
-
Just bought a domain name which assumes UK English spelling, and then it occurred to me that I probably need to get the name spelt in US English as well, since it’s different. So that’s two new domains today. Should’ve thought of that before I chose the name. 🤦
-
Spending some time this morning working on the layout of a new Hugo site. I must say I’m pretty impressed by Hugo’s capabilities. So far I haven’t encountered any blockers on what I’d like to achieve. I guess the trick is trying not to fight it too much.
-
I’m starting to suspect that my wandering eye for blogging CMSes is driven less by the features of the software itself and more by the style of the available themes. Maybe instead of signing up to yet another one I can improve my visual design and CSS skills.
That said, I’d still be interested in how each CMS works, just from a user experience design point of view. Maybe someone can start a YouTube channel where they go through each CMS out there and do a bit of a review. That way, I don’t have to do it myself. 😛
-

Currently reading: Evil Plans: Having Fun on the Road to World Domination by Hugh MacLeod 📚
This was the book that was easier to get as atoms rather than bits. But I got it in the end and I’ve started reading it yesterday. So far it’s pretty good. Very much written in the same way as Ignore Everybody, which is a style I quite like. It’s a bit more business development-ee than what I was expecting but honestly this is a topic I’ve been curious about for a little while now.
-
🔗 Twitter suffers major outage in Australia and New Zealand
I was about to make a joke about Twitter not paying their PagerDuty bill. But then it occurred to me: you probably don’t even need PagerDuty if you can just hear about outages from the news.
-
Anyone who wants to start a public relations firm, here’s a free name for you: The Boast Office.
-
Back to work today, and first cab of the rank is a design task. I use to start writing notes of the design in Atlasssian Confluence, but today I think I’ll try writing my design notes in Obsidian first. Once I’m got something together, I’ll take these notes and D2 diagrams and use them to produce a proper write-up in Confluence to share with others.
It is a form of double handling, but the distinct roles of both tools might be helpful to me. There’s no expectation for a coherent and complete design from my Obsidian notes, and the low friction that comes from the Markdown editor is more conducive to the mode of thinking I’m in when I’m coming up with a design.
The Confluence editor is just too rigid for that. And don’t get me started on the point-and-click diagramming tools that are included in it. They’re much more suited towards preparing the finished artefact.
Anyway, we’ll see how this goes.
-
Until recently, I’ve been using Mastodon via the web-app on my phone. And credit to the Mastodon developers for making a pretty decent progressive web-app. But all this talk about Ivory has given me, an Android phone owner, a bit of FOMO so I though I’d look for a native client.
I first gave the official Mastodon client a try. And yeah, it works. The login flow was pretty seamless. But there were a few things about it that I didn’t like.
For one, there was no obvious way to look at posts on the local instance. This is something I occasionally do, just to see what’s happening on the instance. I probably only get value for this because my instance is social.lol, which is comparatively small and requires payment to join. For those on instances like mastodon.social, this may be less useful.
But aside from that, there are also some layout issues as well. One that annoyed me was that some posts took up a large amount of space for no apparent reason, almost like there should’ve been an image:
I guess it assumes that the link references an image? So the official client was out, and after asking for recommendations on the Hemispheric View Discord, I gave Tusky a try. And so far I really like it. It’s got a dedicated tab for posts on the local instance and the UI itself is pretty nice. It reminds me a little of the official Twitter app (make of that what you will).
So far I’ve only used it to browse the timeline. I haven’t had a deep enough look at the features like posting, replying, or muting, so I can’t say if it’s works in that respect. But I think I’ll stick with Tusky for the time being.
-
Looking for my 2023 word. The one at the top of the list is “travel”. I could pick this one as I do have a significant trip planned this year. But it kinda feels less like I’m picking it, and more like it’s being picked for me. I might look for another one.
-
On Posting Here Daily
I sometimes struggle with the idea of trying to post here at least once a day. While perusing my archive I find days where my posts are cringeworthy or just not good, and part of me wonders whether it’s better to wait for a post to meet a certain level of quality before publishing it. I have also seen this argument from other bloggers as well. They post the rules they have that include things like “it should start a conversation” or it should be “distinctive”. Continue reading →
-
First post of 2023. If current trends are to be maintained, I better get posting right away. 😉
Happy new year.
-
2022 Year In Review
I’ll be honest: these year in review posts feel like going to the dentist. I generally hate doing them, but I know that it can be good exercise to reflect on the past year. I think one thing in my favour is that I’ve actually kept my blogging — and to a lesser extent, my journalling — up to date so I’ve actually got something that I can refer back to. Continue reading →
-
Don’t like becoming a “regular” at cafes. It’s nice while you’re going there, but you ineviably move on and start going someplace else. But your new place closes for New Year’s Eve, and since the old one is the only one open, you go back for your coffee. It always feels awkward.
-
It’s been a while since I’ve used Pinboard to track a link. I found myself using other things for this. temporary links go to Obsidian, podcast episodes I like to listen to again I’ve got something bespoke for now, and links of note go here. I found this system works quite well.
-
Only slept three or so hours last night, and yet it feels like I got a lot done today. Funny how that can occur. Maybe it’s the feeling that if I were to stop, I’d might want to nap or something. And waking from a nap without feeling awful is just something I can’t do.
-
Check this one off the bingo card: responding to PagerDuty alert during the Christmas break to do routine production support work. 🧑💻
-
Poking Around The Attic Of Old Coding Projects
I guess I’m in a bit of a reflective mood these pass few days because I spent the morning digging up an old project that was lying dormant for several years. It’s effectively a clone of Chips Challenge, the old strategy game that came with the Microsoft Entertainment Pack. I was a fan of the game when I was a kid, even though I didn’t get through all the levels, and I’ve tried multiple times to make a clone of it. Continue reading →
-
Spent the day restyling the Dynamo-Browse website. The Terminal theme was fun, but over time I found the site to be difficult to navigate. And if you consider that Dynamo-Browse is not the most intuitive tool out there, an easy to navigate user manual was probably important. So I replaced that theme with Hugo-Book, which I think is a much cleaner layout. After making the change, and doing a few small style fixes, I found it to be a significant improvement.
I also tried my hand at designing a logo for Dynamo-Browse. The blue box that came with the Terminal theme was fine for a placeholder, but it felt like it was time for a proper logo now.
I wanted something which gave the indication of a tool that worked on DynamoDB tables while also leaning into it’s TUI characteristics. My first idea was a logo that looked like the DynamoDB icon in ASCII art. So after attempting to design something that looks like it in Affinity Designer, and passing it through an online tool which generated ASCII images from PNG, this was the result:
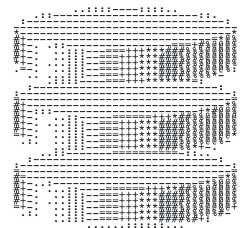
I tried adjusting the colours of final image, and doing a few things in Acorn to thicken the ASCII characters themselves, but there was no getting around the fact that the logo just didn’t look good. The ASCII characters were too thin and too much of the background was bleeding through.
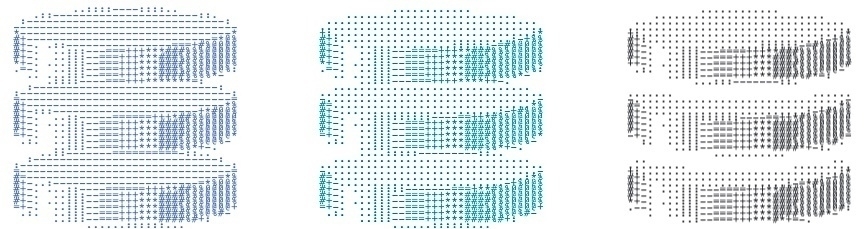
So after a break, I went back to the drawing board. I remembered that there were actually Unicode block characters which could produce filled-in rectangles of various heights, and I wondered if using them would be a nice play on the DynamoDB logo. Also, since the Dynamo-Browse screen consists of three panels, with only the top one having the accent colour, I thought having a similar colour banding would make a nice reference. So I came up with this design:

