
Broadtail
Date: 2021 – 2022
Status: Paused
First project I’ll talk about is Broadtail. I think I talked about this one before, or at least I posted screenshot of it. I started work on this in 2021. The pandemic was still raging, and much of my downtime was watching YouTube videos. We were coming up to a federal election, and I was getting frustrated with seeing YouTube ads from political parties that offend me. This was before YouTube Premium so there was no real way to avoid these ads. Or was there?
A Frontend For youtube-dl
I had some experience with youtube-dl in the past, downloading and saving videos that I hoped to watch later. I recently discovered that YouTube also published RSS feeds for channels and playlist. So I was wondering if it was possible to build something that could use both of these. My goal was to have something that would allow me to subscribe to YouTube channels via RSS, download videos using youtube-dl, and watch them via Plex on my TV. This was to be deployed on a Intel Nuc that I was using as a home server, and be accessible via the web-browser.
I deceided to get the YouTuble downloading feature built first. I started a new Go project and got something up and running reasonably quickly. It was a good excuse to get back to vanilla Go web development, using http.Handle and Go templates, instead of relying on frameworks like Buffalo (don’t get me wrong, I still like Buffalo, but it is quite heavy handed).
It was also an excuse to try out StormDB, which is an embedded NoSQL data store. The technology behind it is quite good — it’s used B-Trees memory mapped files under the cover — and I tend to use it for other things as well. It proved to be quite usable, apart from not allowing multiple read/writers at the same time, which made deployments difficult.
But the backend code was the easy part. What I lack was any sense of web design. That’s one good thing about a framework like Buffalo: it comes with a usable style framework out of the box (Bootstrap). If I were to go my own way, I’d have to start from scratch.
The other side of that coin though, is that it would give me the freedom to go for something that’s slightly off-beat. So I went for an aesthetics that reminded me of early 2000 web-design: san-serif font, all grey lines, dull pastels colours, small controls and widgets (I stopped short at gradients and table-based layouts).
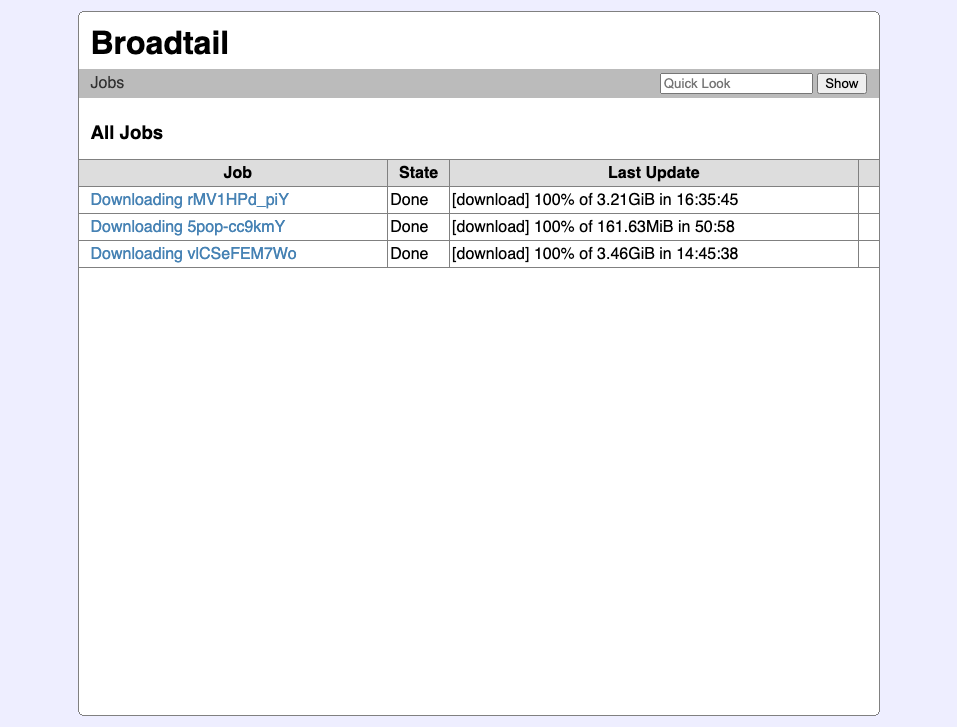
This version also included a hand-rolled job manager that I used for a bunch of other things. It’s… fine. I wouldn’t use it for anything “real”, but it had a way of managing job lifecycles, updating progress, and the ability to cancel a running job. So for that, it was good enough.
