
-
Is “deregistration” a word? I always though it was, and online searches seem to suggest that it is. Yet MacOS’s spellchecker considers it a spelling error of “reregistration”. Odd, though not wholly surprising. Maybe I should be using “unregistration,” which doesn’t get the red underline.
-
What is this?
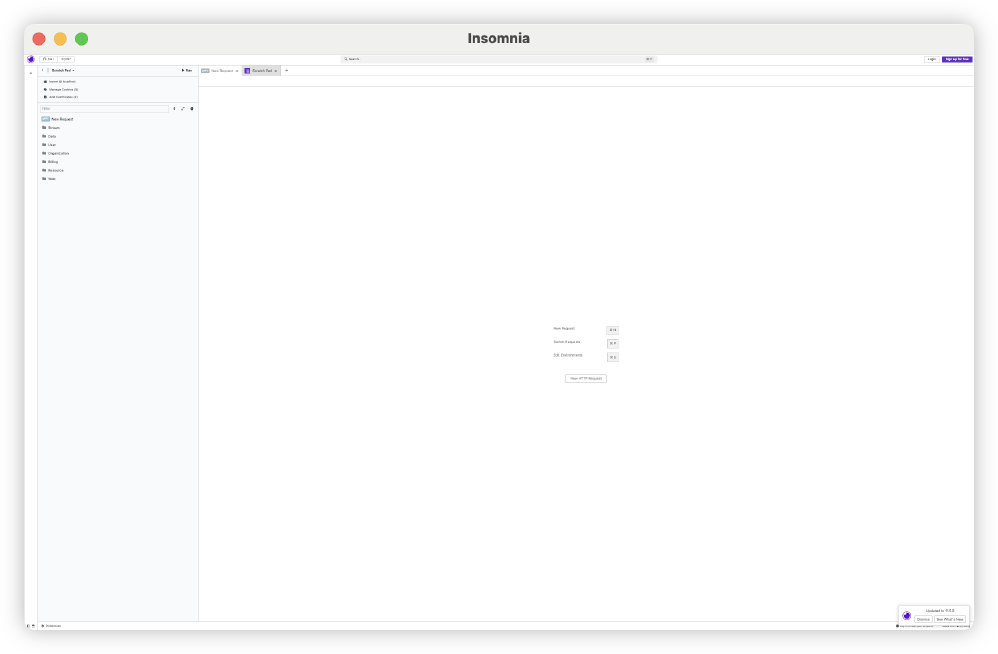
A UI for ANTS?! 😼
Turned out it was just the zoom level. Didn’t even know Insomnia supported a zoom level.
-
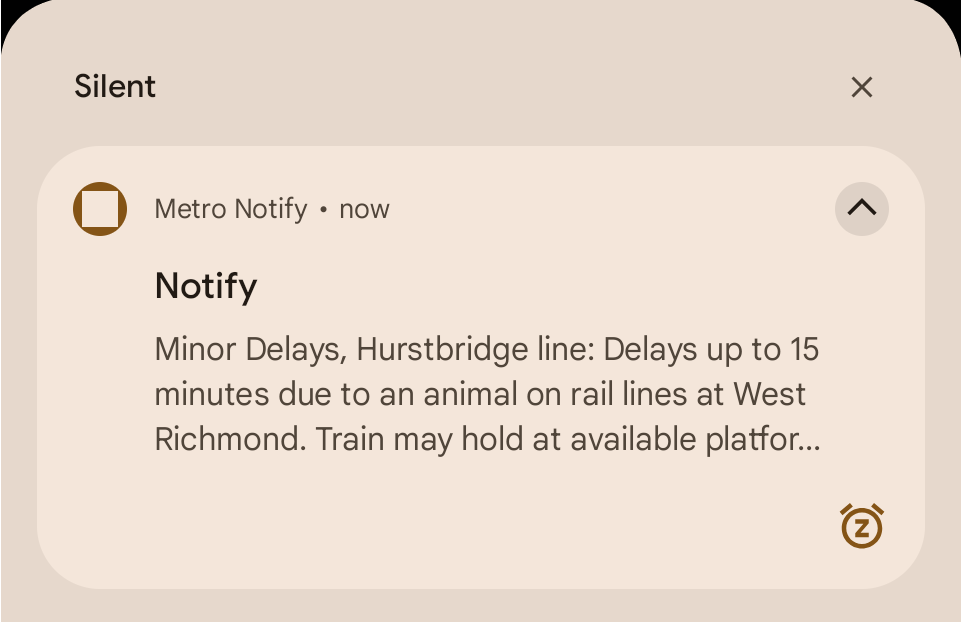
It’s not unheard of to have animals, usually kangaroos, on our line near the down end where it’s quite bushy. But this is well within the inner city. I wonder what it could be. 🤔
 screenshots
screenshots -
📘 Devlog
Godot Project — Bricks in Level 2-3 Laid
Just a quick update today. I’ve finished all the brickwork in level 2-3. And it didn’t go too badly. Made one significant mistake which would’ve involved a lot of rework, that I patched up with some single tiles:
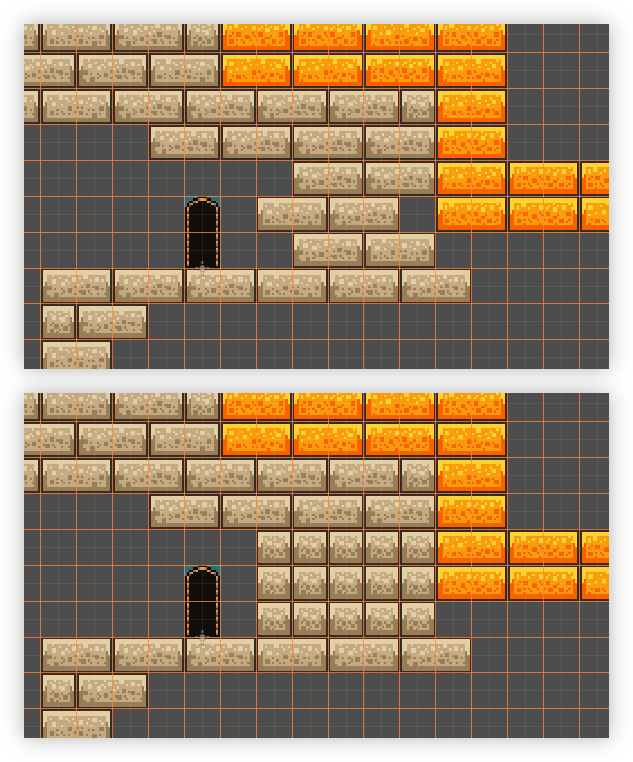
Top: the mistake. Bottom: the fix. Doing the rest of it was pretty dreary work. Godot does have some tools to make this easier, but there was no getting around the level of care needed to place the bricks correctly. But it’s all pretty much done now. And just for comparison to the before screenshots I took when I started, here’s how how the level looks now:
Continue reading → -
Not sure how PTV is expecting people to pay the tram fare when half the Myki readers are non-functional.
