
-
It may seem difficult to spot those that are a tad too enthusiastic about AI replacing jobs, but the signs are there. For one, they tend to be the type of people that don’t spend the 0.5 seconds it takes to realise that connecting your account reset login to your chatbots is not a good idea.
-
Really enjoyed Ben Thompson’s Daily Update today, about the success of Backrooms and Obsession, and how it compares to the recent Star Wars film. Really drives home the idea that in a world without gatekeepers, success involves coming up with something that’s actually compelling.
-
Done! The backdrops for my Godot game have been made. Finished the desert one last week, and the coast one this evening. I also redid the mountain one, which is a little less interesting than the one I had, but it better matches the others artistically. Now time for the meta elements. 😓
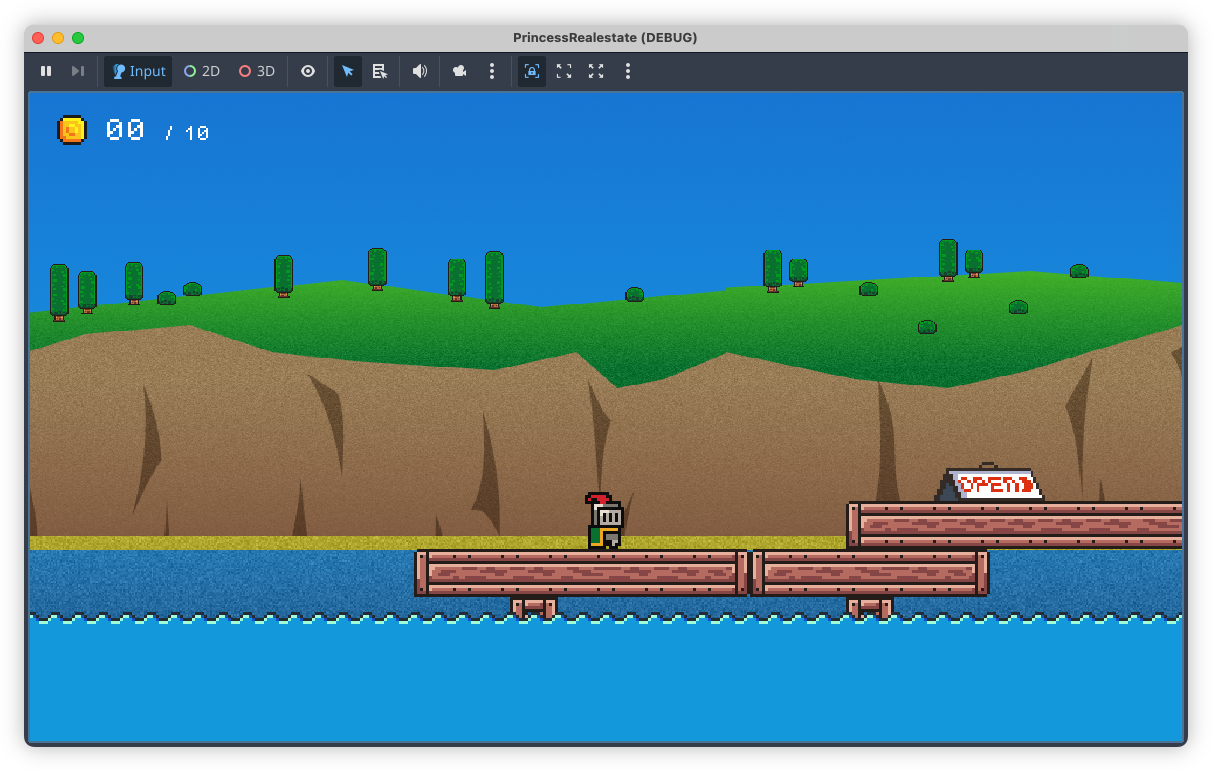