Finally, it needed a name. At the time, I was giving all projects bird-like codename, since I can’t come up with names that I liked. I eventually settled on Broadtail, which was a reference to broadtail parrots, like the rosella.
RSS Subscriptions
It didn’t take long after I got this up and running before I realised I needed the RSS subscription feature. So that was the next thing I added.
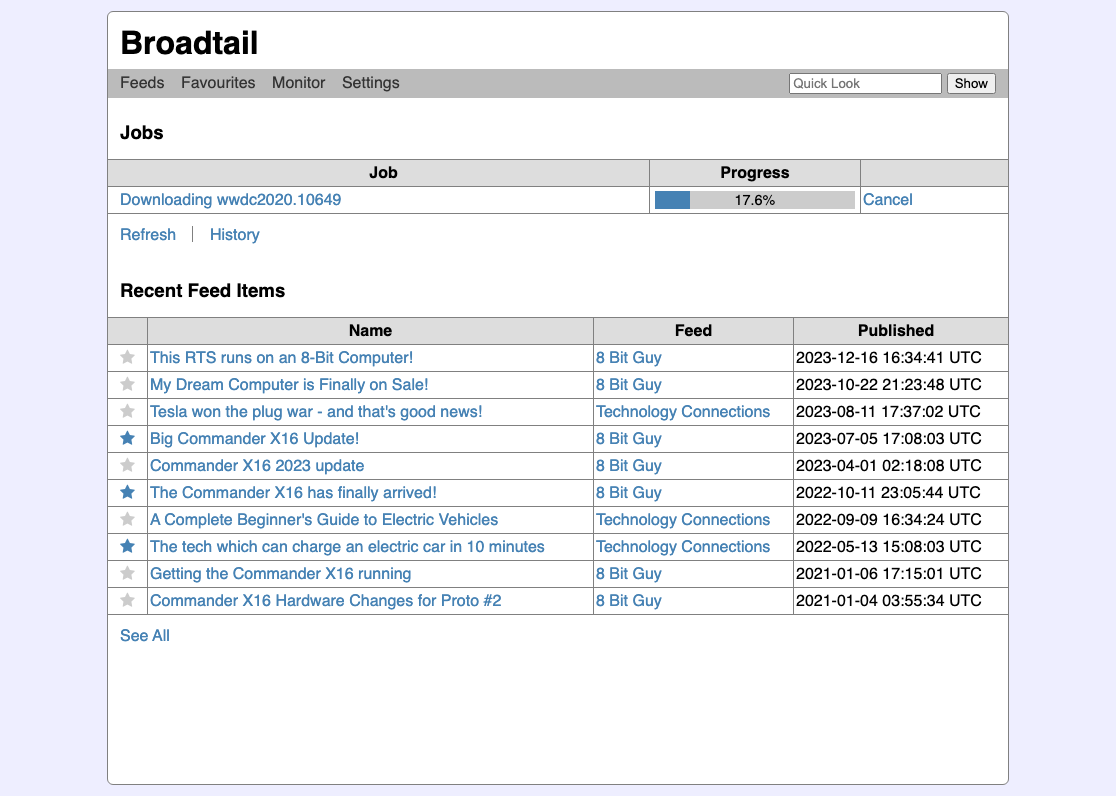
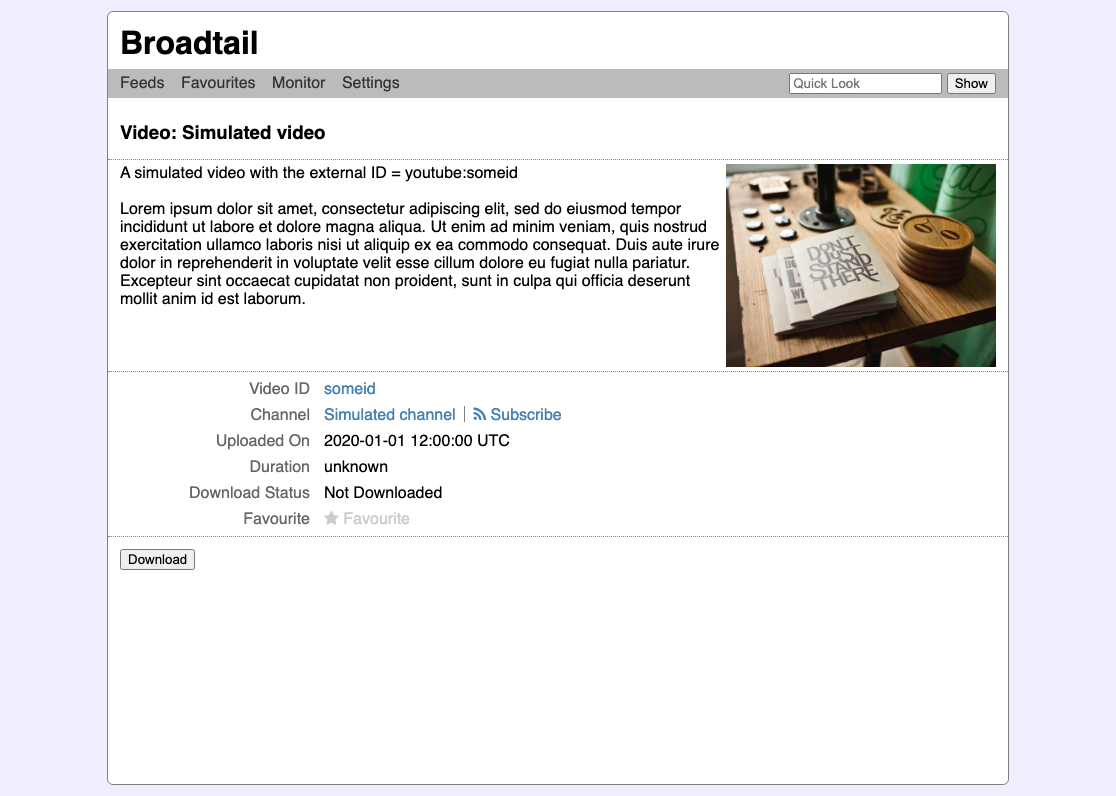
That way it worked was pretty straight forward. One would setup a subscription to a YouTube channel or playlist. Broadtail will then poll that RSS subscription