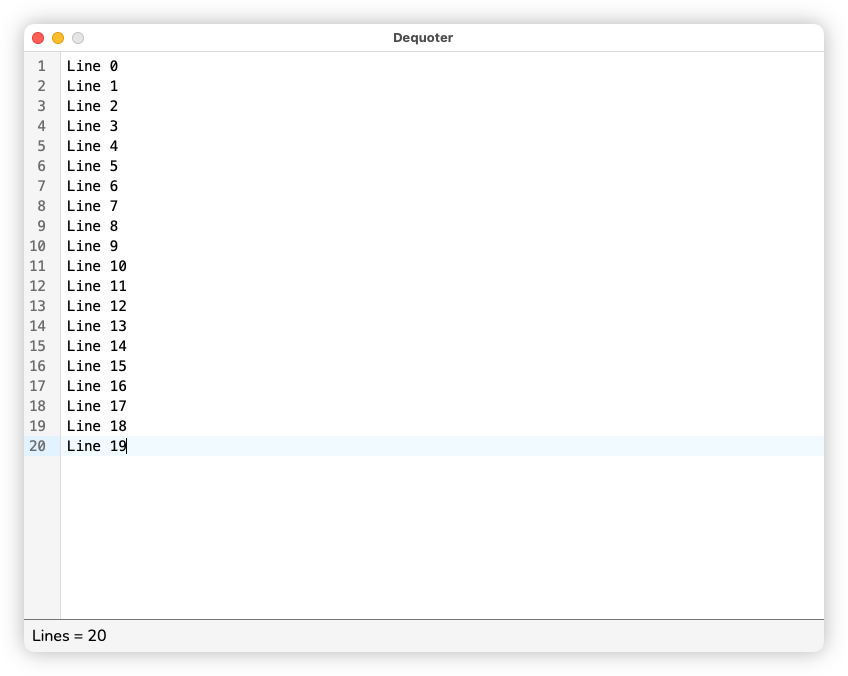
It’ll also make for a useful scratchpad for testing out some UCL commands.
-
📘 Devlog
Dynamo Browse - Item View Annotations and Asynchronous Tasks
Adding to the UCL extension support in Dynamo Browse the ability to annotate displayed result items, plus scheduling tasks that will be executed in the background. Continue reading →
-
📘 Devlog
UCL - Adding Some Missing Library Functions
-
It’s funny how I approach certain features in the tools I make, such as adding UCL to Dynamo Browse. It’s been several months since I’ve done this, and I haven’t really used it for anything substantial until today. I guess because I get the sense that it’s half-finished (mainly due to the fact that it is half-finished) I tend to approach such features gingerly: in a careful way so as to avoid any problems. That’s probably not the best way to approach these features though. They need to be taken through the ringer, and just used, lest I never find their limitations or bugs that need to be fixed.
Anyway, this is a long winded way of saying that I’m glad I actually replaced the old scripting engine in Dynamo Browse with UCL. It was added to be used, and it actually came in useful today.
-
📘 Devlog
UCL — Comparing UCL To Some Early Ideas
Comparing UCL to an idea for a hypothetical command language for a now-defunct CLI project, which aimed to combine shell-like REPL functionality with scripting capabilities. Continue reading →
-
📘 Devlog
UCL — More About The Set Operator
I made a decision around the set operator in UCL this morning.
When I added the set operator, I made it such that when setting variables, you had to include the leading dollar sign:
$a = 123The reason for this was that the set operator was also to be used for setting pseudo-variables, which had a different prefix character.
@ans = "this"I needed the user to include the
Continue reading →@prefix to distinguish the two, and since one variable type required a prefix, it made sense to require it for the other. -
📘 Devlog
Dynamo-Browse Now Scanning For UCL Extensions
Significant milestone in integrating UCL with Dynamo-Browse, as UCL extensions are now being loaded on launch. Continue reading →
-
All the recent changes to UCL is in service of unifying the scripting within Dynamo Browse. Right now there are two scripting languages: one for the commands entered after pressing
:, and one for extensions. I want to replace both of them with UCL, which will power both interactive commands, and extensions.Most of the commands used within the in-app REPL loop has been implemented in UCL. I’m now in the process of building out the UCL extension support, start with functions for working with result sets, and pseudo-variables for modifying elements of the UI.
Here’s a demo of what I’ve got so far. This shows the user’s ability to control the current result-set, and the selected item programatically. Even after these early changes, I’m already seeing much better support for doing such things than what was there before.
