
Day 13: pathway
#mbjune

Hello there. 🦜


I must admit, I was not expecting much when I plugged my iPad into a HDMI and USB hub splitter. Yet I was pleasantly surprised that it had no trouble extending (well, mirroring) the display and enabling keyboard and mouse. It’s not perfect, but it’s better than I was expecting.
Day 12: hidden
#mbjune

If ute is short for “utility” vehicle, then instead of SUV, we should be calling these vehicles “sports utes”.
🔗 Robert Birming: Blog Inspiration
Very nice collection of links to blogging resources — from ideas and inspirations through to colour and icon packs — from @birming. This stuff is cat nip for me, so I’m sure to enjoy browsing these links.
Speaking of avians, I’m back in Canberra, which can only mean one thing: there will be photos of cockatiels.

Every cafe or eatery at the airport uses an avian or aviation theme. Here’s a way to stand out: nautical theme. Having a fish and chip shop with boats and lighthouses will turn heads.
🔗 You’re not a front-end developer until you’ve… - Nic Chan
Scored 17 in this little quiz. Not bad for a backend developer, although many of the questions universally apply.
Via: Jim Nielsen’s Notes
Day 11: brick
Might be pushing the definition of “brick” for this one. #mbjune

🔗 Science: Cockatoos have learned to operate drinking fountains in Australia
Each placed one or both of its feet on the fountain’s twist handle, then lowered its weight to twist the handle clockwise and prevent it from springing back up.
Amazing.

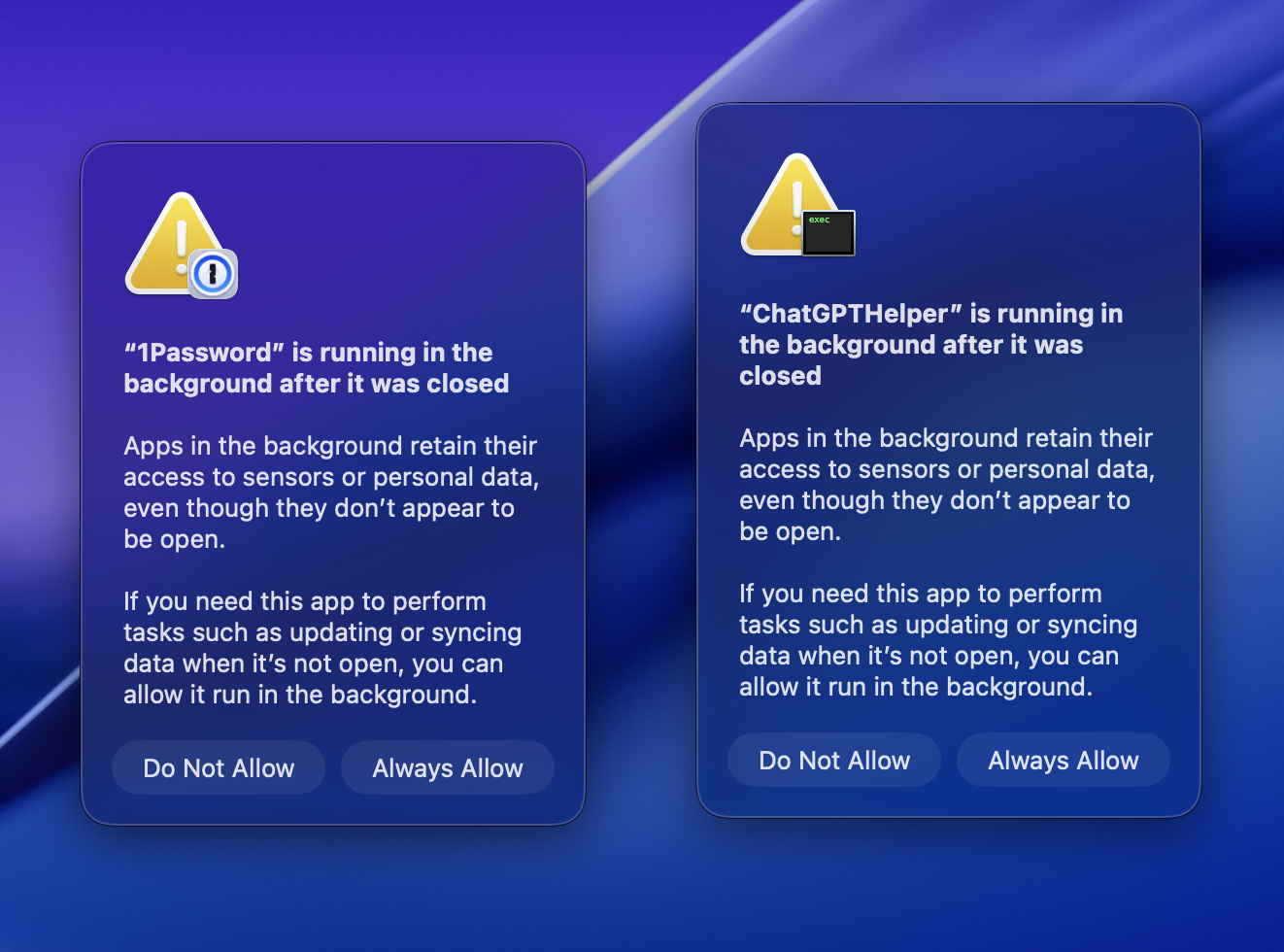
Looking forward to all the fun new permission gates that will show up in MacOS Tahoe. “Your keyboard is trying to use a process on your computer. Keyboards are known to result in modifications to your personal data.” 😛
Day 10: rail
I post a lot of train photos on this site, so here’s one of the other railed vehicles I encounter. #mbjune

That Which Didn't Make the Cut: a Hugo CMS
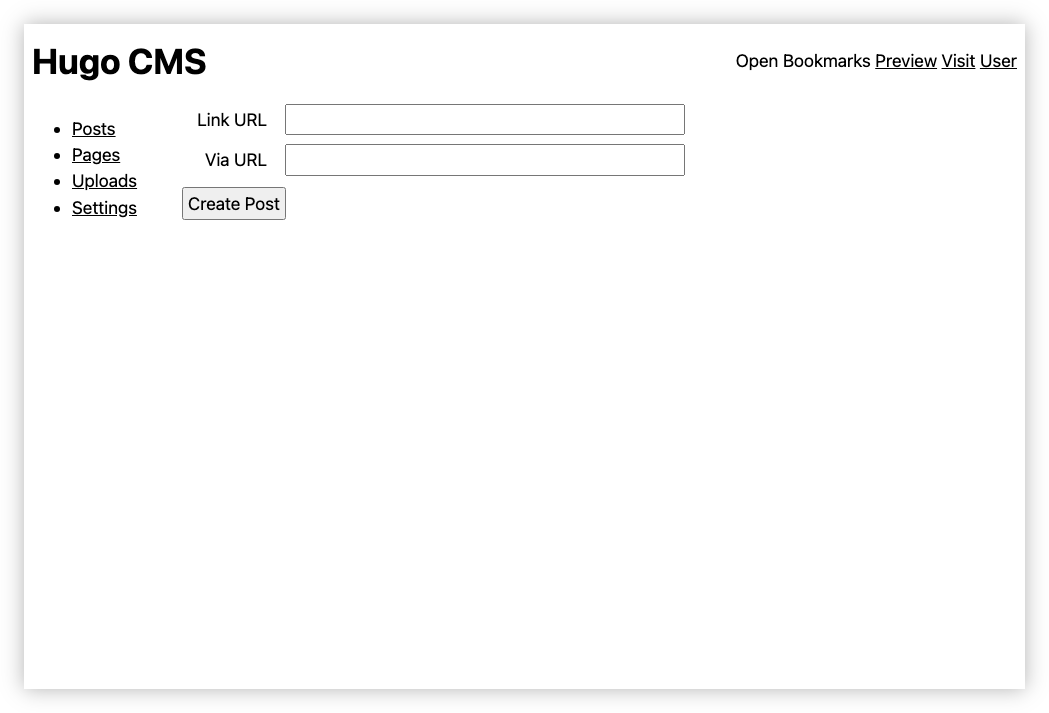
You’ve probably noticed1 that I’ve stopped posting links to Open Bookmarks, and have started posting them here again. The main reason for this is that I’ve abandoned work on the CMS I was working on that powered that bookmarking site. Yes, yes, I know: another one. Open Bookmarks was basically a static Hugo site, hosted on Netlify. But being someone that wanted to make it easy for me to post new links without having to do a Git checkout, or fiddle around YAML front-matter, I thought of building a simple web-service for this.
