
-
Kyneton Botanical Gardens
Went to Kyneton with Mum and Dad today. While they went off for a bike ride, I had the opportunity to go for a walk around the botanical gardens. This was my first time there, and although the gardens themselves were not very big, it was still a pleasant experience. Here are some photos I took of that visit.
















This was followed by lunch at Little Swallow Cafe. The place was quite busy — I suspect that their reputation is such that it would be busy most of the time — but the food was very nice. We then went for a short walk around Kyneton and then drove to Malmsbury for a coffee and Devonshire tea.
Continue reading → -
DynamoDB JSON Attribute Types Quick Reference
Because apparently it’s too difficult for AWS to provide an easy way to find this information.
Atomic Types
Type JSON Value Binary BString value containing the Base64-encoded binary data. Boolean BOOLEither trueorfalseString SString value Number NString with the numerical value Null NULLShould always be trueCollection Types
Type JSON Value List LA JSON array, with each element being an attribute with a type. Map MA JSON object, with the keys being the map keys, and the values being an attribute with a type. Set Types
Type JSON Value Binary Set BSA JSON array of Base-64-encoded binary data. Number Set NSA JSON array of string with the numerical values. String Set SSA JSON array of strings. Sources:
Continue reading → -
More Complaining About Autocorrect on MacOS
Earlier this morning:
Me: (writing in my journal) Nonna, my 91 year-old grandmother…
Autocorrect: Did you me “Donna”?
Me: No, undo change. (continue writing) good news is that Nonna…
Autocorrect: Did you me “Gonna”?
I can forgive MacOS for considering nonna a spelling error, since it’s not an English word.
But I do see why auto-correct on MacOS can be frustrating. Apart from the two completely random corrections it made for the same word, it also doesn’t seem to get the hint when I undo the change. I would have thought that action is a pretty strong signal from the user to just leave the word alone, at least for the moment.
Continue reading → -
Write It Down
I am feeling some very minor after-effects from the booster I took yesterday (nothing serious, just the expected cold-like symptoms). I was curious as to whether it was anything like I experienced in January, when I got my last booster. I went to my journal to see what I wrote about it. Unfortunately for me, there was nothing there.
To be fair to my past self, there were some other events going on at the same time which I did write about. But I was left pondering this morning about why I didn’t write anything about how I was feeling back then. My guess is that I probably didn’t think it was worth writing about at the time. “Feeling a little off” was probably something that I thought was quite trivial, and wouldn’t be relevant later on.
Continue reading → -
Newsletter Reminder Emails
I subscribe to a newsletter that sends “reminder” emails if I skip an issue. If I don’t open one of the email newsletters I receive, then a few days later, a copy will be sent with a forward of the form “looks like you skipped an issue. Here what you missed.”
These reminder emails are bad, and here’s why:
-
It gives the impression of hustling me. I appreicate the time you take to publish something that I see value in, but sending these reminders feels like your forcing your content onto me. Like I just got to read this content. Really, you must read it! And, oh! You forgot this one day? Well I’ll make sure you don’t forget it (and me) again. Please, back off! I’ve received your content and I’ll get to it when I get to it, if I feel like it, after I’ve read all the other newsletters I received. Please don’t push me to read it on your schedule.
Continue reading →
-
-
The Feature Epic (Featuring the Epic Feature Branch)
Here’s what’s been happening at work with me recently. I write it here as an exercise in how I can learn from this. They say that writing can help in this respect so I’m going to put that logic to the test (in either case, just having this documented somewhere could prove useful).
We’re working on a pretty large change to the billing service powering the SaaS product sold by the company I work at. Along with our team, there are two other teams working on the same service at the same time, making any changes they need to release the product stuff they’re working on. All our teams had our own deadlines — which are pretty pressing — to get stuff delivered either last month or sometime this month.
Continue reading → -
Arriving Late
I’m going to have to tell my boss today that the stuff my squad has been working on is going to arrive late. To much needs to be fixed or reworked, and there is one or two things that have been missed alltogeather.
I think the biggest problem is that the thing we’ve been working on got into testing far too late — only a few days before the deadline — meaning that there was no time left for fixing things. Really, you can draft all the plans and designs you want but you really don’t know how well it will perform until the “working” code has been handed to someone else.
Continue reading → -
Wrong Number
Got called three times this morning by mistake from an old woman in NSW trying to contact her son who had a very similar phone number to mine.
First time I ignored it as I didn’t recognised the number and thought it was spam.
Second time I answered and after trying to understand what she was trying to say, I simply said “I think you got the wrong number, sorry” and hung up.