-
📘 Devlog
UCL — Assignment
Some thoughts of changing how assignments work in UCL to support subscripts and pseudo-variables. Continue reading →
-
One of the tools I built for work is starting to get more users, so I probably should remove UCL and replace it with a “real” command language. That’s the risk of building something for yourself: if it’s useful, others will want to use it.
I will miss using UCL, if I do have to remove it. Integrating another command language like TCL or Lisp is not easy, mainly because it’s difficult to map my domain to what the language supports. Other languages, like Lua or Python, map more nicely, but they’re awful to use as a command language. Sure, they may have REPLs, but dealing with the syntax is not fun when you’re just trying to get something done. That’s why I built UCL: to be useable in a REPL, yet rich enough to operate over structured data in a not-crappy way (it may not be glamorous, but it should be doing), while easy to integrate within a Go application.
Of course, if I want to continue to use it, it needs some effort put into it, such as documentation. So which one do I want more?
-
Have technically secured user no. 2 of UCL today, after sharing one of the tools that’s using the language with them at work. It’s just a shame that the docs are so far behind (read: not existent). All I really have are these blog posts about building it. Good thing he’s a reader 😛. (Hi, KK).
-
Moving all my project posts onto a separate blog… again. I tried writing them here, but I still feel like they belong elsewhere, where I have a bit more control over the layout and the design. Spent the morning configuring the theme, which was going to be orange but I had to change it to red as the orange didn’t provide a nice contrast for reading (you had to darken it almost to brown). I’m not sure if I’ll move the old posts over to it yet. Maybe the one’s on UCL.
Update on 14/2: No, changed my mind again. See this post.
-
UCL: Some Updates
Made a few minor changes to UCL. Well, actually, I made one large change. I’ve renamed the
foreachbuiltin tofor.I was originally planning to have a
Continue reading →forloop that worked much like other languages: you have a variable, a start value, and an end value, and you’d just iterate over the loop until you reach the end. I don’t know how this would’ve looked, but I imagined something like this: -
Idea for UCL: Methods
I’m toying with the idea of adding methods to UCL. This will be similar to the methods that exist in Lua, in that they’re essentially functions that pass in the receiver as the first argument, although methods would only be definable by the native layer for the first version.
Much like Lua though, methods would be invokable using the
:“pair” operator.strs:to-upper "Hello" --> HELLOThe idea is to make some of these methods on the types themselves, allowing their use on literals and the result of pipelines, as well as variables:
Continue reading → -
UCL: Iterators
Still working on UCL in my spare time, mainly filling out the standard library a little, like adding utility functions for lists and CSV files. Largest change made recently was the adding iterators to the mix of core types. These worked a lot like the streams of old, where you had a potentially unbounded source of values that could only be consumed one at a time. The difference with streams is that there is not magic to this: iterators work like any other type, so they could be stored in variables, passed around methods, etc (streams could only be consumed via pipes).
Continue reading → -
Started filling out the UCL website, mainly by documenting the core modules. It might be a little unnecessary to have a full website for this, given that the only person who’ll get any use from it right now will be myself. But who knows how useful it could be in the future? If nothing else, it’s a showcase on what I’ve been working on for this project.
-
I’ve been using UCL a lot recently, which is driving additional development on it. Spent a fair bit of time this evening fixing bugs and adding small features like string interpolation. Fix a number of grammar bugs too, that only popped up when I started writing multi-line scripts with it.
-
I plan to integrate UCL into another tool at work, so I spent last night improving it’s use as a REPL. Added support for onboard help and setting up custom type printing, which is useful for displaying tables of data. I started working on the tool today and it’s already feeling great.