every 15 minutes or so, and show new videos on the homepage. Clicking that video item would bring up details and an option to download it.
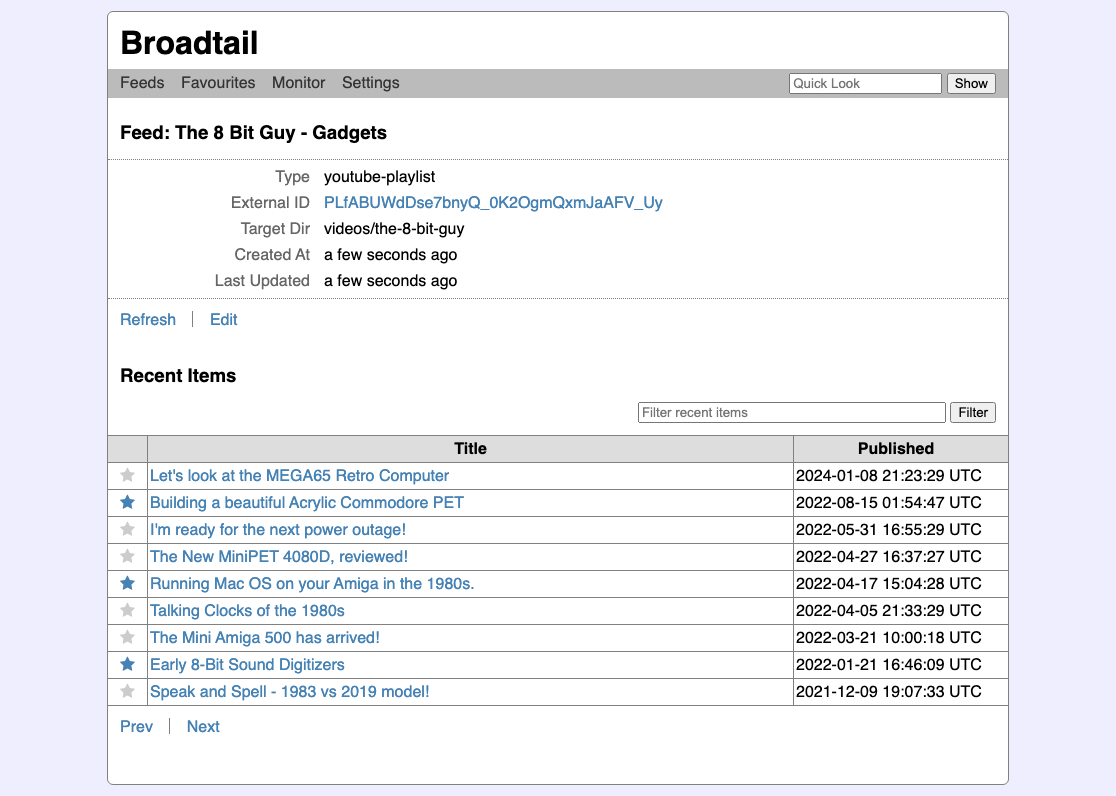
Each RSS subscription had an associated target directory. Downloading an ad-hoc video would just dump it in a configured directory but I wanted to make it possible to organise downloads from feeds in a more structured way. This wasn’t perfect though: I can’t remember the reason but I had some trouble with this, and most videos just ended up in the download directory by default (it may have had to do with making directories or video permissions).
