
-
Did a bit of work on Dynamo Browse this morning, adding a command to request a single key-press from the user. I was tempted to name it
ui:inkeyin honour of BASIC, but I resisted and decided on the more appropriate (yet longer) nameui:prompt-keypress. -
🔗 Anil Dash: Founders Over Funders. Inventors Over Investors
Enjoyed this post from Anil Dash; although being a tech practitioner, that probably wouldn’t be too surprising. But I don’t think it makes it any less true.
links -
Interesting bocce session today. We had a group of passers by approach us and ask about the game. Even asked if they could play a round, which we did. Also some bird activity, including this bin chicken that took an interest in the game.
 photos
photos -
Waiting at the rendezvous point for a spot of bocce. The morning is absolutely perfect. The gardens are nice and shady, now that the leaves on the trees have grown in.


 photos
photos -
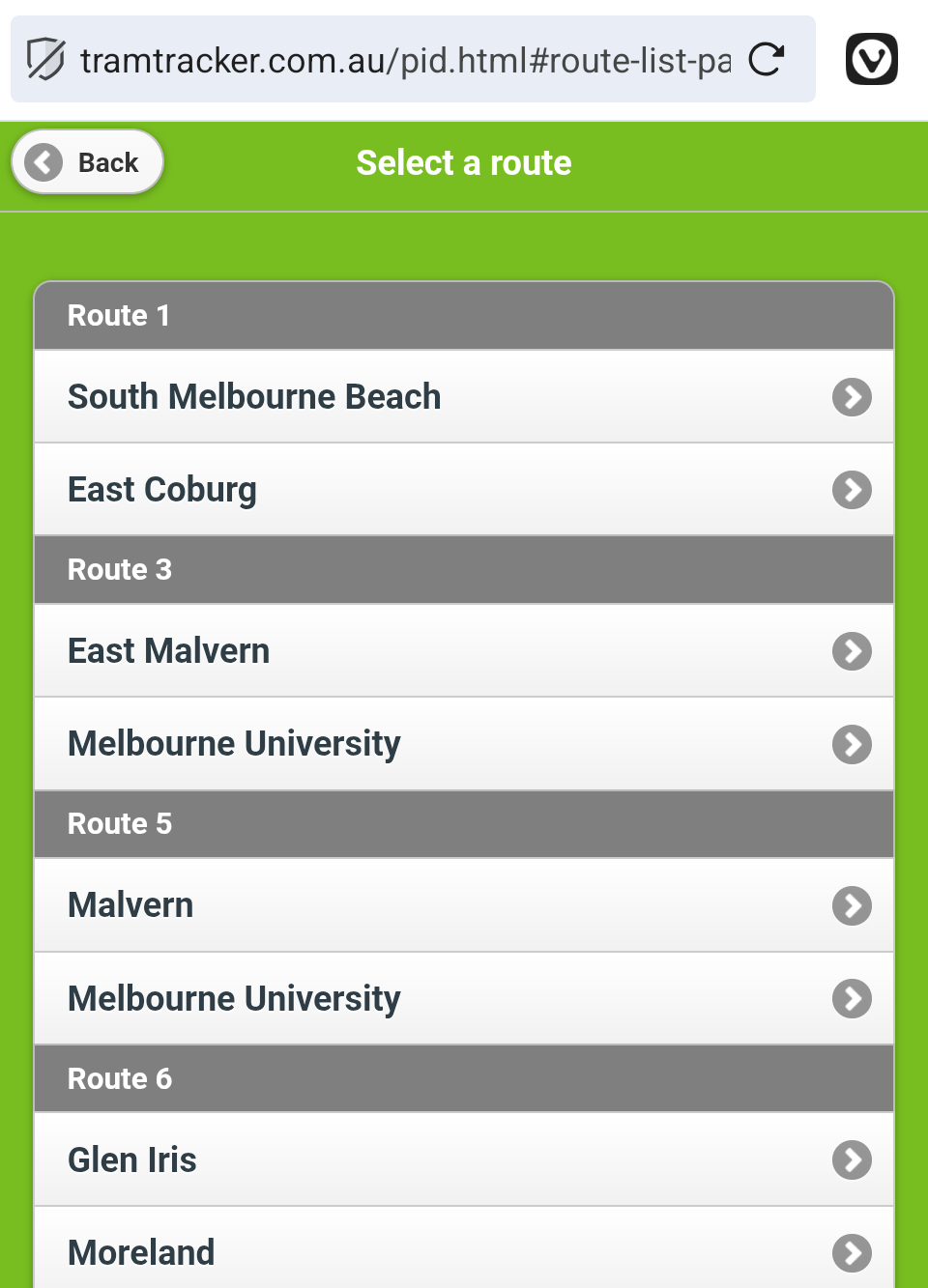
Anyone remember jQuery Mobile? Looks to be live and well on Tram Tracker. First time I actually noticed it, as I usually don’t have a need to visit the website.