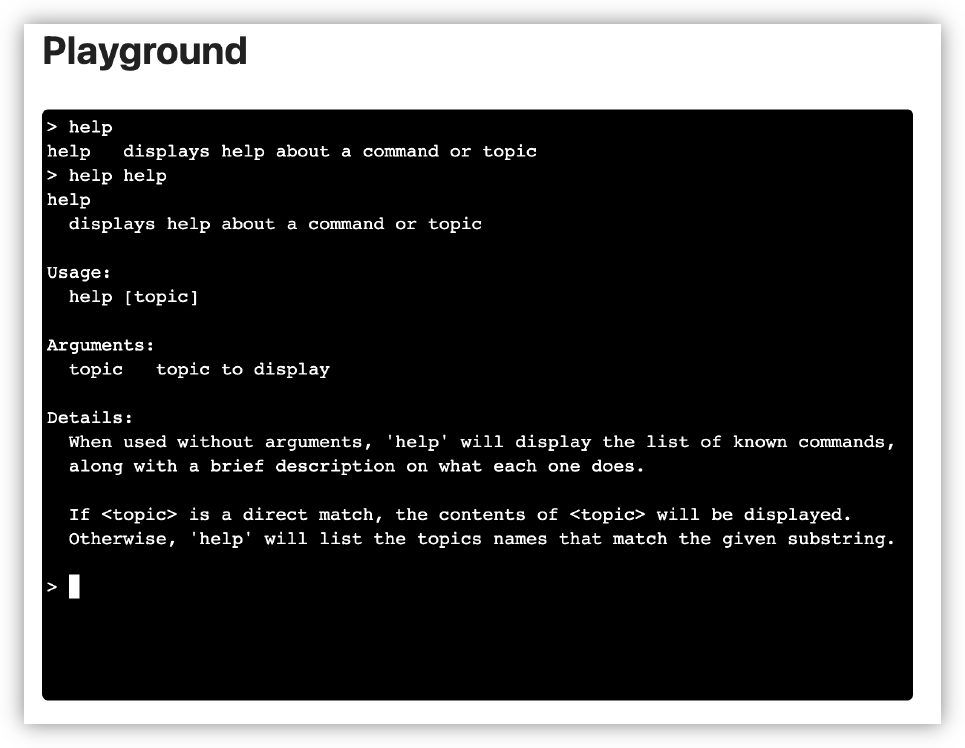
-
Weekly Update - 3 Nov 2024
I probably should stop calling these “weekly updates,” seeing that they come up a lot less frequently than once a week. Maybe I should switch to something like “Sunday updates,” or maybe something closer to what this is, which is an excuse to procrastinate by writing about what I’ve been working on, rather than just working on it.
But I’m sure you’re not interested in my willowing about the frequency of these updates, so let’s just get straight to the meat of it.
Continue reading → -
Try-Catch In UCL - Some Notes
Stared working on a
trycommand to UCL, which can be used to trap errors that occur within a block. This is very much inspired by try-blocks in Java and Python, where the main block will run, and if any error occurs, it will fall through to the catch block:try { echo "Something bad can happen here" } catch { echo "It's all right. I'll run next" }This is all I’ve got working at the moment, but I want to quickly write some notes on how I’d like this to work, lest I forget it later.
Continue reading → -
Project Updates
Well, it’s been three weeks since my last post here, and as hard as it was to write this update, not writing it would’ve been harder. So let’s just skip the preamble and go straight to the update.
Cyber Burger (That Pico-8 Game)
I’m terrible at being coy, I’ll just spill the beens. That game I’ve been working on is call Cyber Burger. It’s based on a DOS game I saw on YouTube, and it seemed like a fun project to try and work on, with some tweaks to the gameplay that I think would make it more forgiving.
Continue reading → -
Indexing In UCL
I’ve been thinking a little about how to support indexing in UCL, as in getting elements from a list or keyed values from a map. There already exists an
indexbuiltin that does this, but I’m wondering if this can be, or even should be, supported in the language itself.I’ve reserved
Continue reading →.for this, and it’ll be relatively easy to make use of it to get map fields. But I do have some concerns with supporting list element dereferencing using square brackets. The big one being that if I were to use square brackets the same way that many other languages do, I suspect (although I haven’t confirmed) that it could lead to the parser treating them as two separate list literals. This is because the scanner ignores whitespace, and there’s no other syntactic indicators to separate arguments to proc calls, like commas: -
Tape Playback Site
Thought I’d take a little break from UCL today.
Mum found a collection of old cassette tapes of us when we were kids, making and recording songs and radio shows. I’ve been digitising them over the last few weeks, and today the first recorded cassette was ready to share with the family.
I suppose I could’ve just given them raw MP3 files, but I wanted to record each cassette as two large files — one per side — so as to not loose much of the various crackles and clatters made when the tape recorder was stopped and started. But I did want to catalogue the more interesting points in the recording, and it would’ve been a bit “meh” simply giving them to others as one long list of timestamps (simulating the rewind/fast-forward seeking action would’ve been a step too far).
Continue reading →