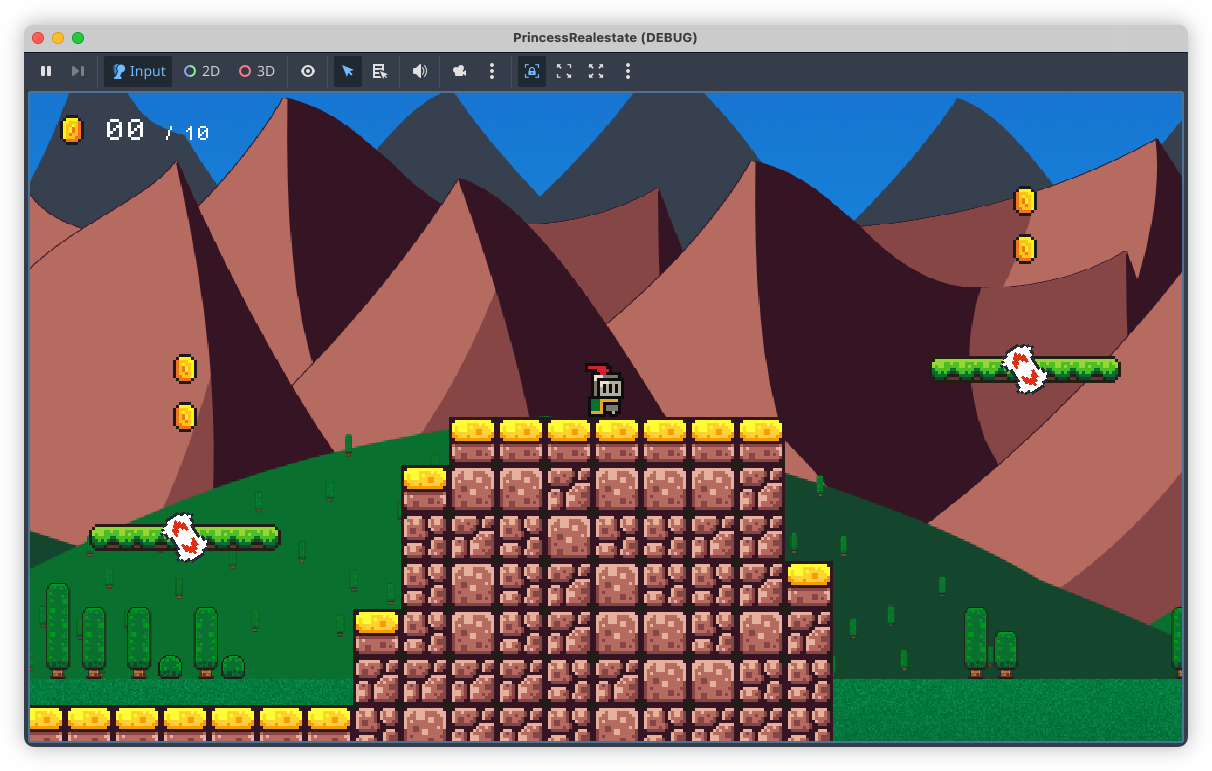
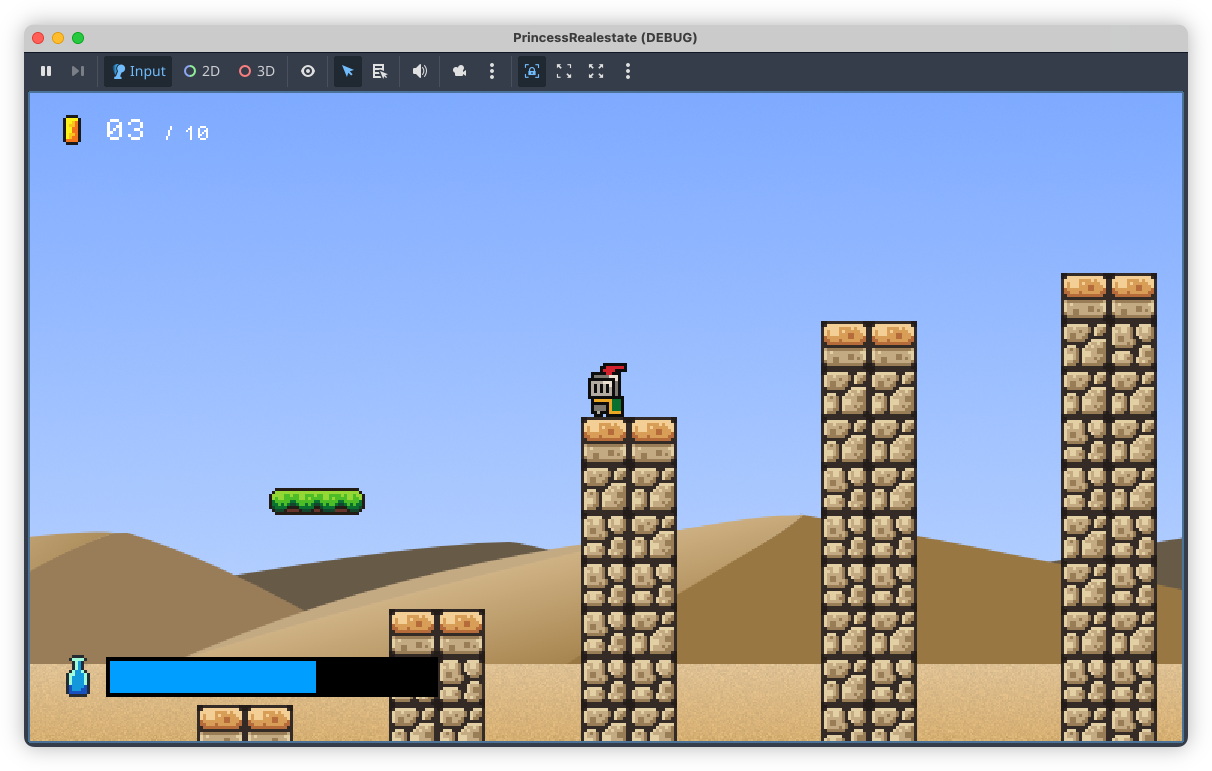 devlog screenshots
devlog screenshots -
Oof! First day of winter, and winter is definitely making itself known: cold, and wet. ❄️
-
Compared profile websites at work today. I really need to get mine cleaned up. I still have a link to GitHub, despite not using that account for much nowadays.
 screenshots
screenshots -
They say that “success is in the agency of others.” I think that’s true in more way than one. Certainly having contacts help, but I think also being around people that are willing to do things you wish you could helps too. It’s enabling, in the good sense of the word.
-
Now that I have Inkwell on all my devices, it’s time to close my Feedbin account. It’s been a great 9 years, and Feedbin has been an amazing service. I’m trying something different for the moment, but if it doesn’t work out, I may return. Until then, all the best. And thank you. 🥲
