
-
I wonder if the prudent course of action for iOS app developers is to hold off from releasing their redesigns on day one. I wonder if iOS’s new look will be overwhelming for users and having an app that’s unchanged for a week or a month could provide them with something familiar to them. 🤷
videos podcast-clips -
Wow, Slack just crashed. Haven’t experienced that in a while. At least it kept the draft I was writing so I didn’t loose anything.
-
The thing about testing, at least in my experience, is that the total time actually spent testing the logic is probably around 20%. The other 80% is setup, finding test data, fixing unrelated things, discovering other bugs blocking you, etc. It’s just a slog through one problem after another.
-
Today’s the day that I listen to the linter say “you know, you could improve your code here” instead of telling it be quiet with
nolintcomments. -
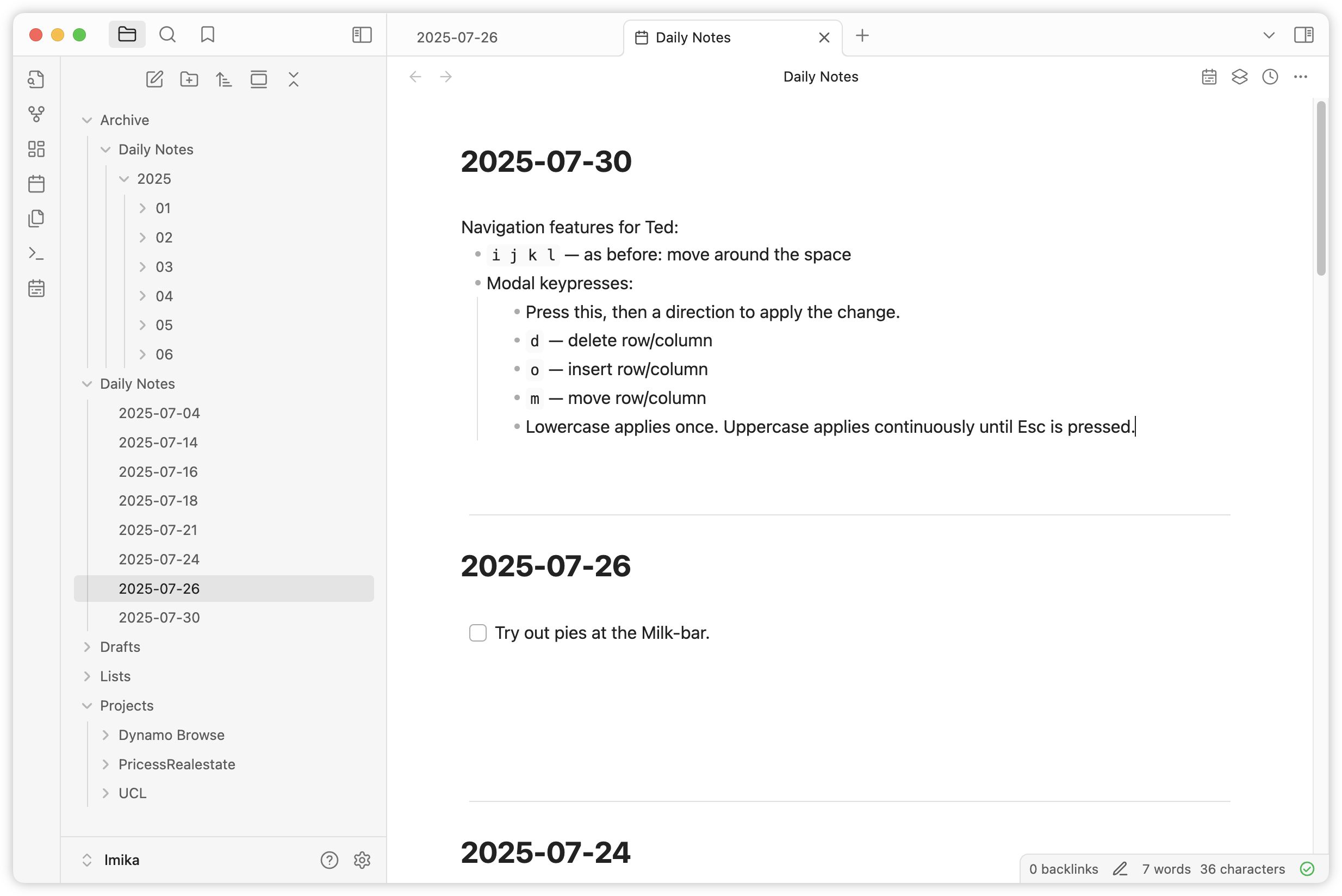
🛠️ Obsidian Plugin: Daily Notes Editor
Displays all your daily notes in a single editor tab, much like Roam Research. This was a feature I liked about Roam, and when I first looked at Obsidian, I wish it had it. Trying it out on my personal vault, where the daily notes tend to be quite small.
 screenshots tools
screenshots tools -
Yes, I am going to spend 30 minutes obsessing over what information log messages have. It’ll save me the 4 hours I spent trying to get this information next time I need it, because past me didn’t obsess over these log messages enough.
-
🔗 Daring Fireball: Microsoft Introduces ‘Copilot Mode’ in Edge
Some follow-up from my recent pondering about chatbots in browsers. From Gruber:
I think something similar is behind Microsoft trying to make Copilot front-and-center in Edge, and Google’s concurrent move to junk up Chrome with AI-generated suggestions. Their goal is to make their web browsers chatbots faster than OpenAI can make ChatGPT a web browser.