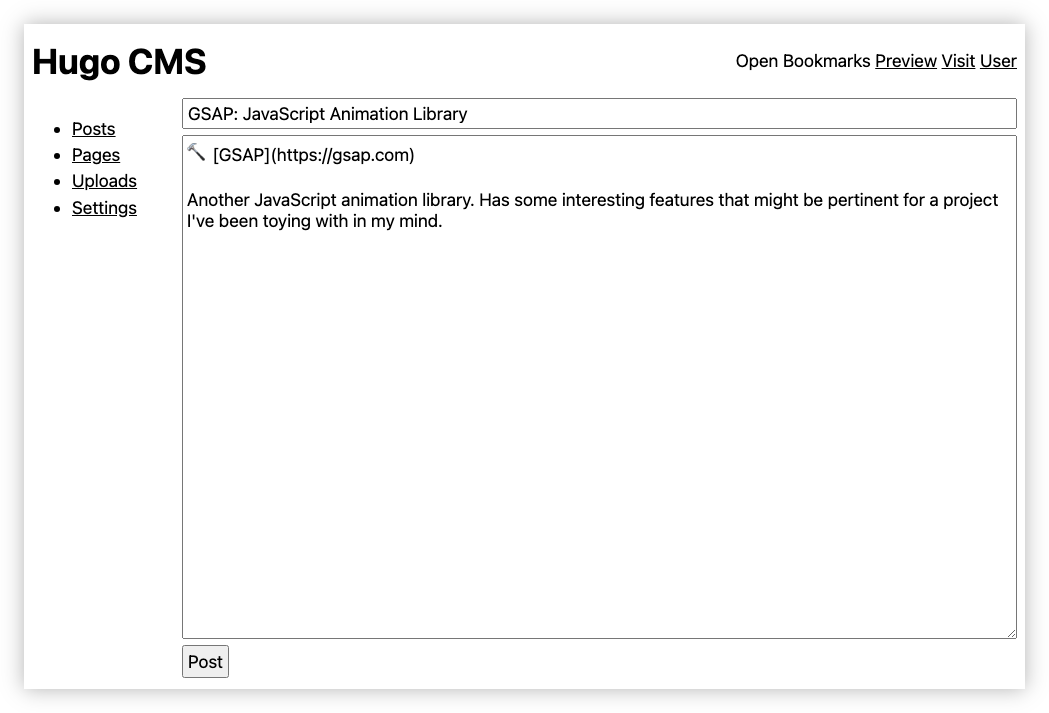
I don’t want to say too much about it, other than I managed to get the post functionality working. Creating a new link post would involve fetching the page, and pre-populating the link and optional via link with the fetched page title. I’d just finish the post with some quotes or quips, then click Post. That’ll save the post in a local database, write it to a staged Hugo site, run Hugo to generate the static site, and upload it to Netlify. There was nothing special about link posts per se: they were just a specialisation of the regular posting feature — a template if you will — which would work the same way, just without the pre-fills.
The other thing I added was support for adding arbitrary pages. This was a dramatic simplification to what is possible in Hugo, in that only one page bundle was supported. And it was pretty compromised: you had to set the page title to “Index” to modify the home page. But this was enough for that, plus some additional pages at the top level.
One other feature was that you can “preview” the site if you didn’t have a Netlify site setup and you wanted to see the Hugo site within the app itself. I had an idea of adding support for staging posts prior to publishing them to Netlify, so that one could look at them. But this never got built.
Finally there were some options for configuring the site properties. Uploads were never implemented.