And I must say, I like it. It does look a little closer to low-res pixel art than ASCII art, but what it’s trying to allude to is clear. It looks good in both light mode and dark mode, and it also makes for a nice favicon.
That’s all the updates for the moment. I didn’t get around to updating the screenshots, which are in dark-mode to blend nicely with the dark Terminal theme. They actually look okay on a light background, so I can probably hold-off on this until the UI is changed in some way.
-
Spent the day updating some Day One entries of my recent trip to the US. Some days effectively had scrawls of an update I wrote while I was over there, so I had something to work on while I was filling in the gaps. The question was should I maintain the present tense of the post?
If I do, then it will seem like I wrote this really detailed entry while I was living the day. And it may make for interesting reading, but it feels dishonest to me (even though it would just be me reading it). I could change it to past tense, which will make it sound more genuine to what it actually is: an entry updated weeks after the actual day. But it may clash with the tense of many of the other entries that were also written on the day.
On the other hand, there were entries written the past tense already, so that window broke ages ago. So I decided to go with past tense.
-
I was about to write something disparaging about threads again (this time about Mastodon threads), and while I personally can’t stand the reading experience, I guess that’s how some prefer to write long-form.
I still prefer to read them as blog posts. Maybe that’s an opportunity for a CMS or blogging tool; one that recreates the experience of writing a thread, and will actually make one when syndicated to Mastodon, but will also publish it as a blog post at the same time.
(Ten minutes later…) Actually, it might be better for this to be something that the Mastodon client offers, since that’s where people are writing threads anyway. Maybe the way it could work is that you can link a blog that supports micropub, and whenever someone writes a thread, the client can offer a way to automatically publish it to your blog. Boom! You’re blogging without blogging.
-
Wishing you all a merry Christmas, a safe and restful holiday, and a happy and prosperous New Year.

-
2022 Song Of The Year
For the past twelve years or so, I’ve been invited to play the organ at the children’s Christmas Eve mass at a local(ish) primary school. During the collection, while people are getting wallets or purses out, I usually play some soft, nondescript music on a muted organ with only a few soft pipes opened. It doesn’t matter what I play during this time so I usually take this opportunity to play a song that I felt was a favourite of mine throughout the year. Continue reading →
-
Reading The Verge article about Twitter adding view counts to tweets (HT Daring Fireball), and hearing from the Twitter dev that most tweets get zero views, reminds me of this Slate article about Twitter users who posted once then abandoned the service.
-
Today I am reminded that sometimes, if you think too much about what you hope to post for the day, you end up not posting anything at all. This self-sabotage can also occur when you’re considering what to do on the morning of your first day off.