Okay, that’s plausible. If it’s just a fight for mindshare than I can understand this. Still not sure what OpenAI’s motivations are, but it does look like these other companies are just reacting here.
links -
🔗 Daring Fireball: Google Chrome Adds AI-Generated Store Summaries
Now browsers themselves will be adding their own layers of distracting cruft atop the websites. The entire premise of Chrome — the reason for its name — is that it was originally designed to simplify the UI of the browser app itself, the “chrome”, at a time when Internet Explorer and even Firefox were increasingly cluttered and confusing.
I’m confused as to why Google and all these AI companies are so gun-ho about adding AI agents to browsers. What do they get out of this deal? Is it just a way for them to win users and get data from their browsing habits? Is it protection against Google potentially dissuading these users away from using their chat-bots? These are not problems Google has, so why are they doing this?
They seem like features designed to turn the dial up on Google’s slice of commissions from web transactions.
Maybe, but how can they collect? If they run AI over the web-pages that a user visits, when the user converts, how are they going to tell the website owner that they help “bring in the eye-balls” thanks to AI and have earned X% off the top? Maybe they’ll only run these AI agents on sites that “opt-in” in some way, either by using Google Pay or paying more for Google ads. I can see that happening.
All very strange. In either case, I’m glad I’m rocking Vivaldi these days.
links -
Barely took me a week to realise that weekly notes in Obsidian is not for me. Thought I could use them to track week-long TODO list. But after a busy day yesterday, the note was already long enough that scrolling to the top to add a TODO was a bit much. These daily notes get quite large apparently.
-
I’ve changed my mind about relative date-stamps in software listings. I no longer like them, even when the event is recent. No more “3m ago” or “7h ago” (and definitely no “3 months ago” which tells me nothing). Just give me an absolute date and time, please.
-
The trouble with Holmes’ axiom is that it’s in direct opposition to Occam’s razor, which tends to be the answer more often than not. So one is likely to come to the improbable cause of an issue last, once all the simple causes have been tried and rejected. That’s probably the right way to do things, but it does slow things down in cases where time may be of the essence.
In other words, the only way to get to the improbable is by eliminating all that is likely yet impossible. There are no shortcuts.
-
Sherlock Holmes would’ve been an amazing developer:
When you have eliminated all which is impossible, then whatever remains, however improbable, must be the truth.
-
I suspect half the reason developers like to complicate things is to just talk about them. Overhearing two colleagues right now talk about React, Next.JS, and how they’re managing state in their personal projects. As someone with no interest in React, it’s hardly a boast of my abilities to walk over there and say, “well the last project I worked on uses HTML and a bit of vanilla JavaScript.”
-
Passed by some purple swamphens (or pūkekos for those across the Ditch) on my walk today. About three of them went by going the other way, just going about their business. Such interesting birds.

 photos
photos -
Some First Impressions of iPadOS 26 Public Beta
Thoughts on Liquid Glass and Safari after 30 minutes of use. Continue reading →
-
📘 Devlog
Godot Project — Level 4-2 And Level 2-3
Progress has been made on level 4-2, and early development on level 2-3, alongside new game elements. Continue reading →
-
Just for the record, I’m not going to stop using em dashes just because LLMs use them too. But to prove my authenticity, I’ll occasionally use ’em dashes incorrectly - like this. Hopefully this is enough evidence of my human—typed—this bona fides.
More proof that a human typed this: miss-spellings, mixing of tenses, and the fact that I used “proved” in two consecutive sentence in an earlier revision (not to mention using it again in this reply).
-
Got confirmation that I’ve been admitted into a very exclusive group: the cafe regulars Heidi recognises. Fellow members include a few other regulars, the cafe staff, and the lady who runs the milk-bar next door. Initiation involves getting one’s leg sniffed upon entry of Heidi.
 photos
photos -
🔗 Manuel Moreale: Why this matters
Manuel Moreale celebrates and reflects on reaching the 100th People and Blogs. Congratulations, Manuel! Here’s to many more.
We’re entering the 3 digits era of People and Blogs, and the next milestone is going to be the beginning of the 4 digits era, which will arrive in the year 2042. […] I’m not even sure if blogs will still be a thing by then.
Oh, I bet you they will be a thing.
links -
Really glad that I organised some work about 6 months ago that, at the time, seemed like an extravagance. It really came in handy today, and significantly cut down the time and effort it took to finish my task. We’re talking about savings of a couple of weeks, based on how long it took back then.
-
If you asked me today, I’d probably call this game “rock paper scissors,” most likely due to my consumption of American media. But growing up, I do remember calling this game “paper scissors rock.”
videos podcast-clips -
Watched this excellent video by Taitset about the train derailment that happened last week. Quite informative on what happened, the extent of the damage, recovery, and what could’ve caused it.
-
Was eying migrating my journal away from a bespoke app to Memos yesterday. Slept on it and decided it’s probably not worth the hassle, at least for now. But for anyone else interested in self-hosting your notes, there’s much to like about this little web-app.
-
Had to troubleshoot an issue where images weren’t being updated properly when changed. You can probably guess what the underlying cause was.
 memes
memes