Here are some screenshots, which isn’t much other than evidence that I was prioritising the backend over the user experience:


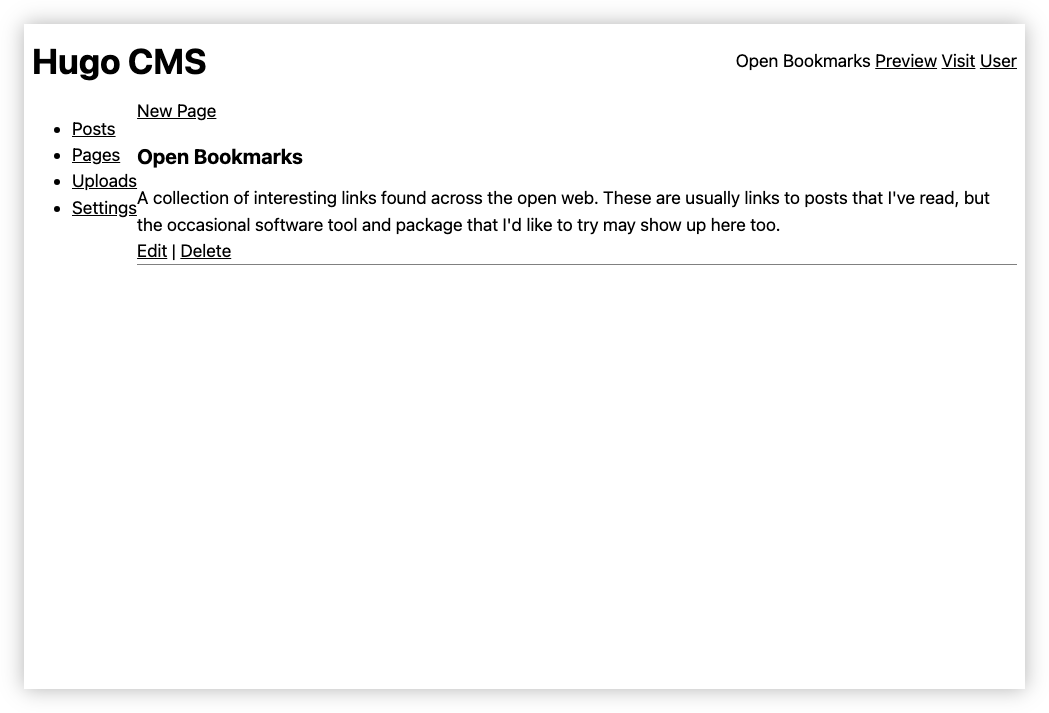
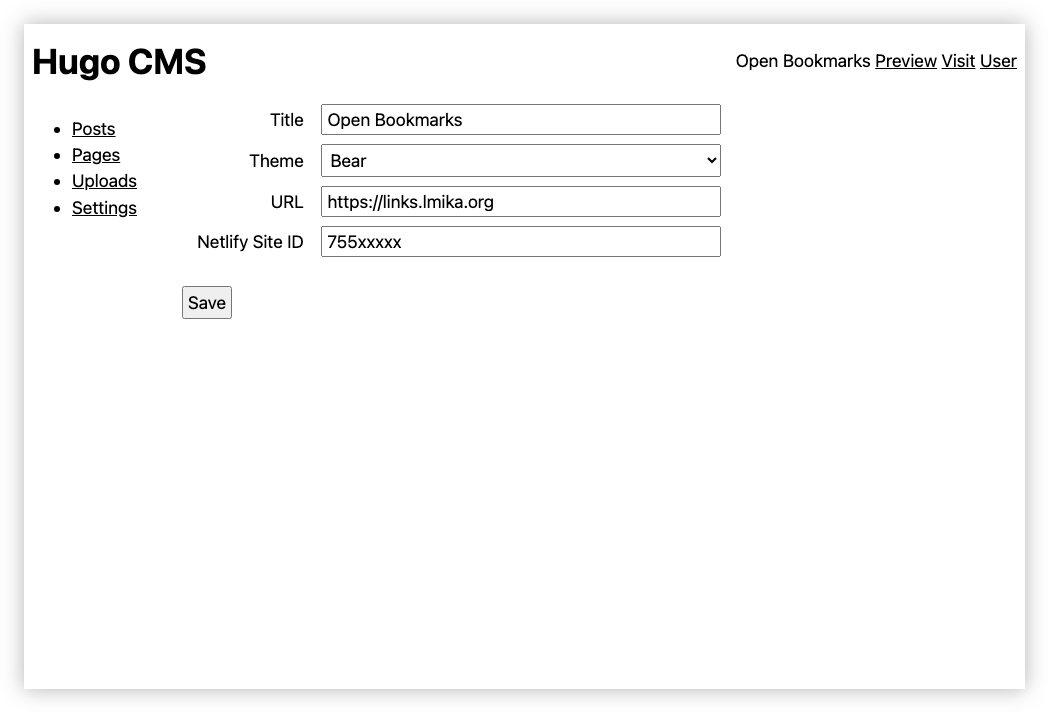
So, why was this killed? Well, apart from the fact that it seemed like remaking prior art — I’m sure there are plenty of Hugo CMSes out there — it seemed strange having two systems