-
Oh, to have the endless optimism of a pigeon hanging around outdoor cafe furnature.
-
📘 Devlog
An API For a Keyframe Animation Package
A Go-based key-frame animator for Ebitengine projects was developed, emphasizing a clear API for animating float values with room for future enhancements. Continue reading →
-
🔗 Steven P. Wickstrom: Over 300 words to use instead of SAID
Filing this for later when I want to write some fiction (it could happen).
Via: summeroakes.bsky.social on Bluesky
links -
Released version 1.4.0 of Postlist for Micro.blog. New feature is the ability to turn off summaries in favour of the post’s body when using content display mode. This is achievable with the added
content-optionsparameter:{{< postlist display="content" content-options="no-summary" >}}milestones -
Listening to the latest ATP, it’s just killing me that the hosts are saying “iPhone XX” (as in “i-phone-ex-ex”) without considering that, given that the X in iPhone X refers to the Roman Numeral for 10, XX could refer to 20.
-
Achievement unlocked: setting up a CI/CD pipeline the builds a Go WASM project and deploys it to Netlify that worked first try.
golang -
Rendering Outlined Text in Ebitengine
A method for rendering outlined text using the Ebitengine and the shapes package by creating a separate image for the text and applying an outline to it. Continue reading →
-
🛠️ Textarea
A minimalist text editor that lives entirely in your browser and stores everything in the URL hash.
An interesting idea. Gave it a try and it seems to work. There’s more info about it on the Github repo.
Via: Simon Willison
tools -
Just placed the exit on Level 3-2 on my Godot game. The level still needs prettying up but the critical path is now done. I’ll think this will be the last level I build. There’s still so much work to do: polishing, backdrops, menus, etc. But no more content. Kind of want to put a pin in this one.
 devlog screenshots
devlog screenshots -
🔗 Simon Willison: How Rob Pike got spammed with an AI slop “act of kindness”
Rob Pike (that Rob Pike) is furious […] Rob got a 100% AI-generated email credited to “Claude Opus 4.5 AI Village” thanking him for his contributions to computing. He did not appreciate the gesture.
Got a lot of emotional swings while reading this: outrage that someone would use AI agents to send spam like this, understanding as to what actually happened, then distaste with those responsible in their belief that the time wasted receiving emails like this is an acceptable external cost.
But really, the whole experiment seems irresponsible. I can understand the want to see what these models could do, but come on: don’t given them access to a computer open to the Internet without any supervision. Rob Pike, a notable computer scientist that would be known to all these models, is right to be outraged. I would be too if I received this sort of unsolicited slop.
links -
🔗 Weird Medieval Guys: How birds got human names
Magpies were originally known simply as “pies” until the nickname “Mag”, short for Maggie, short for Margaret was added to the front sometime in the Middle Ages. Before it began to be treated as a single word, it was rendered as “Mag Pie”, a sort of fanciful full name for the creature.
Fascinating. This is, shall we say, the “money” quote of the linked post, but the rest is still quite an interesting read.
links -
2025 Song of the Year
Once again, a need to play something during Christmas Eve Mass has come around, so it’s time to elect 2025’s Song of the Year.
No obvious song stood out this year, unlike 2023 and 2024. Looking back on what new music I listened to, it was mainly a lot of Enya and Lee Rosevere, with a bit of Anders Enger Jensen. Near the end of the year I also started listening to Jon Hopkins, in addition to one or two other artists featured in the “medleys” published on Music For Programming. Apparently the way I find new music — YouTube videos or finding something I can put on the background for a commute or project work — remains unchanged.
Continue reading → -
Dec 23rd — Baking
Ahhh! When I ordered this, I didn’t think it would be a whole loaf. It’s a little much for one person. #12days
 photos
photos -
TIL that you can make a call to someone, put them on hold, then start a second call to that same person, and the POTS network supports this without any issues. You can even merge the two calls, resulting in two active calls to the one recipient.
-
The place I’m staying in has a drip-coffee machine. Normally I shun such contraptions (I’m a Melburnian with Italian herritage, damnit!) but ultimately, I don’t mind using them. In fact, I prefer them over the pod-coffee machines: the coffee is better and there’s less waste.
-
Dec 22 - Grinch
Got really lucky with this one. If this place I grabbed a coffee didn’t have this, I wouldn’t have had an entry for today. #12days
 photos
photos -
In my last post I mentioned that I heard AI music in the past. I’ve tried a service to generate this music a couple of times, but I’ve never really liked what it produced. It all sounds vapid. It’s got the surface criteria of a music: it’s chromatically correct, there what appears to be build up of tension. Yet, it all sounds like fluff to my ears.