Continue reading → -
Honour, Democracy, and Galati: A Day in Canberra
Since being in Canberra, I haven’t really done anything “touristy”. Given that today was a public holiday, I figured it was as good a time as ever to do so. So I decided to spend the day visiting a couple of national landmarks, plus something I’ve been planning to do since returning to Canberra.
The War Memorial
The first time I’ve ever been in Canberra was during Christmas holidays in 2007 my family. During that time, Mum and Dad and my two sisters went to the War Memorial and Parliament House, while I stayed in our rented town-house. The reason why I stayed back was a little embarrassing: I claimed that I was tired, but this was during a weird period where I didn’t really want to be seen doing something touristy (I’ve mostly got over this feeling). Not going when I had the chance was something I’ve regretted since that day. Well, today I make amends with at least one of these, with a visit to the War Memorial.
Continue reading → -
Afternoon Walk Around Lake Ginninderra
Went for an walk around Lake Ginninderra this afternoon. Well, not “around” the lake: that walk would have taken a while. But I did walk along the path that would take me around the lake for about 30 minutes, then walked back again. Below are a few photos I took.
Continue reading →












-
My Evening
So here’s how I spent my evening:
Watching the WWDC state of the union until the DNS resolver konked out in the WiFi router, causing the Chromecast to get into a state in which it could no longer connect to the network, resulting in about 10 minutes of troubleshooting before deceiding to clean up, not go to the gym, spend another 10 minutes trying to troubleshoot the issue, then stared at my laptop for about half an hour wondering whether to go back to troubleshooting the Chromecast, or doing something else with the hope that it would eventually work itself out.
Continue reading → -
The Powerline Track Walk
Went on a walk of the Powerline Track, which I was personally calling the “powerline walk” (yes, I’m impressed at how close I was). I saw this trail when I was in Canberra earlier this year, and knowing that I would be back, I made a note to actually walk it, which I did today. This track follows the powerlines just south of Aranda Bushland Nature Reserve, then goes under Gungahlin Drive and into the Black Mountain Nature Reserve. The weather was cold but pleasant, at least at the start of the track. It eventually got quite dark and a little wet near the end, but that did result in some nice winter lighting over the landscape.
Continue reading → -
Humour In Conference Videos — Less Is More
It might be just me but I get a little put off with over-the-top attempts at humour in developer conference videos.
I’m four minutes into a conference video which has already included some slap-stick humour (with cheesy CGI), and someone trying to pitch to me on why what they’re talking about is worth listening to. This was done in such a way that it actually distracted me from the content, a.k.a. the reason why I’m watching it.
Continue reading → -
Cloud Formation "ValidationError at typeNameList" Errors
I was editing some Cloud Formation today and when I tried to deploy it, I was getting this lengthy, unhelpful error message:
An error occurred (ValidationError) when calling the CreateChangeSet operation: 1 validation error detected: Value ‘[AWS:SSM::Parameter, AWS::SNS::Topic]’ at ’typeNameList’ failed to satisfy constraint: Member must satisfy constraint: [Member must have length less than or equal to 204, Member must have length greater than or equal to 10, Member must satisfy regular expression pattern: [A-Za-z0-9]{2,64}::[A-Za-z0-9]{2,64}::[A-Za-z0-9]{2,64}(::MODULE){0,1}]
Continue reading → -
GitLab Search Subscriptions with NetNewsWire
I’m working (with others) on a project that’s using GitLab to host the code, and I’m looking for a better way to be notified of new merge requests that I need to review. I cannot rely on the emails from GitLab as they tend to be sent for every little thing that happens on any of the merge requests I am reviewing. For this reason, any notifications sent by email will probably get missed by me. People do post new merge requests in a shared Slack channel, but a majority of them are for repos that don’t need my review. They’ve also been days where a lot of people are making a lot of changes at the same time, and any new messages for the repos I’m interesting would get pushed away.
Continue reading → -
What Would Get Me Back to Using Twitter Again
Congratulations, Elon Musk, on your purchase of Twitter. I’m sure you’ve got a bunch of ideas of how you want to move the company forward. I was once a user of Twitter myself — albeit not a massive one — and I’m sure you would just love to know what it would take for me to be a user once more. Well, here’s some advice on how you can improve the platform in ways that would make me consider going back.
Continue reading → -
Showing A File At a Specific Git Revision
To display the contents of a file at a given revision in Git, run the following command:
$ git show <revision>:<filename>For example, to view the version of “README.md” on the
devbranch:$ git show dev:README.mdThere is an alternative form of this command that will show the changes applied to that file as part of the commit:
$ git show <revision> -- <filename>This can be used alongside the log command to work out what happened to a file that was deleted.
