
Intermediary Representation In Dynamo-Browse Expressions
One other thing I did in Dynamo-Browse is change how the query AST produced the actual DynamoDB call.
Previously, the AST produced the DynamoDB call directly. For example, if we were to use the expression pk = "something" and sk ^= "prefix", the generated AST may look something like the following:
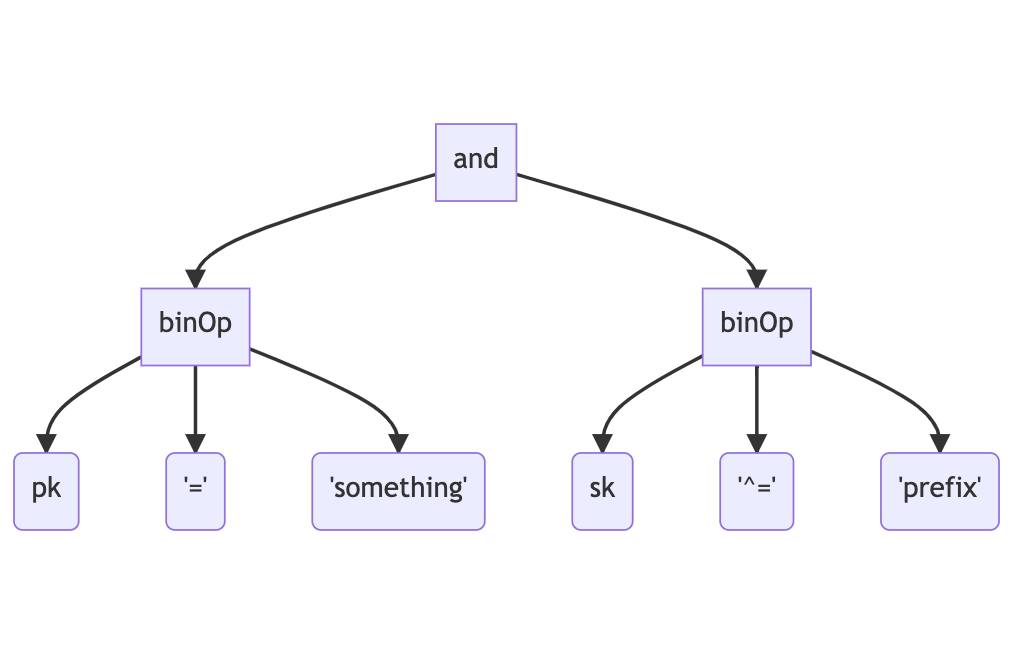
The AST will then be traversed to determine whether this could be handled by either running a query or a scan. This is called “planning” and the results of this will determine which DynamoDB API endpoint will be called to produce the result. This expression may produce a call to DynamoDB that would look like this:
client.Query(&dynamodb.QueryInput{
TableName: "my-table-name",
KeyConditionExpression: "#0 = :0 and beings_with(#1, :1)",
ExpressionAttributeNames: map[string]string{
"#0": "pk",
"#1": "sk",
},
ExpressionAttributeValues: map[string]types.AttributeValue{
":0": &types.StringAttributeValue{ Value: "something" },
":1": &types.StringAttributeValue{ Value: "prefix" },
},
})
Now, instead of determining the various calls to DynamoDB itself, the AST will generate an intermediary representation, something similar to the following:
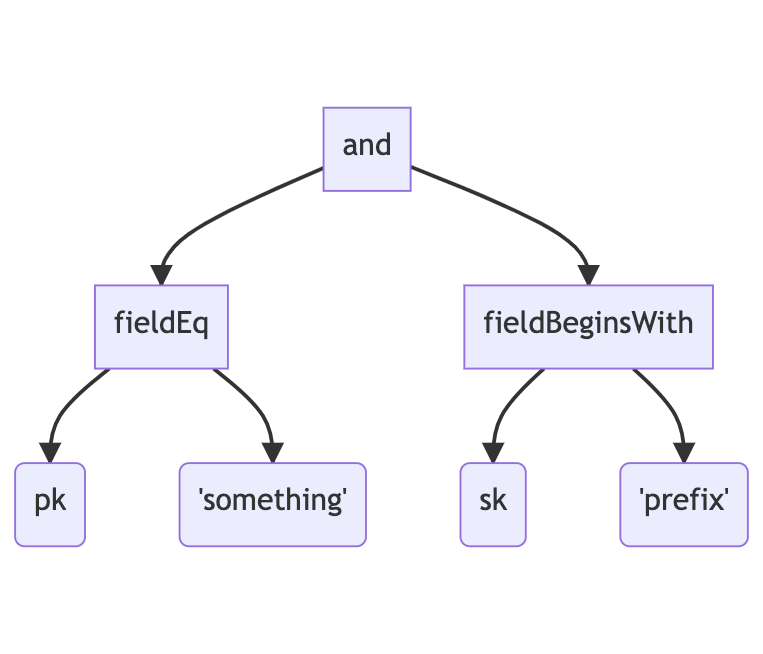
The planning traversal will now happen off this tree, much like it did over the AST.
For such a simple expression, the benefits of this extra step may not be so obvious. But there are some major advantages that I can see from doing this.
First, it simplifies the planning logic quite substantially. If you compare the first tree with the second, notice how the nodes below the “and” node are both of type “binOp”. This type of node represents a binary operation, which can either be = or ^=, plus all the other binary operators that may come along. Because so many operators are represented by this single node type, the logic of determining whether this part of the expression can be represented as a query will need to look something like the following:
- First determine whether the operation is either
=or^=(or whatever else) - If it’s
=and the field on the left is either a partition or sort key, this can be represented as a query - If it’s
^=, first determine whether the operand is a string, (if not, fail) and then determine whether the field on the left is a sort key. If so, then this can be query. - Otherwise, it will have to be a scan.
This is mixing various stages of the compilation phase in a single traversal: determining what the operator is, determining whether the operands are valid (^= must have a string operand), and working out how we can run this as a query, if at all. You can imagine the code to do this being large and fiddly.
With the IR tree, the logic can be much simpler. The work surrounding the operand is done when the AST tree is traverse. This is trivial: if it’s = then produce a “fieldEq”; if it’s ^= then produce a “fieldBeginsWith”, and so on. Once we have the IR tree, we know that when we encounter a “fieldEq” node, this attribute can be represented as a query if the field name is either the partition or sort key. And when we encounter the “fieldBeginsWith” node, we know we can use a query if the field name is the sort key.
Second, it allows the AST to be richer and not tied to how the actual call is planned out. You won’t find the ^= operator in any of the expressions DynamoDB supports: this was added to Dynamo-Browse’s expression language to make it easier to write. But if we were to add the “official” function for this as well — begins_with() — and we weren’t using the IR, we would need to have the planning logic for this in two places. With an IR, we can simply have both operations produce a “fieldBeginsWith” node. Yes, there could be more code encapsulated by this IR node (there’s actually less) but it’s being leverage by two separate parts of the AST.
And since expressions are not directly mappable to DynamoDB expression types, we can theoretically do things like add arithmetic operations or a nice suite of utility functions. Provided that these produce a single result, these parts of the expression can be evaluated while the IR is being built, and the literal value returned that can be used directly.
It felt like a few other things went right with this decision. I was expecting this to take a few days, but I was actually able to get it built in a single evening. I’m also happy about how maintainable the code turned out to be. Although there are two separate tree-like types that need to be managed, both have logic which is much simpler than what we were dealing with before.
All in all, I’m quite happy with this decision.