Workpad
- rank: (int) the position the player has in the match just played in accordance with the scoring, with
1being the player with the highest score,2being the player with the second highest score, and so on. - winner: (bool) whether the player is considered the winner of the match. The person with the highest score usually is, but this is treated as an independent field and so it should be possible to define rules accordingly.
- draw: (bool) whether the player shares their rank with another player. When a draw occurs, both winning players will have a rank of
1, with the player of the second highest score having a rank of2. - The ID3 tags of the MP3 will be read.
- That metadata will be used to determine the location of the object in S3.
- A pre-signed URL will be generated and sent to the browser to upload the file.
- The file is uploaded to S3.
- A new track record is created with the same metadata.
- Create a pre-signed URL to a temporary location in the S3 bucket.
- Allow the user to Upload the media directly to that location in the S3 bucket.
- On the server, download that media object to get the metadata and duration.
- From that, derive the objects location and move the object within S3, something I’m guessing should be relatively easy if the objects are in the same bucket.
- Create a new track record from the metadata.
Even more work on Feed Journaler. Still trying to tune the title removal logic. Will probably require a lot of testing.
Broadtail 0.0.7
Released Broadtail 0.0.7 about a week ago. This included some restyling of the job list on the home page, which now includes a progress bar updated using web-sockets (no need for page refreshes anymore).
For the frontend, the Websocket APIs that come from the browser are used. There’s not much to it — it’s managed by a Stimulus controller which sets up the websocket and listen for updates. The updates are then pushed as custom events to the main window, which the Stimulus controllers used to update the progress bar are listening out for. This allows for a single Stimulus controller to manage the websocket connection and make use of the window as a message bus.
Working out the layers of the progress bar took me a bit of time, as I wanted to make sure the text in the progress bar itself was readable as the progress bar filled. I settled in a HTML tree that looked like the following:
<div class="progressbar">
<!-- The filled in layer, at z-index: 10 -->
<div class="complete">
<span class="label">45% complete</span>
</div>
<!-- The unfilled layer -->
<span class="label">45% complete</span>
</div>
As you can see, there’s a base layer and a filled in layer that overlaps it. Both of these layers have a progress label that contain the same status message. As the .complete layer fills in, it will hide the unfilled layer and label. The various CSS properties used to get this effect can be found here.
The backend was a little easier. There is a nice websocket library for Go which handles the connection upgrades and provides a nice API for posting JSON messages. Once the upgrade is complete, a goroutine servicing the connection will just start listening to status updates from the jobs manager and forward these messages as JSON text messages.
Although this works, it’s not perfect. One small issue is that updates will not reconnect if there is an error. I imagine that it’s just a matter of listening out for the relevant events and retrying, but I’ll need to learn more about how this actually works. Another thing is that the styling of the progress bar relies of fixed widths. If I get around to reskinning the style of the entire application, that might be the time to address this.
The second thing this release has is a simple integration with Plex. If this integration is configured, Broadtail will now send a request to Plex to rescan the library for new files, meaning that there’s no real need to wait for the schedule rescan to occur before the videos are available in the app. This simply uses Plex’s API, but it needs the Plex token, which can be found using this method.
Anyway, that’s it for this version. I’m working on re-engineering how favourites work for the next release. Since this is still in early development, I won’t be putting in any logic to migrate the existing favourites, so just be weary that you may loose that data. If that’s going to be a problem, feel free to let me know.
Some More Updates of Broadtail
I’ve made some more changes to Broadtail over the last couple of weeks.
The home page now shows a list of recently published videos below the currently running jobs.