-
Must say that I’m looking forwarded to generic methods coming in Go 1.27. Generic functions work, but they feel out of place when the rest of your type uses methods in it’s API. This change will make for a great quality of life improvement, even if interface methods are excluded for now.
-
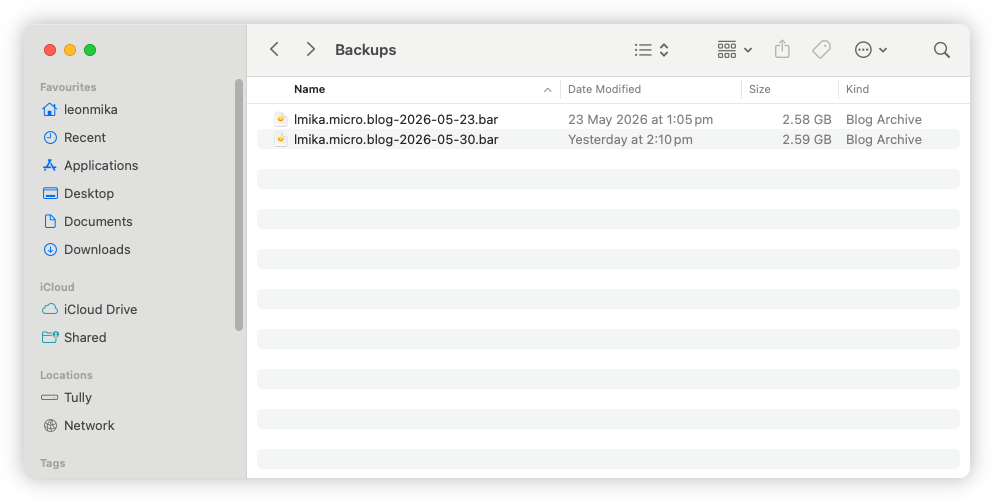
Trying to develop the habit of using the Micro.blog app for MacOS, so the backup feature will run. I expect the backups of this blog to be large. But 2.59 GB compressed? Wasn’t expecting it to be that large.
 screenshots
screenshots -
Backrooms is a certified blockbuster with a $38 million opening day
That also means that Backrooms is an incredibly profitable movie, with an estimated $10 million budget. By comparison, the latest Star Wars disappointment cost $165 million and was considered affordable compared to other entries in the series.