Only the feed polling was automatic at this stage. I was not interested in having all shows downloaded, as that would eat up on bandwidth and disk storage. So users still had to choose which videos they wanted to download. The list of recent feed items were available from the home-screen so they were able to just do so from there.
I also wanted to keep abreast with what jobs were currently running, so the home-screen also had the list of running job.
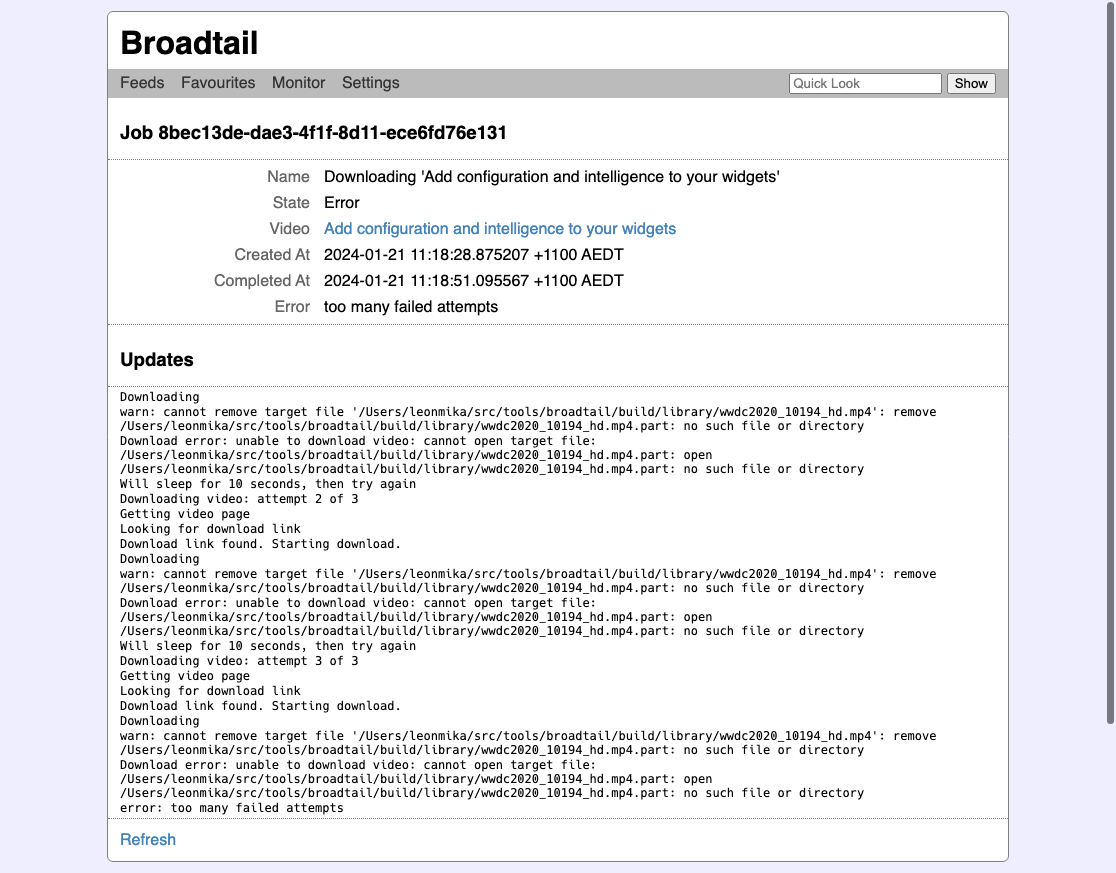
The progress-bar was powered by a web-socket backed by a goroutine on the server side, which meant realtime updates. Clicking the job would also show you the live output of the youtube-dl command, making it easy to troubleshoot any jobs that failed. Jobs could be cancelled at any time, but one annoying thing that was missing was the ability to retry failed job. If a download failed, you had to spin up a new job from scratch. This meant clearing out the old job from the file-system and finding the video ID again from wherever you found it.