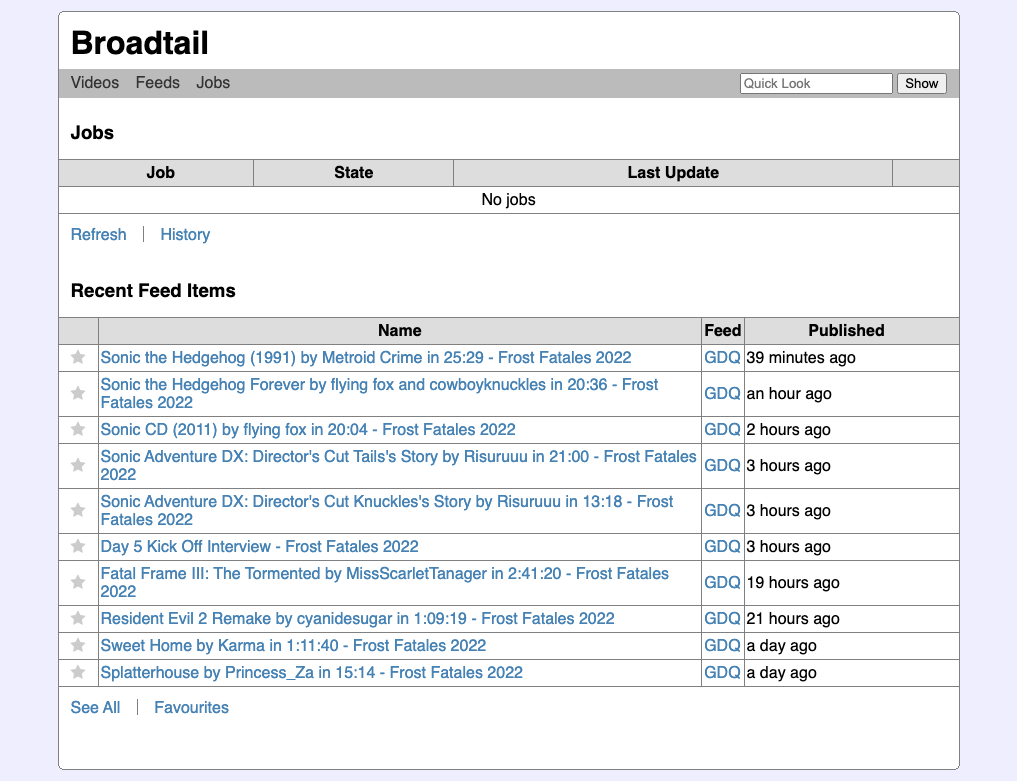
Clicking through to “Show All” displays all the published videos. A simple filter can be applied to filter them down to videos with titles containing the keywords (note: nothing fancy with the filter, just tokenisation and an OR query).
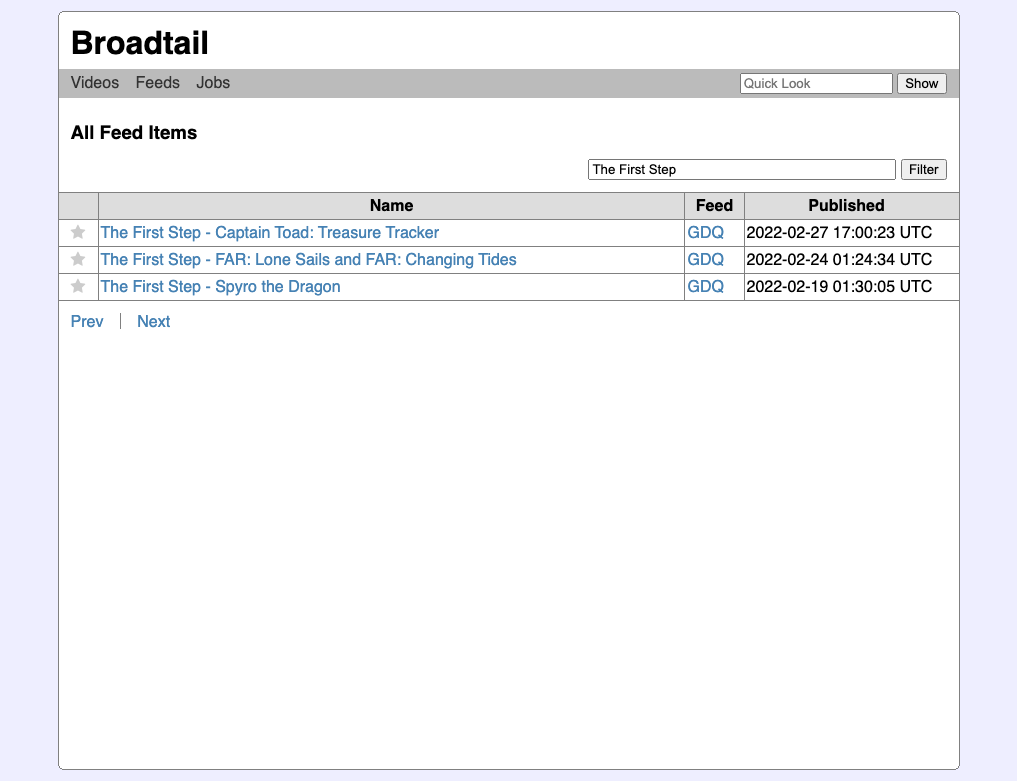
Finally, items can now be favourited. This can be used to select videos that you may want to download in the future. I personally use this to keep the list of “new videos” in the Plex server these videos go to to a minimum.