It may seem like having all the money in the world will grant you the ability to do anything, but I think it’s clear that there’s no way Disney could’ve made a film like Backrooms. Not because they don’t have the resources. Rather, their investors wouldn’t let them. It wouldn’t be too “mainstream” enough to justify the “risk”, and they have to justify the money they spent for the rights to Star Wars. So they’re stuck making mediocre things based on these tired franchises. Money entraps us all, both high and low.
-
Ah, blessed oak tree. Being the shelter of this fool who decided to go for a walk without a jacket or umbrella.

The hoodie helps a little.
-
At the cafe. The guy on the table I’m facing is reading the paper with a dog on his lap. The dog puts her front paws on the table, so the man starts placing pages on top of them. Then the dog places her head on the table. The guy then takes out his phone. I found this incredibly funny to witness.
 photos
photos -
All the recent liminal horror films that are coming out, like Backrooms and Exit 8, look interesting. Only issue is I generally hate horror, mainly because I can’t deal with things like jump scares. Here’s hoping the producers of these lean into the liminal aspect, and leave the cheap tricks out.
-
I had to smile after reading Manuel Moreale post about the Enhanced Games, namely because I had the same thought. I’ll only spend a few words on this, but the idea I had was for the event to be like the Formula One of althletics. Instead of individuals, different teams compete to engineer the best performing athlete tech can produce. This could include things like sportswear, diet, training regime, and yes, even developing performance enhancing drugs. An individual will still compete in the event but the team will get the glory.
-
The spreadsheet really is the “jack of all trades, master of none” app when it comes to structured data. It needs to be a calculator, database, structured table manipulator, and analysis tool; and it needs to be approachable to novices and usable by advanced users alike. And it does it. Not well, but it does it.
-
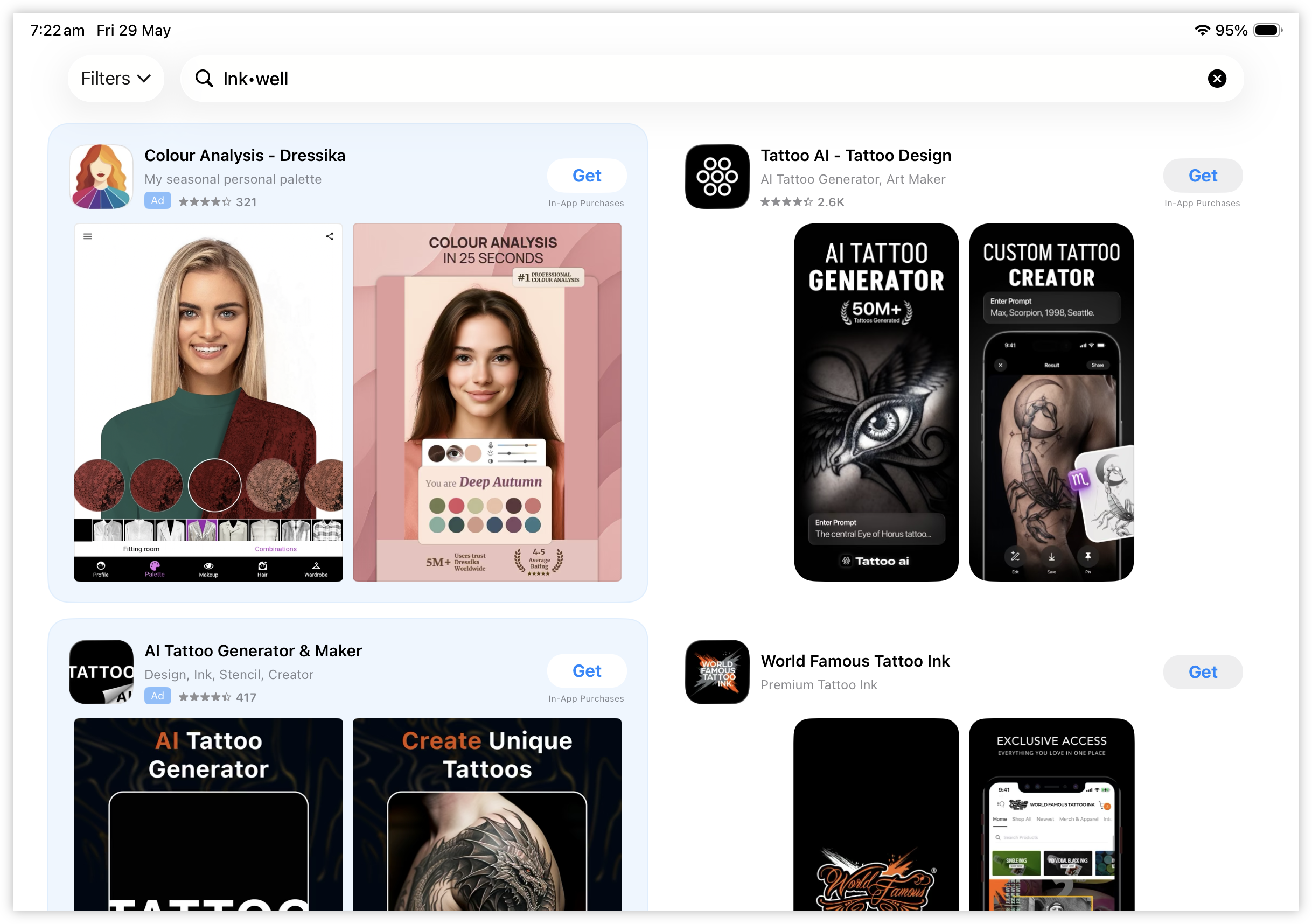
How does anyone find anything on the iOS App Store? Made several fruitless attempts at finding Inkwell, and ended up just using the link in the help guide. It’s there if you search for “Ink•well”. Just scroll past the unusually large number of AI tattoo generator apps, which is a thing apparently.