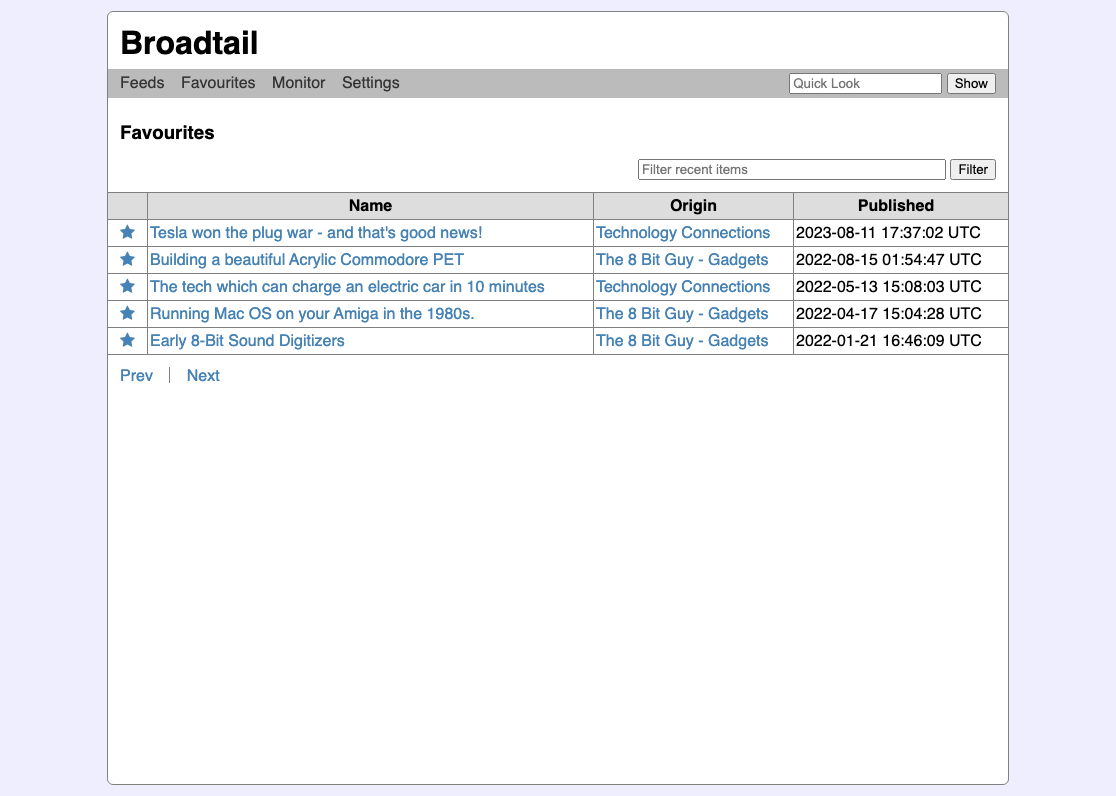
If you were interested in a video but were not quite ready to download it right away, you could “favourite” it by clicking the star. This was available in every list that showed a video, and was a nightmare to code up, since I was keeping references to where the video came from, such as a feed or a quick look. Keeping atop of all the possible references were become difficult with the non-relational StormDB, and the code that handled this became quite dodgy (the biggest issue was dealing with favourites from feeds that were deleted).
Rules & WWDC Videos
The basics were working out quite well, but it was all so manual. Plus, going from video publication to having something to watch was not timely. The RSS feed from YouTube was always several hours out of date, and downloading whole videos took quite a while (it may not have been realtime, but it was pretty close).