 screenshots
screenshots -
I mentioned before the abandoned train line that appears in my dreams from time to time. Well, last night, it returned, and was seeing some pretty significant freight traffic. Some new infrastructure too. Looks like it may reopen soon. I wouldn’t know for sure though, I’m just a visitor. 😛
-
My eye has been wandering towards the Cards Theme of late. It was enough of a pull that I decided, after a couple of schooners this evening, to switch this blog over to it. The Mythos theme is good, and the changes I made to the index page to display posts in a similar way to Scripting News was an interesting experiment, but I don’t think it fit the type of site I wanted. I’ll give the card theme a try and see if it’s a better fit for me.
 screenshots
screenshots -
You know how everyone compares the price of their subscription to a cup of coffee? How would that work for ChatGPT Pro and it’s $200 USD /month plan? “It’s like a cup of coffee, if all you do every day is drink coffee.” (Actually, it works out to about $6 a day, so it really is like a daily coffee).
-
It’s funny how I approach certain features in the tools I make, such as adding UCL to Dynamo Browse. It’s been several months since I’ve done this, and I haven’t really used it for anything substantial until today. I guess because I get the sense that it’s half-finished (mainly due to the fact that it is half-finished) I tend to approach such features gingerly: in a careful way so as to avoid any problems. That’s probably not the best way to approach these features though. They need to be taken through the ringer, and just used, lest I never find their limitations or bugs that need to be fixed.
Anyway, this is a long winded way of saying that I’m glad I actually replaced the old scripting engine in Dynamo Browse with UCL. It was added to be used, and it actually came in useful today.
-
Speaking of Japan, after watching a “cab ride” (driver seat ride?) of a bus travelling from a Shibuya to Haneda Airport, YouTube’s been serving me nothing but cab rides of other Japanese public transport systems. I did enjoy this one, of the suspended railway between Ōfuna and Shōnan-Enoshima.
-
Japan has been an extremely popular travel destination for those I work with. I think about half the office has either travelled to, or are planning trips to Japan this year. It would be nice to go back some day. Maybe see more than the conference rooms of Tokyo.
-
It’s amusing to hear Ben Thompson quip that “no one got fired from using us-east-1, at least until now.” But the instability of that AWS region has been known for some time now. In fact, most AWS engineers I know tend to stay away from that region entirely, unless they have no choice.
-
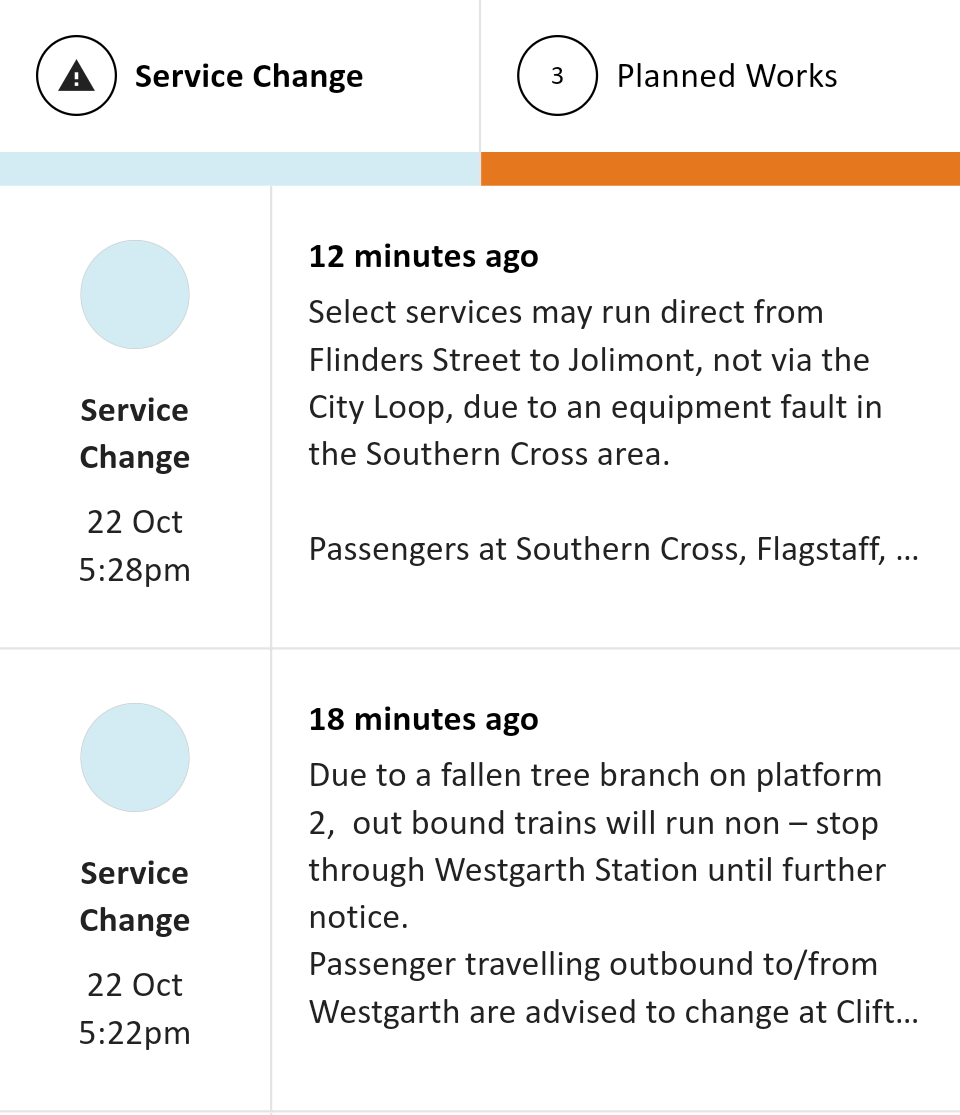
Whew! Made it home. A bit of a delay but given the strong winds, it’s fortunate that the commute wasn’t longer than it was. Could’ve been much worse. Good thing that large tree branch didn’t fall on the train line (it was close enough to brush against the side of the train).