 screenshots
screenshots -
Given that this is the last day of free public transport I’ll personally experience, I’d probably won’t be going through Anzac station in the morning for a while. So took a quick detour and saw one of the service pigeons that have been honored with a statue and plaque.

 photos
photos -
Huh, apparently those crossings are called pedestrian scrambles, which is a great name. And I remember them being everywhere in Auckland’s CBD when I visited during the late 2000s. You know how many there are in Melbourne’s CBD? One. Making up 25% of the total scrambles in the entire metro area.
-
We need to introduce those diagonal crossings they have in Auckland, with a phase where only pedestrians get to cross. The intersection of Kings Way and Park St. can really benefit from this.
Maybe during the phase where trams get priority.
-
The Verge: Nobody wants to tell me why they only listen to their own Suno slop
Which might explain why nobody wanted to talk to me. The Suno subreddit is a safe place, filled with people doing the same thing. They don’t feel insecure or embarrassed. They have their bubble where people are supportive. And, look, I get it; nobody wants to be called lazy or a narcissist.
Of course, there is a third option: They don’t actually like music or care about art, and they don’t care to defend their low-effort relationship with it.
I don’t know. I think it’s a little unfair to expect people to like every form of art out there, regardless of what the provenance may be. Why should they defend their so-called “low-effort relationship” with music? Just because someone told them they should, because this music was made by a human and that one wasn’t?
I don’t like AI music, but I’m not going to turn my nose up at people who do. There are certain genres of music made by humans that I don’t care for either, and no amount of history behind the genre’s going to change that. Let people like what they like, and don’t be judgy.
-
Hmm, after using this new laptop for about a week, it turns out that the only thing worse than having a Touch Bar is not having a Touch Bar. I’ll miss the lock button I added, not to mention sliding to adjust the volume (I can take and leave the rest).