that relate to blogging. Recognising this, I decided to add this functionality to Blogging Tools:
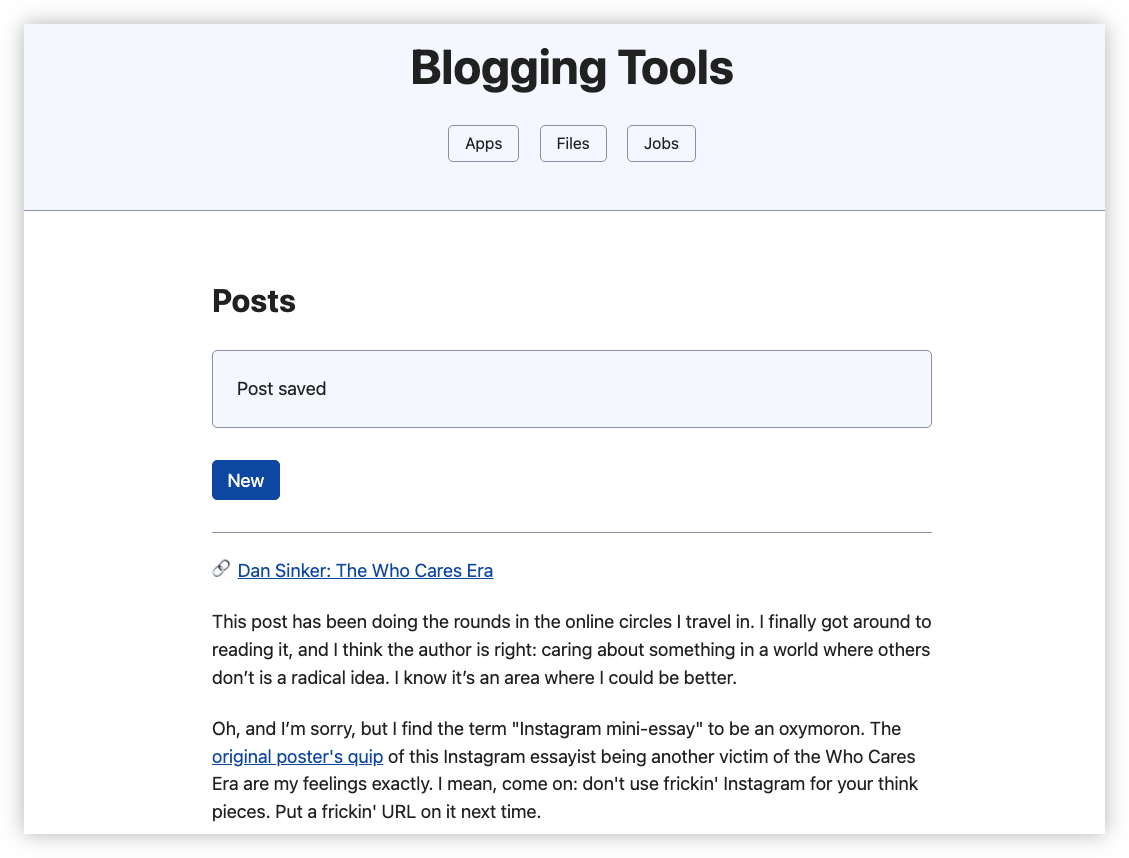
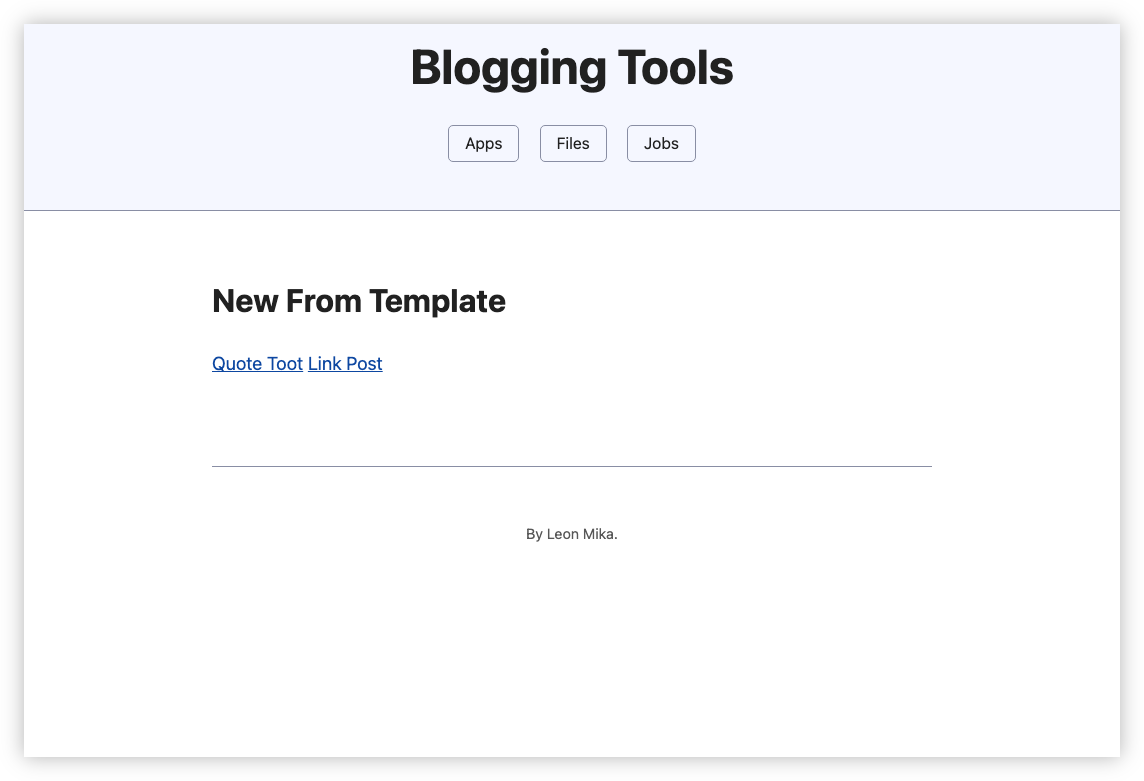
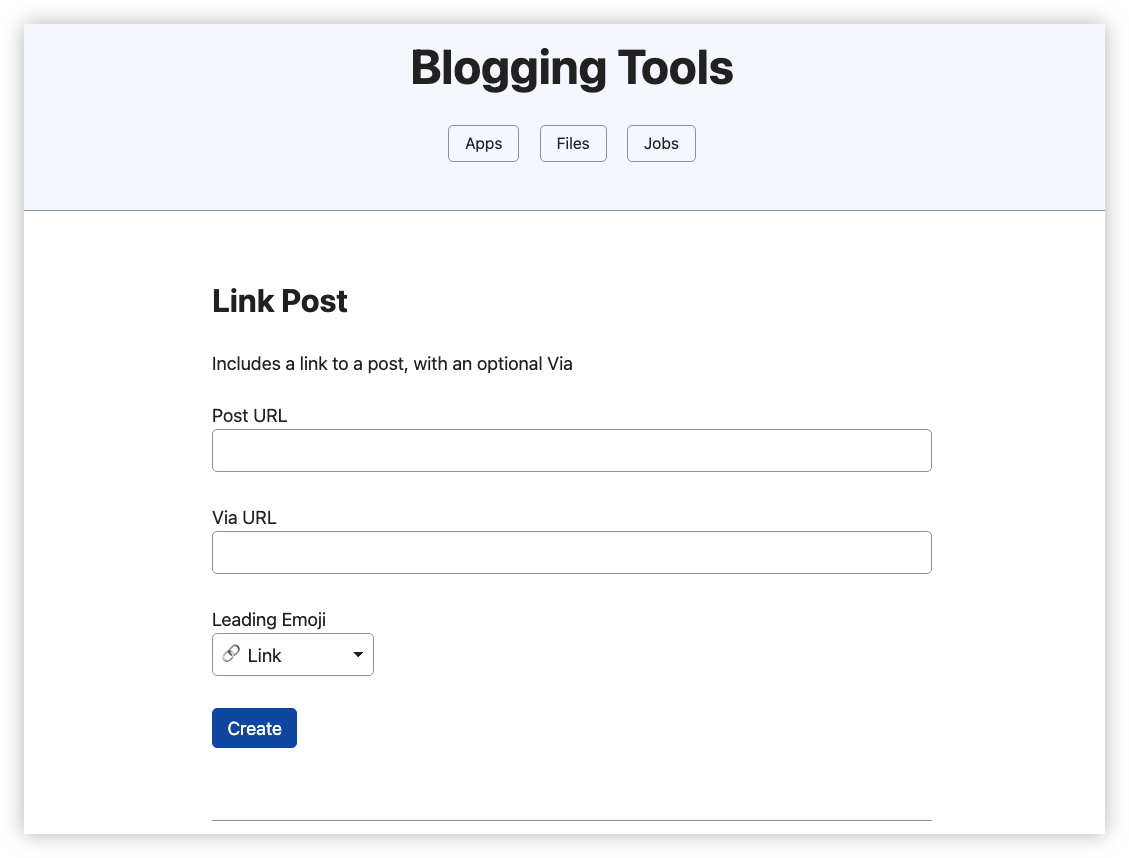
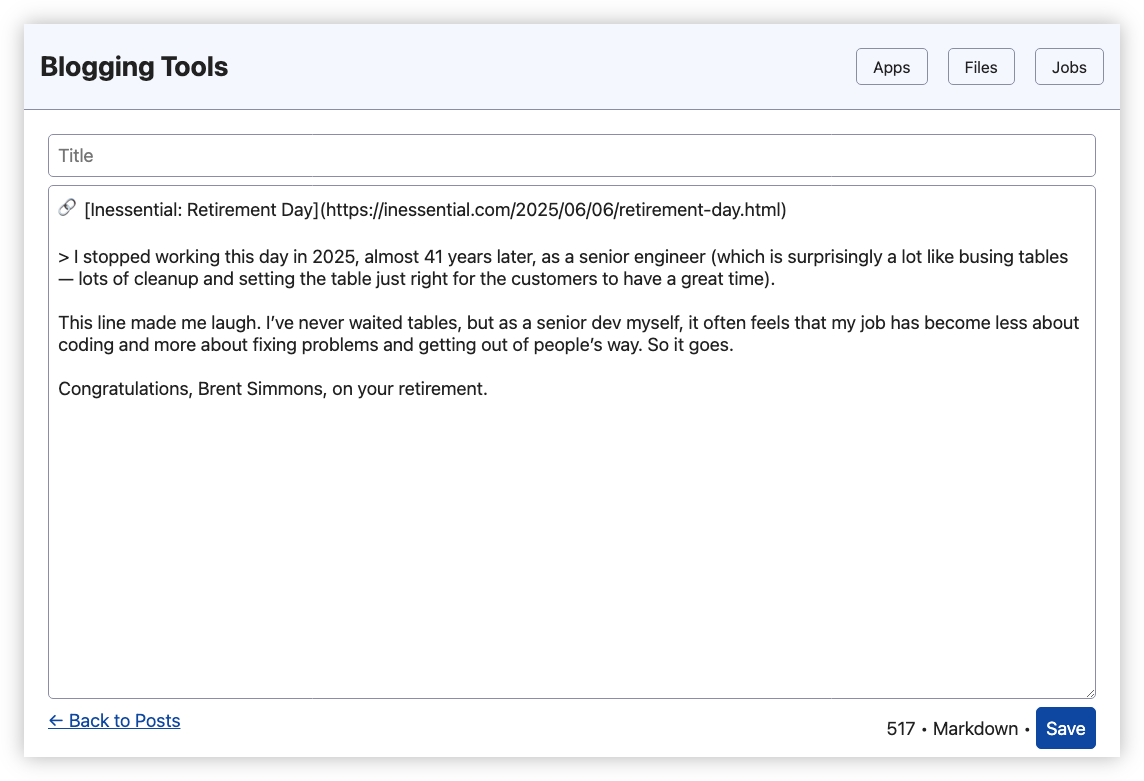
This can’t really be described as CMS. It’s more of a place to create posts from a template which can then be published via a Micropub endpoint. But it does the job I need, which is creating link posts with the links pre-filled.
-
Or not. I mean, I’m not expecting you to notice. You’ve got lives of your own, after all. ↩︎
🔗 Dan Sinker: The Who Cares Era
This post has been doing the rounds in the online circles I travel in. I finally got around to reading it, and I think the author is right: caring about something in a world where others don’t is a radical idea. I know it’s an area where I could be better.
Oh, and I’m sorry, but I find the term “Instagram mini-essay” to be an oxymoron. The original poster’s quip of this Instagram essayist being another victim of the Who Cares Era are my feelings exactly. I mean, come on: don’t use frickin’ Instagram for your think pieces. Put a frickin’ URL on it next time.