PGBC Scoring Rules
I get a bit of a thrill when there’s a need to design a mini-language. I have one facing me now for a little project I’m responsible for, which is maintaining a scoring site for a bocce comp I’m involve in with friends.
How scoring works now is that the winner of a particular bocce match gets one point for the season. The winner for the season is the person with the most points. However, we recently discuss the idea of adding “final matches,” which will give the match winner 7 points, the runner up 2 points, and the person who came in third 1 point. At the same time I want to add the notion of “friendly matches” which won’t count to the season score.
It might have been that a simple solution was to encode these rules directly in the app, and have a flag indicating whether a match was normal, final or friendly. But this was suboptimal as there is another variant of the game we play which do not have the notion of finals, and if we did, we may eventually have different rule for it. So I opted for a design in which a new “match type” is added as a new database entity, which will have the scoring rules encoded as a PostgreSQL JSON column type. Using this as a mechanism of encoding free(ish) structured data when there’s no need to query it has worked for me in the past. There was no need to add the notion of seasons points as it was already present as an easy way to keep track of wins for a season.
For the scoring rules JSON structure, I’m considering the use of an array of conditions. When a player meets the conditions of a particular array element, they will be awarded the points associated with that condition. Each player will only be permitted to match one condition, and if they don’t match any, they won’t get any points. The fields of the condition that a player can be matched to can be made up of the following attributes:
Using this structure, a possible scoring rules definition for a normal match may look like the following:
{ "season_score": [
{ "condition": { "winner": true }, "points": 1 }
]}
whereas a rules definition for the final match may look like the following:
{ "season_score": [
{ "condition": { "rank": 1 }, "points": 7 },
{ "condition": { "rank": 2 }, "points": 2 },
{ "condition": { "rank": 3 }, "points": 1 }
}]
Finally, for friendlies, the rules can simply look like the following:
{ "season_score": [] }
I think this provides a great deal of flexibility and extensibility without making the rules definition too complicated.
Alto Catalogue Update
I’ve really tied myself up in knots here. I’m spending some time working on Alto Catalogue, trying to streamline the process of uploading individual tracks into a new album. This is a workflow that is absolutely not user friendly at the moment, and the only way I’ve gotten tracks into the catalogue is to run a hacked-together tool to upload the tracks from the command line. The reason why I’m addressing this now is that it’s slightly embarrassing to have this open-source project without having a nice way of doing something that, by all accounts, is quite fundamental (a good hint for when you’re facing this is when it comes time to write the end-user documentation: if you can’t explain how to do something in a way that doesn’t include the word “hack”, “complicated”, or “unsupported”, then something is missing).