My theory is that good music needs to have repetative elements, but enough variation to avoid it sounding boring. It could be variations to one or more theme; could be lyrics (chorus as verses); could also be the orchestration, where instructions come and go. AI music has none of this: none of the music has a central theme one can use as a hook, nor is there any variation to the instrumentation. I’ve only tried generating instrumentation songs so maybe music with lyrics sound better. But nah, not for me.
-
Current day renditions of classic and modern Christmas songs are really bad. I don’t know what compels artists, which I assume are contemporary, to release this rubbish. Honestly, I’d rather listen to AI generated music, and I’ve heard AI generated music.
-
Trying out MB Manager by @timapple. Not bad. I like how snappy everything is. I also like the option for a serif font. Quite a unique way of reading Micro.blog.
 screenshots
screenshots -
Found another 20 cent coin from Singapore in my washing the other day. I now think they did come from my 2023 trip to Singapore, as I checked my cash box to see if it was the same coin as last time and I found a $1 SGD coin in there too.
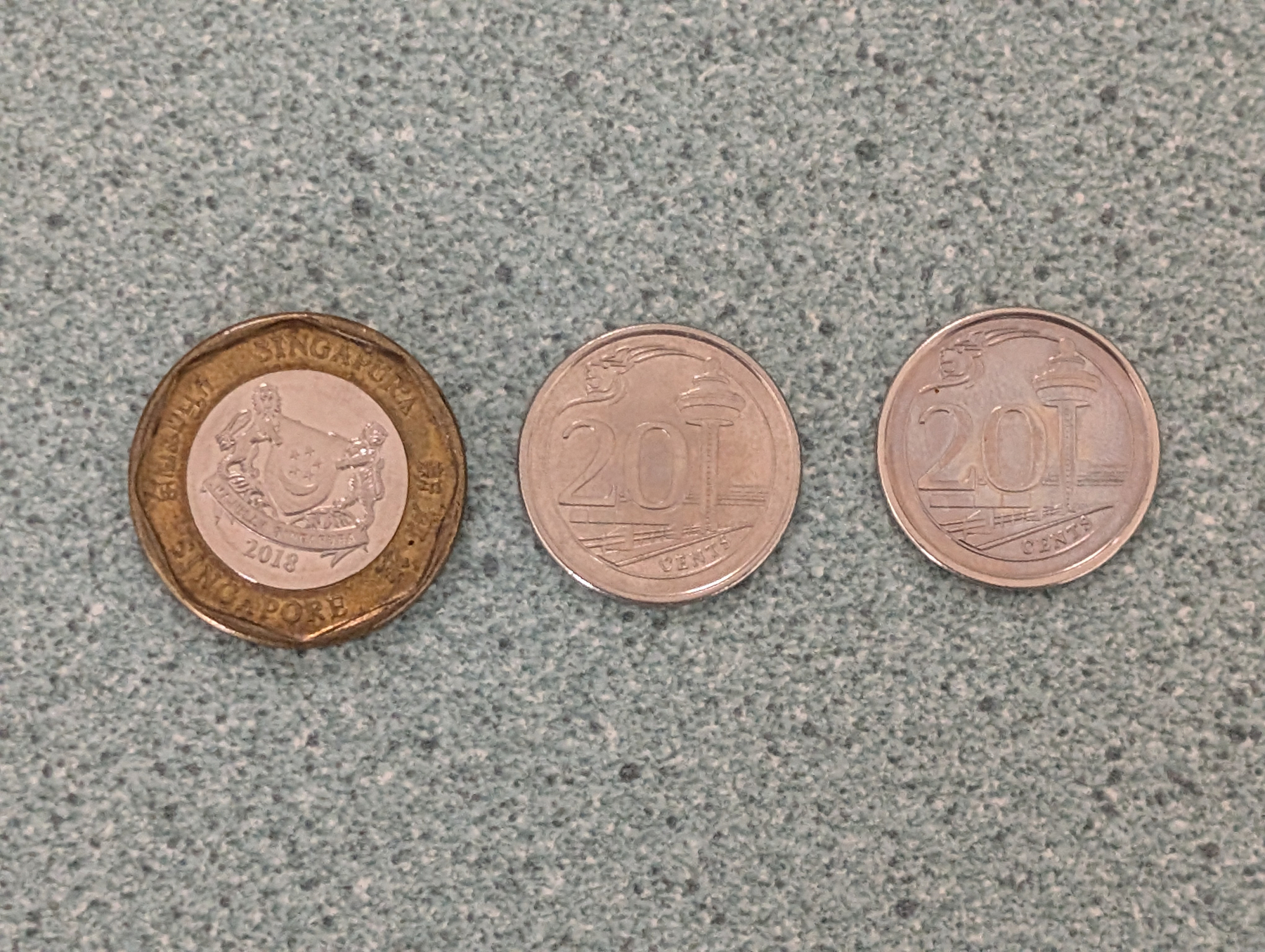 photos
photos