Day 9: wood
A photo of my grandfather’s old joinery. #mbjune

Day 8: travel
I suppose I should start thinking about filling this up. #mbjune

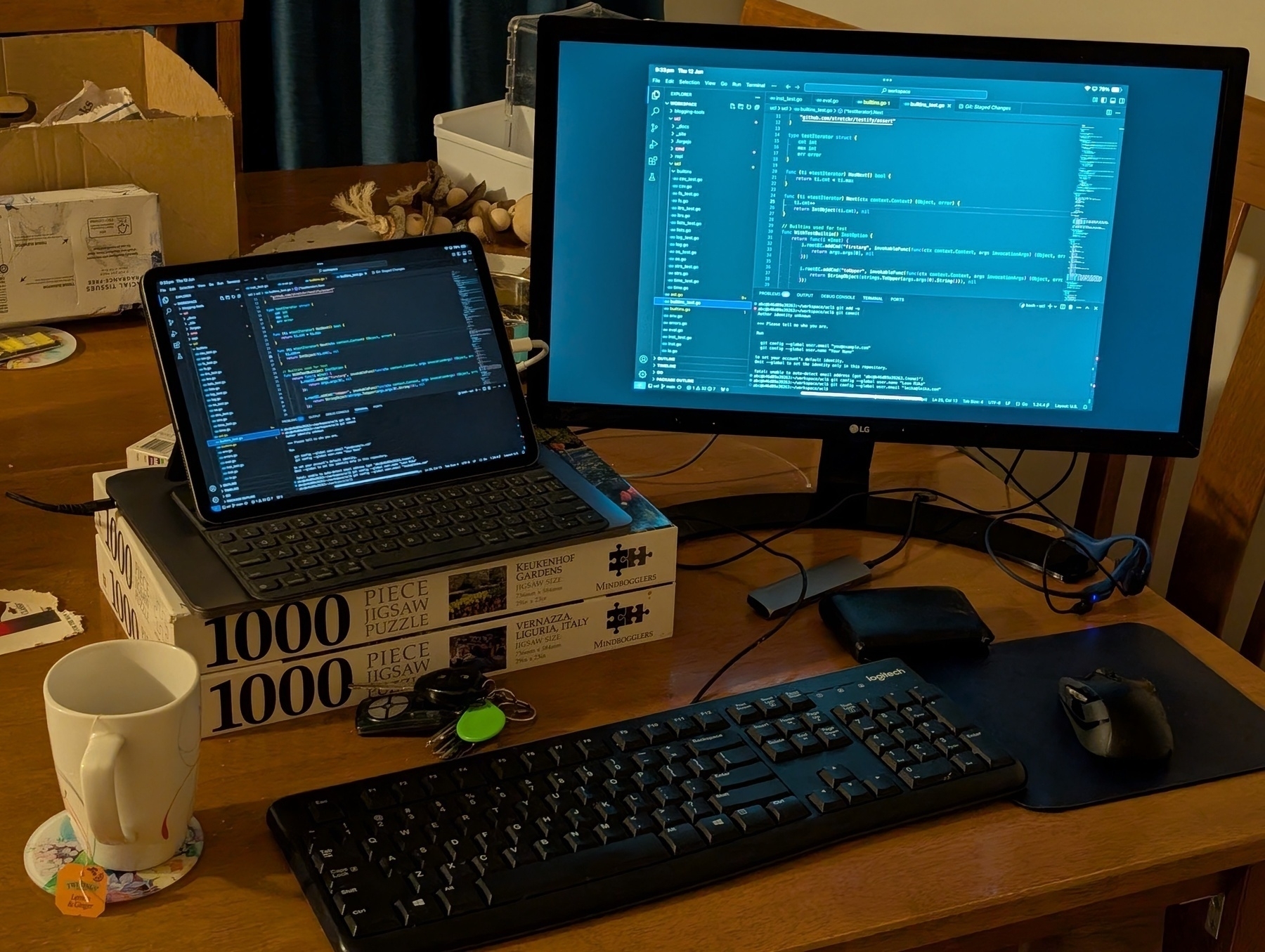
Will be away from home for a while so got a VS Code server ready so I can still work on projects. Setting it up in Coolify was so easy, yet I’ll need to fix the issue of the proxy server adding /proxy/port-no in front of all my handlers. Got some Java servet vibes from this.
TIL that the metaphor for nervous anticipation is not to be “on tender hooks.” It’s to be “on tenterhooks,” a type of hook used in a frame called a “tenter” used to hold material.