
-
Will be away from home for a while so got a VS Code server ready so I can still work on projects. Setting it up in Coolify was so easy, yet I’ll need to fix the issue of the proxy server adding
/proxy/port-noin front of all my handlers. Got some Java servet vibes from this. -
TIL that the metaphor for nervous anticipation is not to be “on tender hooks.” It’s to be “on tenterhooks,” a type of hook used in a frame called a “tenter” used to hold material.
-
Just setup a cron for performing a repo backup on my Mac Mini server. And I swear to God: if MacOS prevents this backup from running because of some damn permission check, I’m going to be effin’ furious.
-
Chalk me up as one of those people that wished they could use Markdown everywhere. I use it for notes, for messaging, writing here, etc. I occasionally dabble with WYSIWYG editors but I always turn back to Markdown. Love it.
videos -
Day 7: switch
Has anyone had any success knowing what each hotel switch does without having to try each one of them first? #mbjune

-
I stopped working this day in 2025, almost 41 years later, as a senior engineer (which is surprisingly a lot like busing tables — lots of cleanup and setting the table just right for the customers to have a great time).
This line made me laugh. I’ve never waited tables, but as a senior dev myself, it often feels that my job has become less about coding and more about fixing problems and getting out of people’s way. So it goes.
Congratulations, Brent Simmons, on your retirement.
links -
🔗 Jim Nielsen: Notes from Andreas Fredriksson’s “Context is Everything”
What really resonates in his step-by-step process is how, as problems present themselves, you see how much easier it is to deal with performance issues for stuff you wrote vs. stuff others wrote. Not only that, but you can debug way faster!
The understanding that comes from the code you wrote yourself is grossly underrated in my opinion. Choosing to use a library for something is not free. There’s an exchange involved: speed now for understanding later.
links -
🔗 Flamed Fury: Monthly Recap: May 2025
I found the bookmarks from this monthly recap to be really interesting.
links -
Everyone wants to move fast. Yet everyone wants to change their minds all the time. Yet everyone wants things to be robust and secure. Argh! Speed, quality, flexibility. Pick two. If you ask for three, you’ll get zero.
-
Day 6: contrast
Moonlight coming through my bedroom window. This one’s had the Onxy filter applied as the original was quite noisy. #mbjune