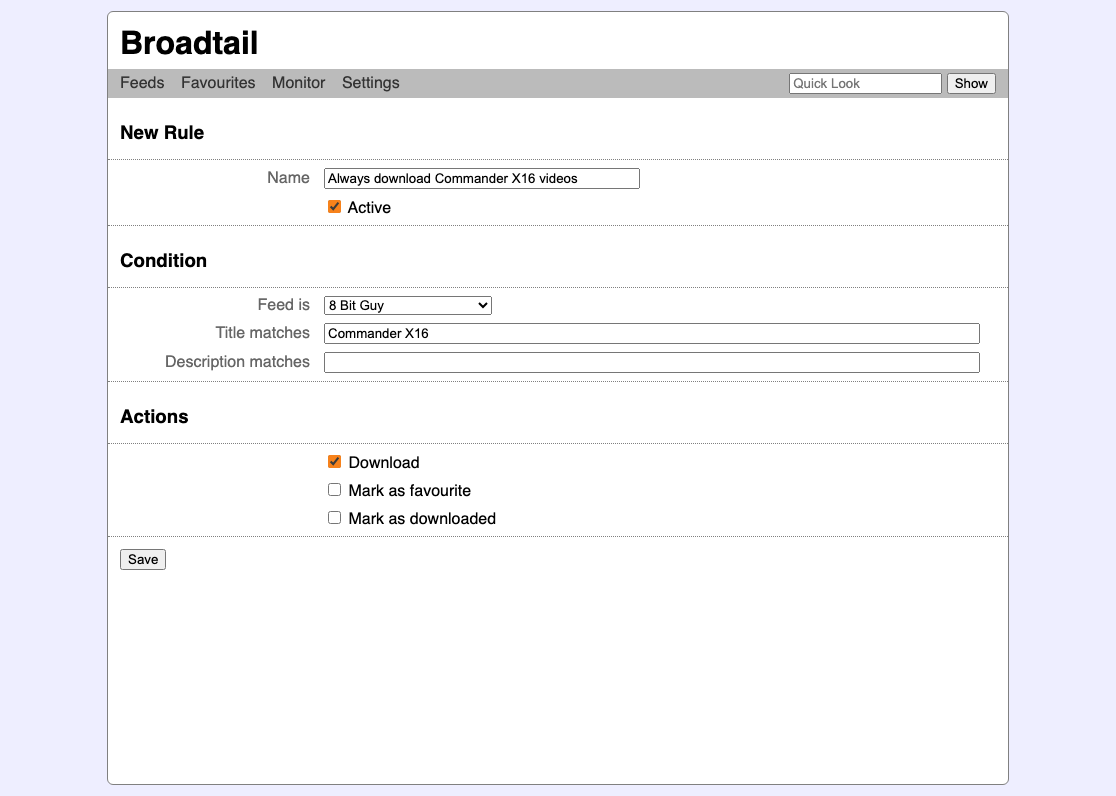
So one of the later things I added was a feature I called “Rules”. These were automations that would run when the RSS feed was polled, and would automatically download videos that met certain criteria (you could also hide them or mark them as downloaded). I quite enjoy building these sorts of complex features, where the user is able to do configure sophisticated automatic tasks, so this was a fun thing to code up. And it worked: video downloads would start when they become available and would usually be in Plex when I want to watch it (it was also possible to ping Plex to update the library once the download was finished). It wasn’t perfect though: not retrying failed downloads did plague it a little. But it was good enough.
This was near the end of my use of Broadtail. Soon after adding Rules, I got onto the YouTube Premium bandwagon, which hid the ads and removed the need for Broadtail as a whole. It was a good thing too, as the Plex Android app had this annoying habit of causing the Chrome Cast to hang, and the only way to recover from this was to reboot the device.
So I eventually returned to just using YouTube, and Broadtail was eventually abandoned.
Although, not completely. One last thing I did was extend Broadtail’s video download capabilities to include Apple WWDC Videos. This was treated as a special kind of “feed” which, when polled, would scrap the WWDC video website. I was a little uncomfortable doing this, and I knew when videos were published, they wouldn’t change. So this “feed” was never polled and the user had to refresh it automatically.
Without the means to stream them using AirPlay, downloading them and making them available in Plex was the only way I knew of watching them on my TV, which is how I prefer to watch them.
So that’s what Broadtail is primarily used for now. It’s no longer running as a daemon: I just boot it up when I want to download new videos. And although it’s only a few years old, it’s starting to show signs of decay, with the biggest issue being youtube-dl slowly being abandoned.
So it’s unlikely that I’ll put any serious efforts into this now. But if I did, there are a few things I’d like to see:
- Authentication added with username/password
- Retry failed video downloads.
- The ability to download YouTube videos in audio only (all these “podcasts” that are only available as YouTube videos… 😒)
- The ability to handle the lifecycle of videos a little better than it does now. It’s already doing this for errors: when a download fails, the video is deleted. But it would be nice if it did things like automatically delete videos 30 days after downloading them. This would require more control over the “video store” though.
So, that’s Broadtail.