So I’m trying to close this feature gap, but it’s proving to be more complicated than I expected. The main issue relates ID3 tags and how media is arrange in the repository. Previous versions of the catalogue actually did have a way of uploading track media to the repository, which is essentially an S3 bucket. The way this work is that the catalogue will issue the browser a pre-signed Put URL, and the browser could upload the track media directly to S3. But in order to get a pre-signed URL, you need to know the object key, which is a bit like a file path. The old upload flow had the user enter the object key manually in the upload form.
This worked but I had some real issues with it. The first is that I’d like the objects within the S3 bucket to be organised in a nice way, for example “artist/album/tracknum-title.mp3”. I’m hoping that this S3 bucket will be my definitive music collection and I don’t want just some random IDs that are completely indecipherable when I browse the objects in the S3 bucket. That way, if I were ever to shutdown the catalogue down or loose all the metadata, I’d still be able to navigate my collection via the object keys alone.
The second was that this approach did not take into account the track metadata. Track metadata is managed in a PostgreSQL database and had to be entered in manually; yes, this included the track duration. The only reason I used the hacked together tool to upload tracks was that it was a tool I was already using to set ID3 tags on MP3 files, and it was trivial to add a HTTP client to do the upload from there. Obviously, asking users to run a separate tool to do their track uploads is not going to fly.
So I’m hoping to improve this. The ideal flow would be that the user will simply select an MP3 from their file system. When they click upload, the following things will happen:
The libraries I’m using to read the ID3 tags and track duration requires the track media to be available as a file on the local file system (I assume this is for random access). Simply uploading the track media to the local file system would be the easiest approach, since it would allow me to read the metadata, upload the media to the repository on the backend, and setup the track metadata all in a single transaction. But I have some reservations about allowing large uploads to the server, and most of the existing infrastructure already makes use of pre-signed URLs. So the first run at this feature involved uploading the file to S3 and then downloading it on the server backend to read the metadata.
But you see the problem here: in order to generate a pre-signed URL to upload the object to S3, I need to know the location of the media, which I want to derive from the track metadata. So if I don’t want uploads to go straight to the file system, I need the object to already be in S3 in order to work out the best location of where to put the object in S3.
So I’m wondering what the best ways to fix this would be. My current thing is this series of events:
The alternative is biting the bullet and allowing track uploads directly to the file system. That will simplify the crazy workflow above but means that I’ll need to configure the server for large uploads. This is not entirely without precedence though: there is a feature for uploading tracks in a zip file downloaded from a URL which uses the local file system. So there’s not a whole lot stopping me from doing this altogether.
The third approach might be looking for a JavaScript library to read the ID3 tags. This is not great as I’d need to get the location from the server anyway, as the metadata-derive object location is configured on a per repository basis. It also means I’ll be mixing up different ways to get metadata.
In any case, not a great set of options here.
Feeds In Broadtail
My quest to watch YouTube without using YouTube got a little closer recently with the addition of feeds in Broadtail. This uses the YouTube RSS feed endpoint to list videos recently added to a channel or playlist.
There are a bunch of channels that I watch regularly but I’m very hesitant to subscribe to them within YouTube itself (sorry YouTubers, but I choose not to smash that bell icon). I’m generally quite hesitant to give any signal to YouTube about my watching habits, feeding their machine learning models even more information about myself. But I do want to know when new videos are available, so that I can get them into Plex once they’re released. There is where feeds come in handy.
