
-
I’m guessing the product owners of YouTube’s Android app assumes that people will be opening links to videos from social apps, where there’s a link preview. Tapping a link now opens the YouTube video in full screen mode. I rarely have a link preview available to me, so this feature is quite jarring.
-
Started filling out the UCL website, mainly by documenting the core modules. It might be a little unnecessary to have a full website for this, given that the only person who’ll get any use from it right now will be myself. But who knows how useful it could be in the future? If nothing else, it’s a showcase on what I’ve been working on for this project.
-
I’m pretty happy with my success at using Obsidian for my work notes, and I think a key to this is adding Obsidian as a launch item, so that it’s open at log in. I’m doing likewise for my non-work vault to see if it helps with my personal notes. “Out of sight, out of mind” is a real phenomenon.
-
I don’t know what’s worse: overhearing others in cafés talk about local politics, or overhearing others in cafés talk about US politics. Surely there are more interesting topics to talk about than politics.
-
🔗 We Don’t Need More Cynics. We Need More Builders.
Liked this piece by Joan Westenberg. I occasionally see this cynicism myself, which is frustrating as they usually come from builders. Surely they know how hard it is to come up with a solution to a problem, only have it torn down. Granted, there might be some ego involved in these feelings.
Via Pixel Envy.
links -
The whole “squeaky wheel gets the oil” approach to software companies is that it’s easy for those working on a project to get a warped sense on how it’s received. A majory of users may find what you’re building usable, maybe even good, yet all you hear are the problems and shortfalls.
-
I wish I was the type of person that can use physical notebooks. That’s said, I’m going to try Obsidian for my personal notes again. I realised I don’t use the fancy features that Notion offers, and I think I prefer making straight markdown notes most of the time.
-
🛠️ Lottielabs: Browser-based tool for making key-frame animations.
Signed up to this after watching Matt Birchler’s video about it. This is a small tool for making key-frame animation (motion graphics) from within the browser. Had an idea for an animated seven-segment display countdown, which I had a go making as a GIF. It was pretty easy to make, and came out pretty well, although not exactly how I imagined it.

-
My Micro.blog mug by @jimmitchell has arrived. Looks great. As for where it fits in my ever expanding tech-related mug collection, if we were to order by size, it sits nicely in the middle.

 photos
photos -
How is a .lol or .fun domain more expensive than a .com domain? Is there some discount for being serious I’m not aware of? 🤨
-
🔗 100 quotes that helped me write
Wish I could remember where I saw this so I can give them a HT. But there are some excellent quote here in this list prepared by Austin Kleon.
links -
Started rewatching Andor last night. Wow, it’s such a great series.
-
Saw my headphone doppelgänger on the train this morning. In a world where pretty much everyone else is wearing AirPods, it was unexpected to see another wear black JBL E45BT Bluetooth headphones.
-
I’ve been using UCL a lot recently, which is driving additional development on it. Spent a fair bit of time this evening fixing bugs and adding small features like string interpolation. Fix a number of grammar bugs too, that only popped up when I started writing multi-line scripts with it.
-
It’s said that “short cuts make long delays”. The beauty of software is that you get to experience those delays over and over again. 😏
-
Like the Australian Open. Not because of the tennis, but because for two weeks, the tram I take home is rerouted to go directly to Southern Cross station, saving me from making a large road crossing. A very small improvement to my day.
-
Oof, my Python skills have atrophied quite badly. I’m trying to write a script and I’m forgetting fundamental things like how to interpolate variables within strings, or which standard library packages are used to do what. It’s not like I can’t look this stuff up, but it’s really slowing me down.
-
On Slash Pages Verses Blog Posts
Interesting discussion on ShopTalk about slash pages and whether blog posts may make more sense for some of them. Chris and Dave makes the point that blog posts have the advantage of syndicating updates, something that static pages lack on most CMSs. It’s a good point, and a tension I feel occasionally. Not so much on this site, but there’ve been several attempts where I tried to make a site for technical knowledge, only to wonder whether a blog or a wiki makes more sense. I’d like the pages to be evergreen yet I also like to syndicate updates when I learn new stuff.
Continue reading → -
One crummy thing about the move to SPAs is that website’s no longer expose query URLs. I wanted to add a Raycast quick link to search for a 2-letter country code, but ISO’s search uses AJAX or something, and there’s no way to run a search directly from a URL. Or at least I didn’t see one.