-
Hmm, either Steven Pressfield’s blog got hacked, or he’s decided to diversify. 😏
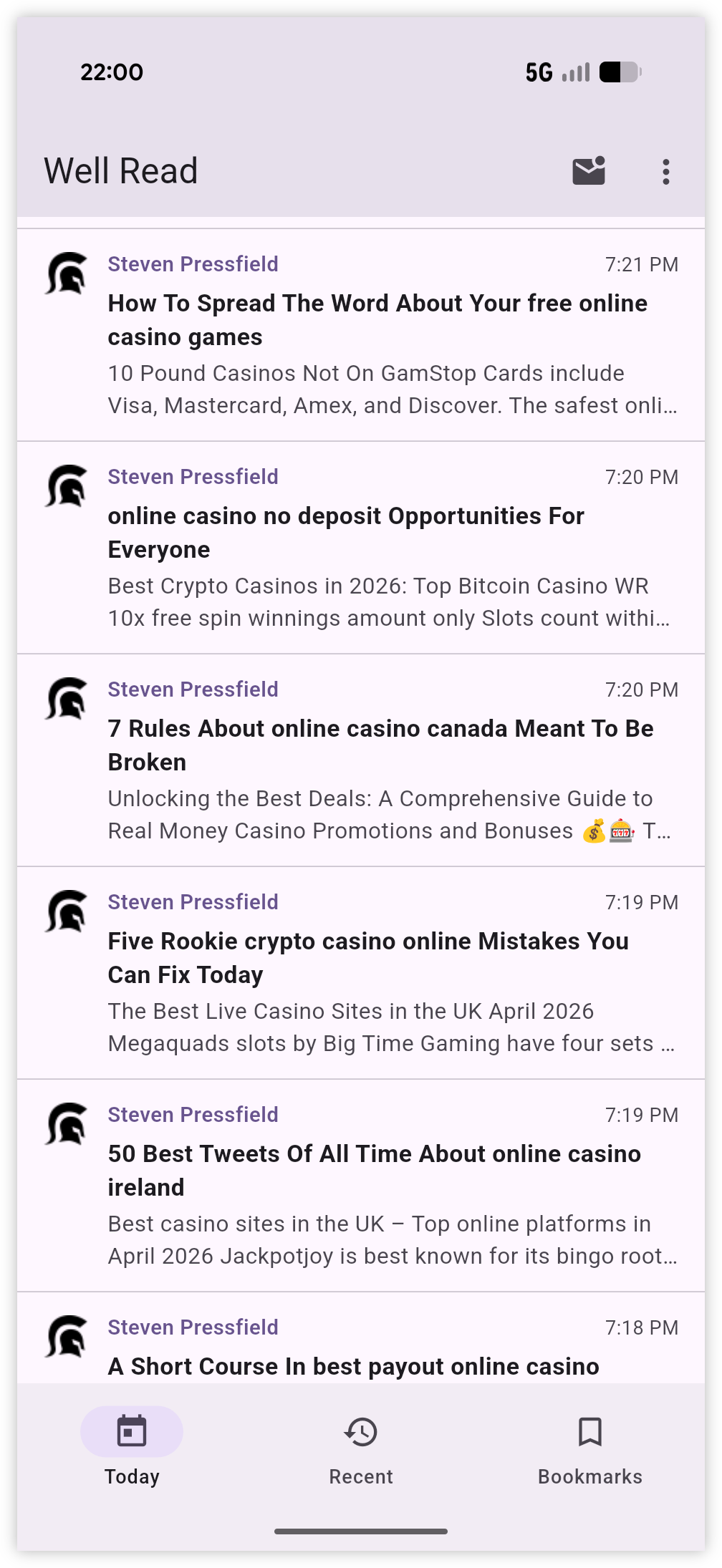
Also, props for being the first instance of RSS spam I’ve encountered in a long while.
screenshots -
Using YAML is hazardous to your health. Or at least, hazardous to the health of your Kubernetes cluster (which translate to your health if you’re responsible for fixing it).
-
Tried launching one of my apps on MacOS Tahoe, just to see if my icon would get put into squircle jail. Good news: my icon’s a free citizen (it’s the orange one).

You know what this means: I can never, ever, ever touch that Affinity Designer file ever again, lest I break something.
I’m a little surprised that the icon managed to avoid jail. Looks like the app signing is working too, which is great.