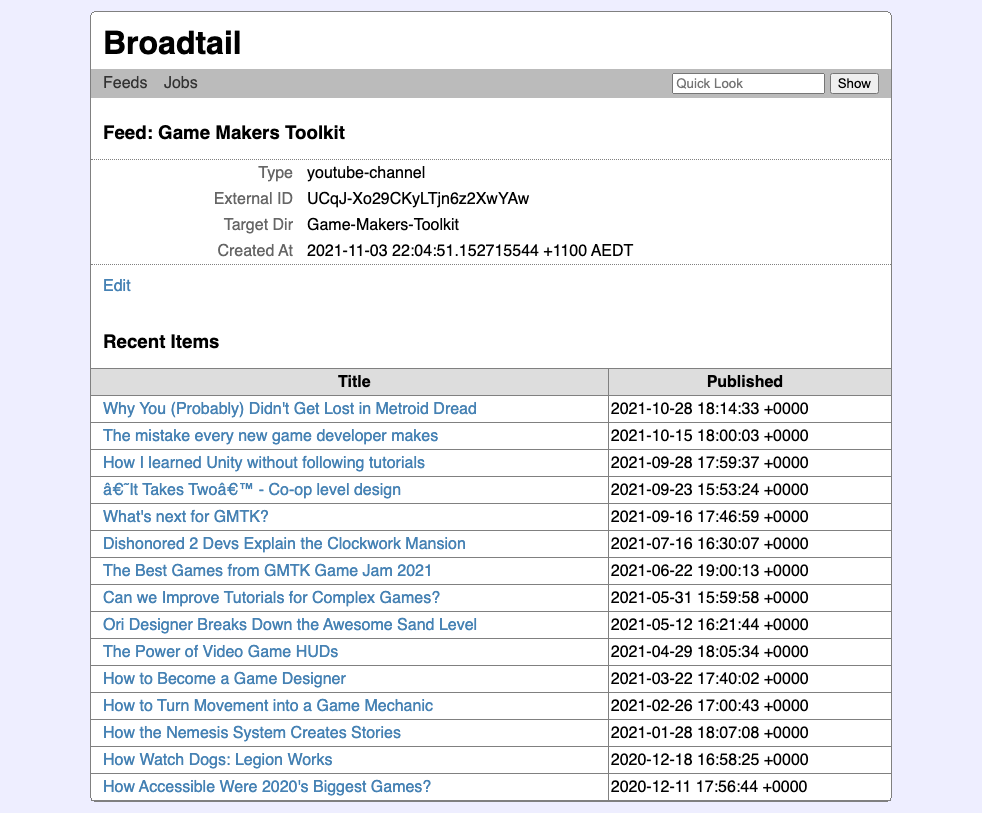
Also improved is the display of video metadata when selecting a feed item or entering a video ID in the quick look bar. Previously this would immediately start a download of the video, but I prefer knowing more about the video first. These downloads aren’t free, and they usually take many hours to get. Better to know more about them before committing to it.
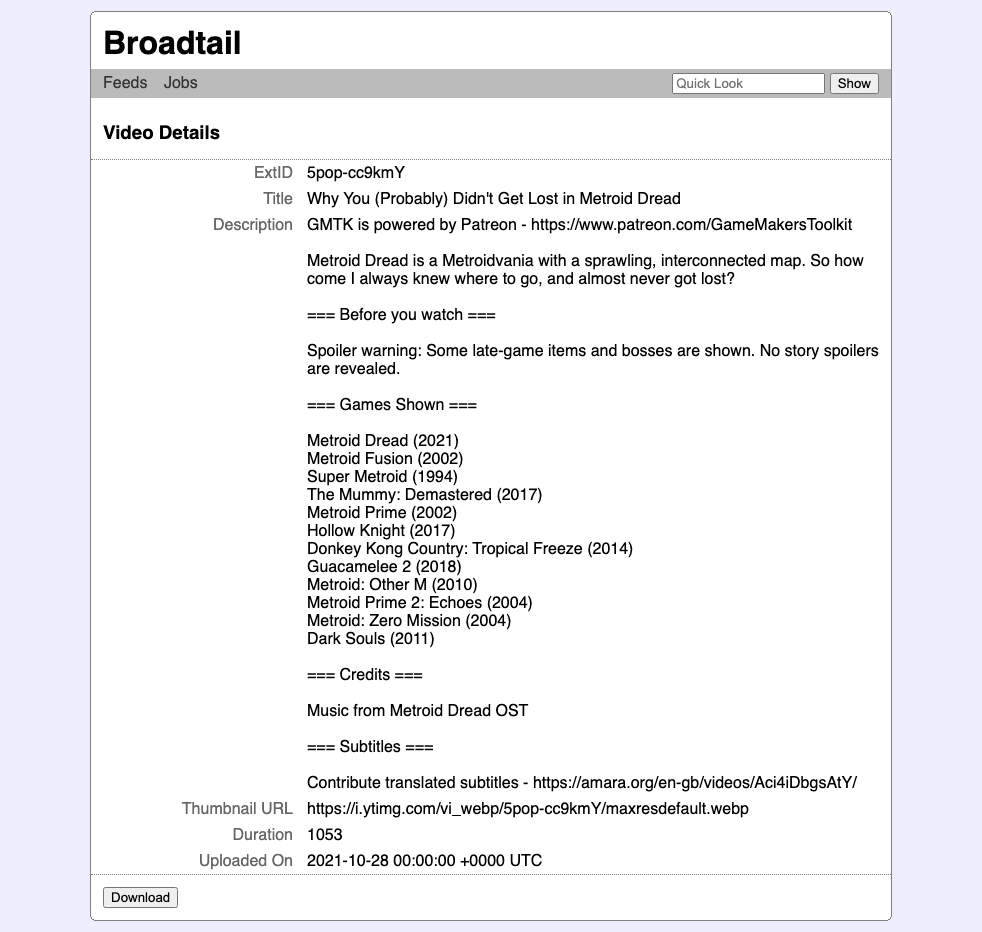
Incidentally, I think this mode of watching has a slight benefit. There are days when I spend the whole evening binging YouTube, not so much following the algorithm but looking at the various channels I’m interested in for videos that I haven’t seen yet. Waiting several hours for a video download feels a little more measured, and less likely to send