-
Oh dear. I’m eying a domain that’s priced at $370.00 /year. Not sure the revenue from my idea — currently estimated to be $0.00 /year — will cover that cost. I think there’s a business word for such discrepancies. 😬
-
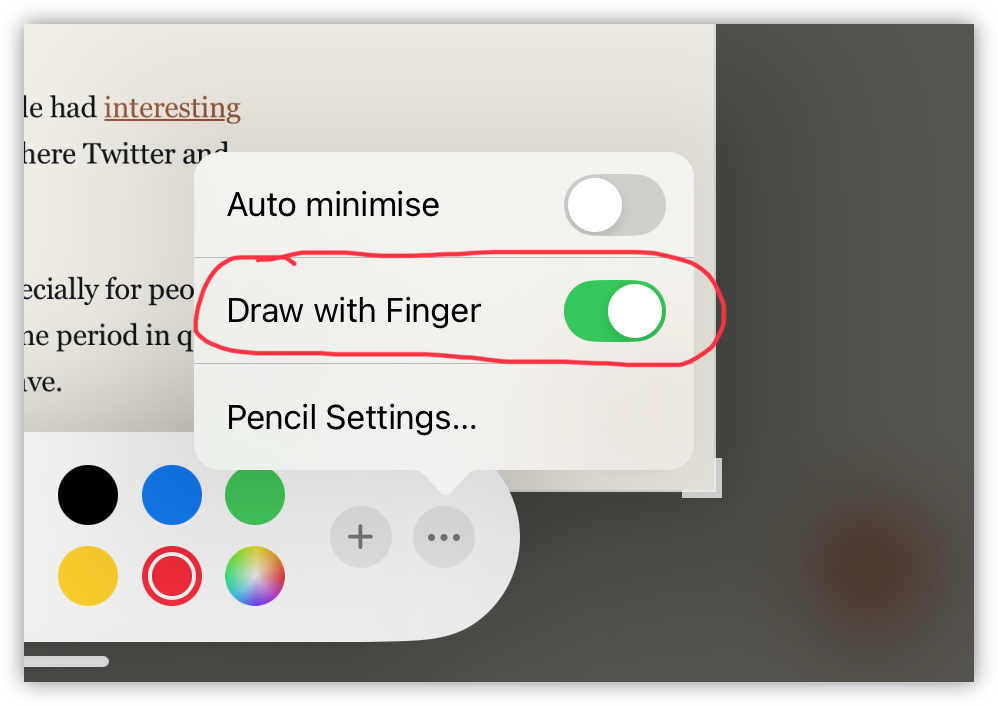
I only just discovered that you can use your finger to annotate screenshots in iPadOS. Go to the options menu and turn on “Draw with Finger”. I actually had no idea it was possible to make annotations without using a pencil. Why this is off by default when there’s no pencil nearby is beyond me.
 photos
photos -
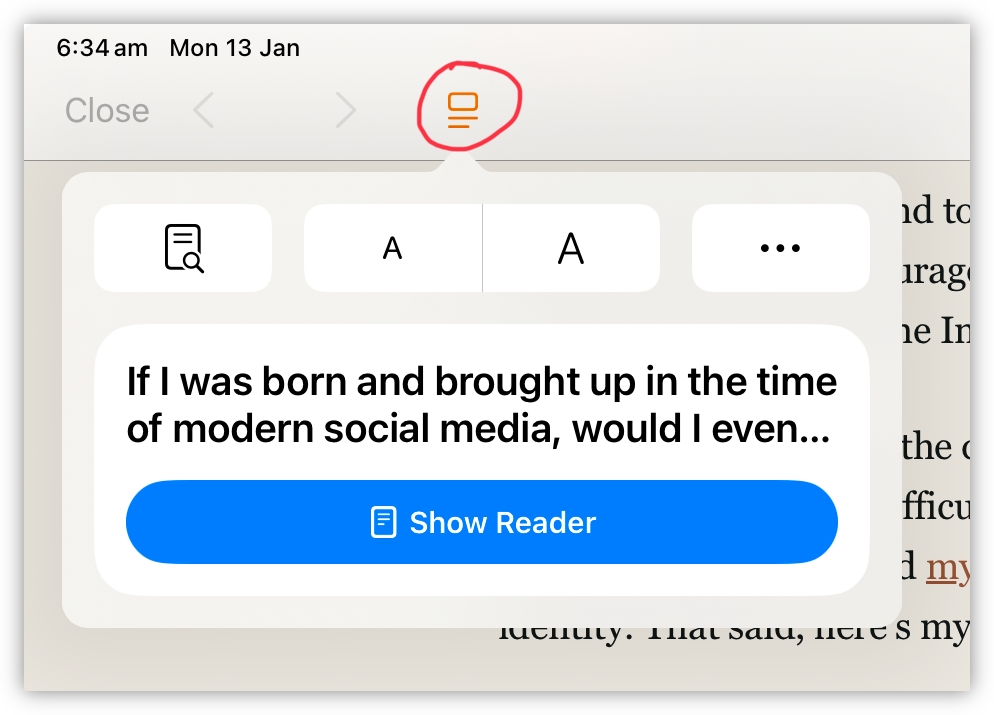
I kinda feel for UI designers. If you were asked to come up with a menu icon for showing reading mode, font size settings, and accessing the page menu with other miscellanea, which gliph would you use? I’d say that the one chosen for Safari is a little confusing, but I really cannot blame them.
 photos
photos -
Project Update: DSL Formats For Interactive Fiction
Still bouncing around things to work on at the moment. Most of the little features have been addressed, and I have little need to add anything pressing for the things I’ve been working on recently. As for the large features, well apathy’s taking care of those. But there is one project that is tugging at my attention. And it’s a bit of a strange one, as part of me just wants to kill it. Yet it seems to be resisting.
Continue reading → -
Trying out the use of XML over a home made domain-specific language and… I must concede, it might be a better fit. As clunky as the DOM is, XML can be made to be good, as long as you use it in moderation.