-
Nice to think that we’ve finally reached the paperless office future we’ve all dreamed of, yet we still struggle to make sure things look good printed out because we’re now passing files as PDFs.
Why yes, I am trying to make a good looking PDF export from Confluence.
-
Virtual machines of early PC operating systems, such as Windows and OS/2 1.0, that run in the browser. For anyone else who’s interested in a nostalgic kick. Don’t forget to check-out the list of included software installable via the virtual floppy drive.
links -
Timed my morning coffee perfectly today. Was able to photograph the steam train heading to the Wattle Festival this morning. It was pulling a Tait set, a rare sight for my eyes.

 photos
photos -
📘 Devlog
Shutting Down Nano Journal
With the move to Obsidian for my journalling needs, I shut down my bespoke journalling web-app. I deployed it on 26th August 2024, which makes it just over a year old. I did start using Obsidian on the 20th though, so it didn’t quite make it the entire year. Even so, not bad for something hand made and somewhat neglected. Most things I eventually abandon last way less than that.
Continue reading → -
🔗 Ludipe: Intro to Puzzle Design
Filing this under good tips for game development.
Via: GMTK weekly digest.
links -
I just love these posts on game development making comments about the hardest part being the programming. Mate, I wish the hardest part of game development is the programming. For me, it’s by far the easiest. It’s everything else that I struggle with.
-
On the mailing list for someone who releases weekly digest newsletters using both Patreon and Substack. Both are now truncating the email, requiring me to click through to read the entire thing. Seems like a terriable middle ground between a newsletter (read the whole thing in my email client) and a website (read the whole thing in an RSS reader).
-
Words I’ve been misspelling all week:
- Utilization
- Prometheus
And for today, a word that I thought I misspelt but I actually got correct: Thanos.
US spelling intentional.
-
I shutdown my work laptop over the weekend, which means I usually start the week with zero projects open in my IDE. By the end of the week, the open project count is always much higher than I expect and I never remember how it get so high. This week, the count is 18 open projects.
-
Really enjoyed Brent Simmons post about his experience with Frontier. I really like the idea of sorts of software tools that provide so much customisation that a user can really make it their own.
-
Decided to move my journal over to Obsidian, taking up one of the 8, now 7, remaining vaults I have on my Obsidian Sync Plus plan. So far, so good. Offers a pretty decent writing experience — a nice thing about using Day One — while allowing entries to be plain Markdown files — which is nice about my bespoke solution. There are also some nice features with using a native app, such as having it launch on login, ready to start a new entry at a click of a button.
-
I wonder if anyone finds being an actor in stock footage ambitious. Guess it’s much like being an actor that just does commercials.
-
I can understand why Google’s choosing to block sideloading unverified Android apps, but this still disappoints me. The whole reason why I chose Android over iOS is the ability to side-load apps. Not sure what I’m going to do about this change.
-
📘 Devlog
Godot Project — Level 2-3 Update
-
A recent scramble for the need of activity on Slack, yet no-one knows what activities need doing. Choosing this course of action:
 memes
memes -
Tests failing on the build server so I’ve reverted to print debugging to find the cause. Part of me feels a bit dirty using this form of debugging, but there’s no doubting it’s effectiveness.
-
Tempting fate by walking out of the house without an umbrella. Deliberately, I might add. Is no umbrella better than a broken umbrella? 🤔
Hmm, might be that a broken umbrella is better. 🌧️
-
Oof! $149.00, paid to Apple for the right to notarise apps. Problem here being that I’ve not notarised any apps recently. Probably should release something, just to get my money’s worth.
Maybe I’ll vibe-code something. 😛
-
Today I had the pleasure of driving this:


An oil-fired steam locomotive. Drove it from Castlemaine to Maldon, round-trip of about 40 km, as part of the driving experience offered by the Victorian Goldfields Railway. Very fun. Was anxious about it at first but turned out to be a great experience.
photos