me down the YouTube rabbit hole. I’m sure there will still be evenings when I do nothing else other than watch TV, but hopefully that’s more of a choice rather than an accident.
I think this is enough on Broadtail for the time being. It’s more or less functional for what I want to do with it. Time to move onto something else.
Some Screenshots Of Broadtail
I spent some time this morning doing some styling work on Broadtail, my silly little YouTube video download manager I’m working on.
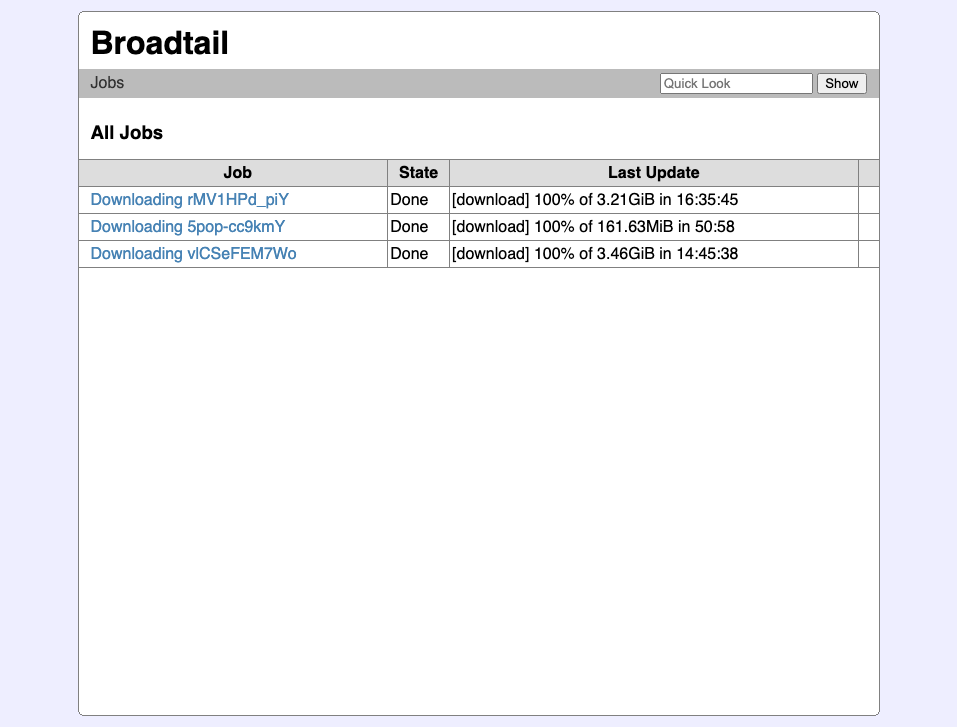
Now, I think it’s fair to say that I’m not a designer. And these designs look a little dated, but, surprisingly, this is sort of the design I’m going for: centered pages, borders, etc. A bit of a retro, tasteless style that may be ugly, but still usable(-ish).