Continue reading → -
Code Review Software Sucks. Here's How I Would Improve It
This post is about code reviews, and the software that facilitates them.
I’ll be honest: I’m not a huge fan of code reviews, so a lot of what I speak of below can probably be dismissed as that from someone who blames their tools. Be that as it may, I do think there is room for improvements in the tooling used to review code, and this post touches on a few additional features which would help.
Continue reading → -
Broadtail 0.0.7
Released Broadtail 0.0.7 about a week ago. This included some restyling of the job list on the home page, which now includes a progress bar updated using web-sockets (no need for page refreshes anymore).
For the frontend, the Websocket APIs that come from the browser are used. There’s not much to it — it’s managed by a Stimulus controller which sets up the websocket and listen for updates. The updates are then pushed as custom events to the main
Continue reading →window, which the Stimulus controllers used to update the progress bar are listening out for. This allows for a single Stimulus controller to manage the websocket connection and make use of thewindowas a message bus. -
Learning Through Video
Mike Crittenden wrote a post this morning about how he hates learning through videos. I know for myself that I occasionally do prefer videos for learning new things, but not always.
Usually if I need to learn something, it would be some new technology that I have to know for my job. In those cases, I find that if I have absolutely no experience in the subject matter, a good video which provides a decent overview of the major concepts helps me a great deal. Trying to learn the same thing from reading a lengthy blog post, especially when jargon is used, is less effective for me. I find myself getting tired and loosing my place. Now, this could just be because of the writing — dry blocks of text are the worst, but I tend to do better if the posts are shorter and formulated more like a tutorial.
Continue reading → -
Some More Updates of Broadtail
I’ve made some more changes to Broadtail over the last couple of weeks.
The home page now shows a list of recently published videos below the currently running jobs.
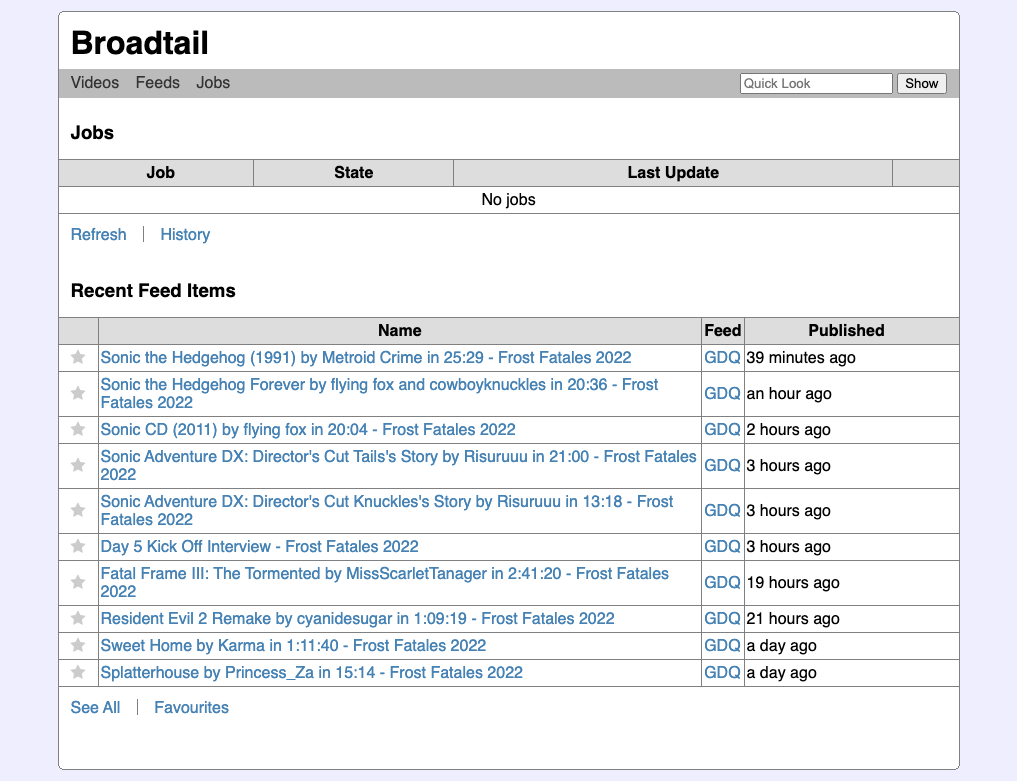
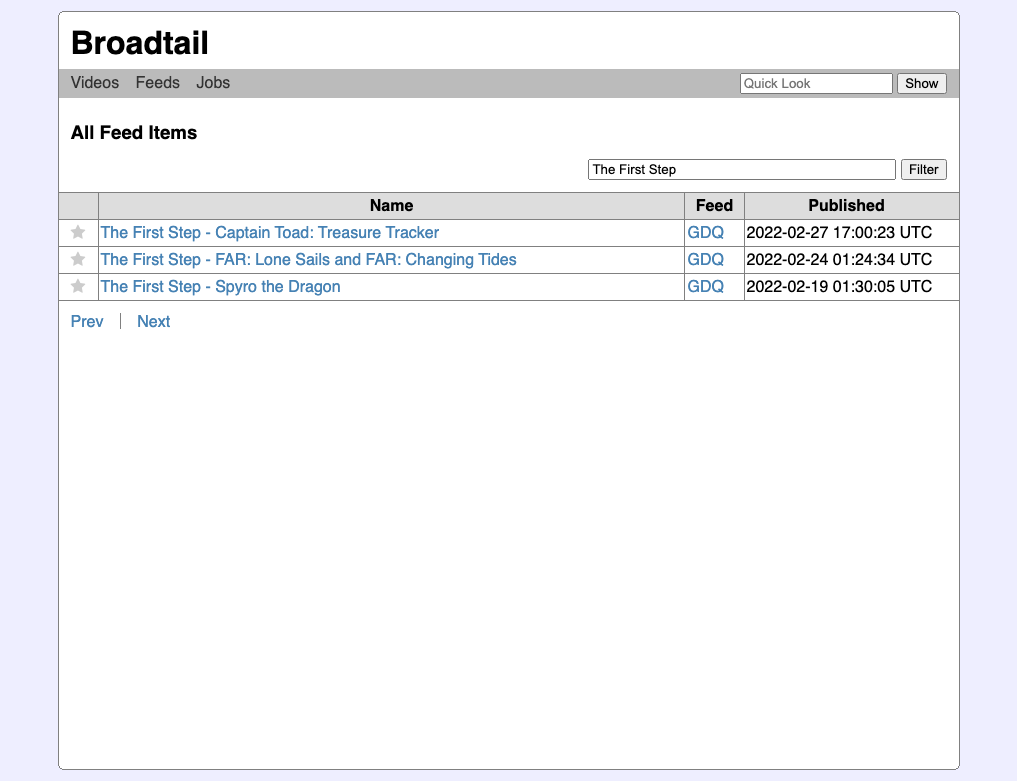
Clicking through to “Show All” displays all the published videos. A simple filter can be applied to filter them down to videos with titles containing the keywords (note: nothing fancy with the filter, just tokenisation and an OR query).