-
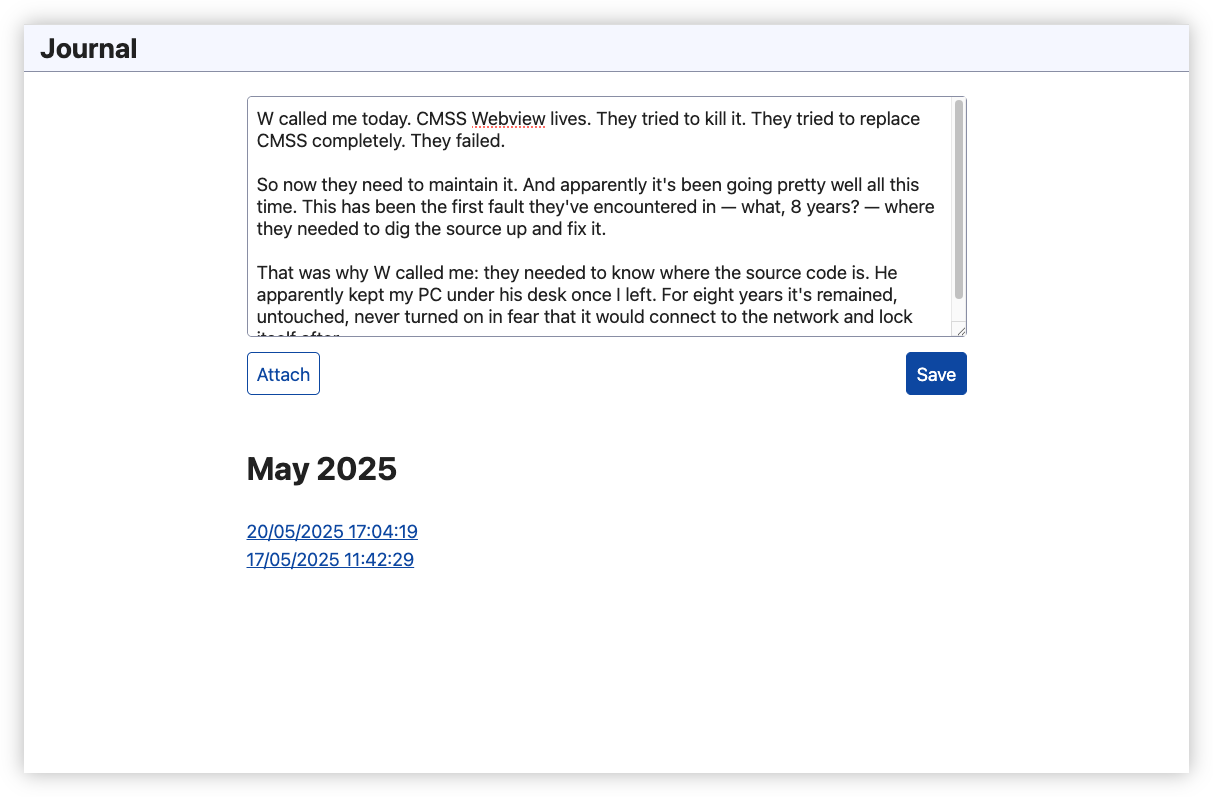
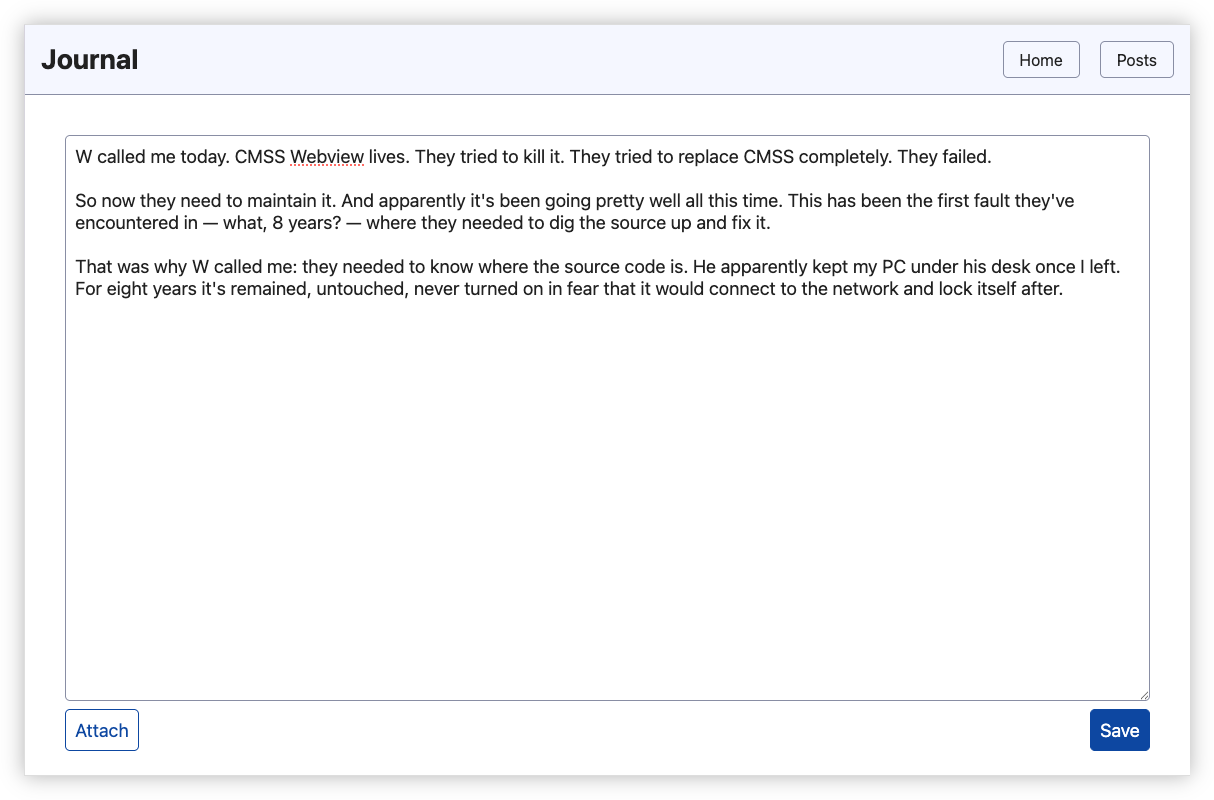
Had a reason to write a journal entry today, which meant I had a reason to work on the journaling app. Biggest change was moving the entry list to a separate page and supersizing the text-area to allow for larger entries. Good thing too: today’s was going to need all the space it could get.
 devlog
devlog -
If only joining new Discord servers is enough to satisfy the “get out more” goal I set for myself. It induces the same feelings I get when I walk into a room of people I don’t know all getting along. 😬
-
Day 5: reflection
#mbjune

-
Working on that Godot game again, mainly coming up with mechanics for a new level 2. This is what I’ve got so far: a mine tethered to a balloon. Their idle state is just bobbing up and down, but I am planning a variant which will drop their payload and fly away when the player is nearby.
 devlog
devlog -
I’m gonna miss these malfunctioning 1st gen Myki readers when they eventually get replaced.

-
Encapsulation In Software Development Is Underrated
Encapsulation is something object-oriented programming got right. Continue reading →
-
Day 4: nostalgia
A bit of a personal one today: the back room of my Nonna’s house, taken 11 years ago while she was in the process of moving out. Many things in this photo that are nostalgic in their own right. The house has been demolished and Nonna has past on, so I’m glad I have this. #mbjune

-
Me, exactly a month ago, about how I didn’t care for page transitions:
Anyway, that’s the feeling at the moment. Maybe I’ll come around.
I think I’m coming around.
-
Spent most of the day hitting my head against the wall trying to get this damn service to work. I came up with a version which I thought would work, to a degree. But then I handed it to the testers: fail, fail, fail, fail, fail. Argh! I guess it’s back to the wall tomorrow. 😫
-
Day 3: shadow
#mbjune

-
I wonder if stations can benefit from installing high tables. Seating is useful, but it’d also be useful if I had access to a surface to temporarily place a coffee or wet umbrella when I get something from my bag.
-
I found Jason’s position about Apple adding gambling odds to their sports app a little odd (no pun intended). Not to say that he endorses it — he definitely does not — but I would’ve thought he’d recognise that people buying Apples products expect a premium experience. And that adding such, one might say, “vulgar” features to their app, degrades that experience.
Or at least this probably how I’d feel about it. I don’t watch sports, so this has little impact on my experience. But if I did, I’d probably find the whole thing rather dirty. I can’t stand all these awful sports betting apps.
podcast-clips -
If I had a dollar for every time I mix up
brew updateandbrew upgrade, I’d probably be able to quit my job.