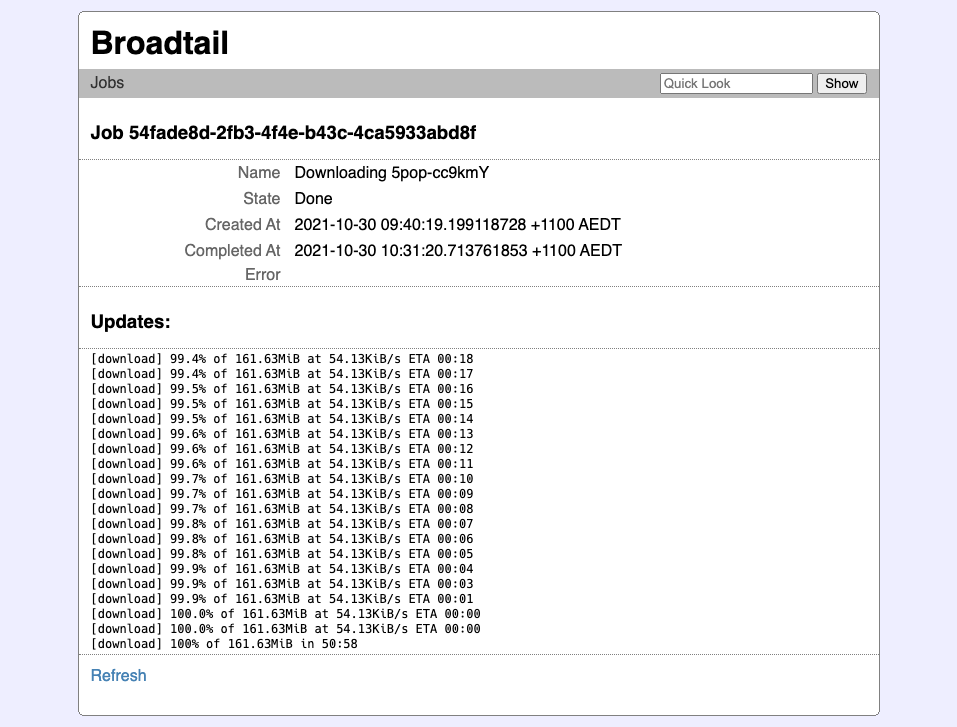
It’s not quite finished — the colours need a bit of work — but it’s sort of the style I have in my head.
More work on the project I mentioned yesterday, codenamed Broadtail. Most of the work was around the management of download jobs. I’m using a job management library I’ve built for another project and integrated it here so that the video downloads could be observable from the web frontend. The library works quite well, but at the moment, the jobs are not kept on any sort of disk storage. They are kept in memory until they’re manually cleared, but I’m hoping to only keep the active jobs in memory, and store historical jobs onto disk. So most of today’s session was spent on making that possible, along with some screens to list and view job details.
Start of Yet Another Project Because I Can't Help Myself
One of the reasons why I stopped work on Lorikeet was that I was inspired by those on Micro.blog to setup a Plex server for my YouTube watching needs. A few years ago, I actually bought an old Intel Nuc for that reason, but I never got around to setting it up. I managed to do so last Wednesday and so far it’s working pretty well.