Finally, items can now be favourited. This can be used to select videos that you may want to download in the future. I personally use this to keep the list of “new videos” in the Plex server these videos go to to a minimum.
Continue reading → -
Time and Money
Spending a lot of time in Stripe recently. It’s a fantastic payment gateway and a pleasure to use, compared to something like PayPal which really does show its age.
But it’s so stressful and confusing dealing with money and subscriptions. The biggest uncertainty is dealing with anything that takes time. The problem I’m facing now is if the customer chooses to buy something like a database, which is billed a flat fee every month, and then they choose to buy another database during the billing period, can I track that with a single subscription and simply adjust the quantity amount? My current research suggests that I can, and that Stripe will handle the prorating of partial payments and credits. They even have a nice API to preview the next invoice which can be used to show the customer how much they will be paying for.
Continue reading → -
Cling Wrap
I bought this roll of cling wrap when I moved into my current place. Now, after 6.5 years and 150 metres, it’s finally all used up.

In the grand scheme of things, this is pretty unimportant. It happens every day: people buy something, they use it, and eventually it’s all used up. Why spend the time and energy writing and publishing this post to discuss it? Don’t you have better things to do?
Continue reading → -
Trip to Ballarat and the Beer Festival
I had the opportunity to go to Ballarat yesterday to attend the beer festival with a couple of mates. It’s been a while since I last travelled to Ballarat — I think the last time was when I was a kid. It was also the first time I took the train up there. I wanted to travel the Ballarat line for a while but I never had a real reason to do so.
Continue reading → -
OS Vendors and Online Accounts
Looks like the next version of Windows will require an online account, and while the reason for this could be something else, I’m guessing this would be used to enable file sync, mail account sync, calendar sync, etc.
I think it’s a mistake for OS vendors to assume that people would want to share their sole online identity across different devices. Say that I had a work computer and a home computer, and I’d use the same online account for both. Do I really want my personal files and work files being synced across, or my scheduled meetings to start showing up in my personal calendar?
Continue reading →