 screenshots
screenshots -
Riding the python today. Hoping the gopher doesn’t mind.
-
Walking to work looking towards the CBD and 367 Collins St. Saw some birds gliding near the top of the building. Wonder if that’s the peregrine falcons, back in town to nest.
-
This sounds ominous. Does this mean more unsolicited push notifications in iOS or promotional crap added to Apple Maps? As someone who aims to not know when an F1 race is happening, it's a good indication that an iPhone is not for me.
Also, F1 in Apple Fitness? How’s that going to work? Maybe F1-related routines. “Run in a circle like an F1 car! Quick, bend over like your refilling or changing tyres.”
-
It would be nice if wiki editors offered more control over the document structure as a whole, such as moving entire sections — everything from one H1 to another H1 — around the document without copying and pasting. Perfect feature for the table-of-contents outline maybe.
-
📘 Devlog
Godot Game - Working On Backdrops
Trying my hand in making some mountainous backdrops for world 3. Continue reading →
-
I’ve never noticed how many barbers there are around here (South Melbourne). This block alone there are three, and I know of two more nearby.
-
You truly don’t know what you had until it’s gone. Case in point: the touch-bar on my work MacBook was not working at all last week, and It was during that time I realised how often I actually used it to lock the screen. It’s back today, meaning I no longer need to lock it via the Apple menu.
-
I was thinking about the gatekeepers of video content online when I was speaking with someone at a party yesterday. Several years ago, he made a documentary which he was trying to sell via DVDs on his site, where he was making nothing at all. It did eventually get picked up by Amazon Prime, but it didn’t really go anywhere until they decided to promote it a little. It took off after that, but even then, the returns he was seeing were quite small. He didn’t give an exact figure — I think it was more than what he was making from DVDs — but it didn’t seem enough to cover the cost of production or make a living out of it. He’s hardly a house-hold name, so it wouldn’t have commanded a large payout anyway, but he was lamenting that it was easier making more a decade ago. The story ended with him asking me how one can make a sustainable living this way.
I wish I had an answer for him. People go to where the content is, and for this sort of video material, that’s the streamers of the world: Netflix, Amazon Prime, Apple TV, etc. And you’re completely at the mercy of the algorithm with those platforms, along with what they choose to promote. I suppose he could’ve tried creating buzz by releasing clips on YouTube, and maybe trying to convince people to go to his website and purchase a DVD (although to be fair, he may have already tried that).
I wanted to say “just put it on your website.” But I couldn’t see that helping him. I mean, the DVD’s weren’t selling, although I can’t imagine DVD’s being enticing to anyone that’s not a avid fan of physical media. And I’ve not watched his documentary, but knowing him and the type of shows he produces, I can’t see it being enough for people to setup a subscriptions to watch it. It wouldn’t work with this material, and subscriptions really only work if what you’re producing is timely: weekly, fortnightly, etc. (well, I guess there are exceptions: I’m a Patreon subscriber to CGP Grey and the last video he release was about a year and a half ago).
Anyway, I don’t really have a point here other to say that it’s rough out there. Hope things improve for him.
-
I cannot support the idea of Apple trying for exclusive F1 rights worldwide. Not that I care about watching the race, but the F1 is so effin’ disruptive here the least they can do is keep it on public broadcast television.
-
It'd be amusing to ponder, given how podcasts all have a video component now, that if Apple did name their new box "Home Pod," in 5 years time, would people think the "pod" in "podcasts" refers to that? Everyone's referring to their shows as "pods" now I do wonder if they're forgetting where "pod" originated from.
videos podcast-clips -
Eastern rosella sighting. Not that they’re uncommon, but they are a little camera shy.
 photos
photos