The next thing I’d like to do is setup RSS subscriptions for certain YouTube channels and automatically download the videos when they are publish. I plan to use “youtube-dl” for the actual video downloading part, but I’m hoping to build something that would poll the RSS feeds and trigger the download when new videos are published. I’m hoping that this service would have a web-based frontend so I don’t have to login via SSH to monitor progress, etc.
The download’s would need to be automatic as the requests made by youtube-dl seem to be throttled by YouTube and a longish video may take several hours to download. If this was a manual process, assuming that I would actually remember to start the download myself, the video won’t be ready for my evening viewing. I’m hoping that my timezone would work to my advantage here. The evenings on the US East Coast are my mornings, so if a video download starts at the beginning of the day, hopefully it would be finish when my evening rolls around. I guess we’ll see.
Anyway, that’s what my current coding project will be on: something that would setup RSS subscriptions for YouTube channels, and download new videos when they are published.
This is probably one of those things that already exist out there. That may be true, but there are certain things that I’m hoping to add down the line. One such thing might be adding the notion of an “interest level” to channels which would govern how long a video would be kept around. For example, a channel that is marked as very interested would have every video downloaded and stored into Plex straight away. Mildly interested channels would have videos download but kept in a holding place until I choose to watch it, in which case it would be moved to Plex. If that doesn’t happen in 7 days or so, the videos would be removed.
I’d like to also add some video lifecycle management into the mix as well, just to avoid the disk being completely used up. I can see instances where I’d like to mark videos as “keep for ever” and all the others will churn away after 14 days or so. It might be worth checking out what Plex offers for this, just to avoid doubling up on effort.
But that’s all for the future. For the moment, my immediate goal is to get the basics working.
Abandoning Project Lorikeet
I’ll admit it: the mini-project that I have been working on may not have been a good idea.
The project, which I gave the codename Lorikeet, was to provide a way to stream YouTube videos to a Chromecast without using the YouTube app. Using the YouTube app is becoming a real pain. Ads aside, they’ve completely replaced the Chromecast experience from a very basic viewing destination to something akin to a Google TV, complete with recommendations of “Breaking News” from news services that I have no interest in seeing.
So I spent some time trying to build something to avoid the YouTube app completely, using a mixture of youtube-dl, a Buffalo web-app, and a Flutter mobile app. I spent the last week on it (it’s not pretty so no screenshots), but at this stage I don’t see much point continuing to work on it.
For one, the experience is far from perfect. Video loading is slow and there are cases when the video pauses due to buffering. I’m sure there are ways around this, but I really don’t want to spend the time learning how to do this.
It was also expensive. I have a Linode server running in Sydney which acts as a bit of a hobby server (it’s also running Pagepark to serve this site); but in order to be closer to the YouTube CDNs that are closer to me, I had to rent a server that would run in Melbourne. And there are not many VPS hosting providers that offer hosting here.
So I went with Google Cloud.
Now, I’m sure there’s a lot to like about Google Cloud, but I found its VPS hosting to be quite sub-par. For just over $10 USD a month, I had a Linux virtual server with 512 MB of RAM, 8 GB of storage, and a CPU which I’d imagine is throttled all the way back as trying to do anything of significants slowed it to a crawl. I had immense issues installing OS updates, getting the Dokku based web-app deployed, and trying to avoid hitting the storage limit.
For the same amount of money, Linode offers me a virtual server with 2 GB of RAM, 50 GB of storage, and a real virtual CPU. This server is running 4 Dokku apps, 3 of them with dedicated PostgreSQL databases, and apart from occasionally needing to remove dangling Docker images, I’ve had zero issues with it. None! (The podcasters were right).
Where was I? Oh, yeah. So, that’s the reason why I’m abandoning this project and will need to re-evaluate my online video watching experience. I might give Plex a try, although before doing something like setting up a dedicated media server, I’ll probably just use the Mac Mini I’ve been using for a desktop in the short term.
So, yeah, that’s it. It’s hard to abandon a project you spent any amount of time on. I suppose the good thing is that I got to play around with Flutter and learnt how to connect to a Chromecast using Dart, so it’s not a complete waste.