-
So, walking from the station to the only cafe that’s open to pick up a coffee before my train arrives is about a 5 minute round trip. This assumes the barista is ready and there are no customers in front. So, let’s say it’s safe to go when the earlier train has just left the station.
-
It’s such a romantic idea to think that they’ll always be a customer or product manager available to me to answer all my business rules questions. Would love that to actually be the case. 😕⁉️
-
I’ll never understand Go developers who insist on using pointers to represent a lack of something, where a zero value would work just as well. Better even, as you wouldn’t need to dereference things or worry about nil-pointer panics. Remember, don’t fear the zero value.
-
It only just occurred to me that I can turn off “Use ⌘+Scroll to Zoom Page” in Vivaldi to compensate for the Magic Mouse’s incessant need to scroll while I’m trying to Cmd+Click a link.
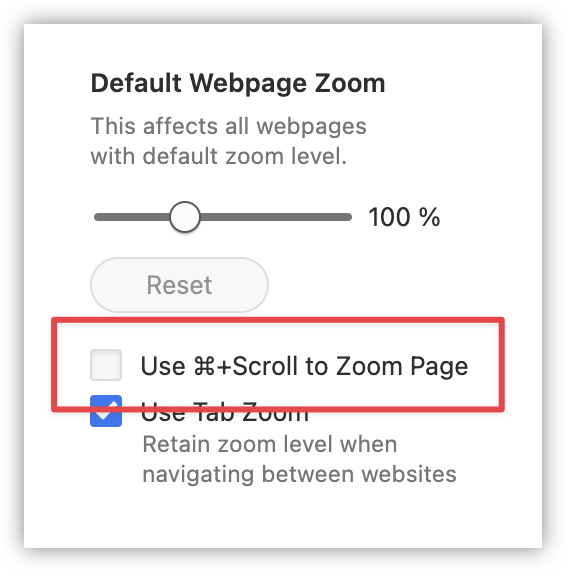
I still dislike the mouse, but hopefully with this off, the urge to throw it out the window will be diminished.
-
Cropping A "Horizontal" PocketCast Clip To An Actual Horizontal Video
Finally fixed the issue I was having with my ffmpeg incantation to crop a PocketCast clip. When I was uploading the clip to Micro.blog, the video wasn’t showing up. The audio was fine, but all I got for the visuals was a blank void1.
For those that are unaware, clips from PocketCast are always generated as vertical videos. You can change how the artwork is presented between vertical, horizontal, or square; but that doesn’t change the dimensions of the video itself. It just centers it in a vertical video geared towards TikTok, or whatever the equivalent clones are.
Continue reading → -
Also, hat tip to the “postrolls” which led me to the previously linked item. I’ve been enjoying these two over the last few days:
I’ll post any more that I find. 🔗
links -
Love this post by Mike Grindle, especially this line:
To me, it shows what happens when you regularly write, publish, share and hyperlink into the void that is the web: the void speaks back.
Similar things happen to me from time to time, and when I find it, it’s always a bit of a thrill. I don’t expect the ripples that are the posts on this site to reflect back, but it’s wonderful when they do.
-
Removing personal identifying information from logs is a laudable goal, but it does make troubleshooting issues in prod rather difficult.

Source of meme image other-artefacts memes -
A recurring element of my dreams is an unmaintained railway line. The infrastructure is falling apart, yet it’s still an important connection and trains occasionally do use it. I usually approach it at level crossings and in past dreams I’ve not once saw a train. Last night, I almost got hit by one.
-
If anyone’s interested in the history of Melbourne transport, I can recommend this YouTube channel. He has a few videos on the “forgotten freeways” — freeways planned in the 1960’s that never got built — that I found quite interesting. 📺
media -
Every single dog I’ve met is an optimist. Not once have I seen a dog around someone with food, and that dog be like, “no point begging for that. That food ain’t coming my way.”
-
I also decided to put the documentation “on-board”, as opposed to putting it on the web. Yes, it breaks from what was typical during the 8-bit gaming period, but I’ve got the space, and it makes adding illustrations easier.
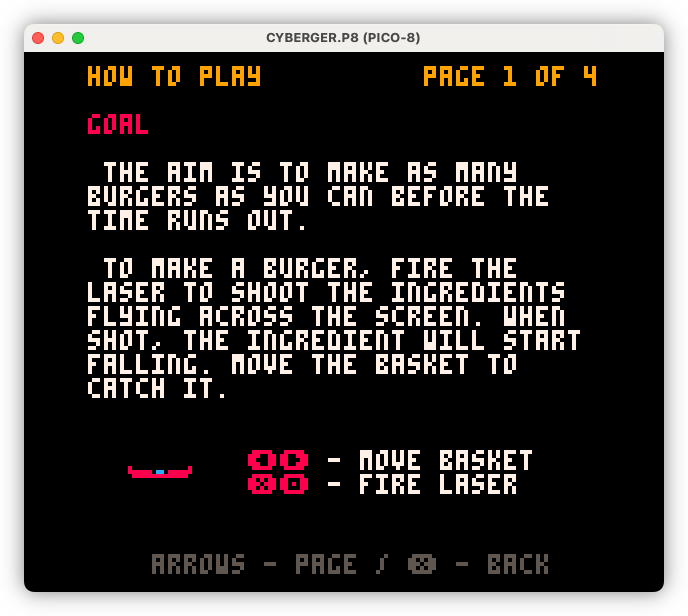
Also forces me to keep it brief, which is no bad thing.
devlog -
Building out the meta elements of Cyber Burger, including the “menu du jour” a.k.a. the main menu. I’ve used food-service terms for the menu items to maintain the theme, but there is a button to switch them over to more conventional names should it be too unclear.
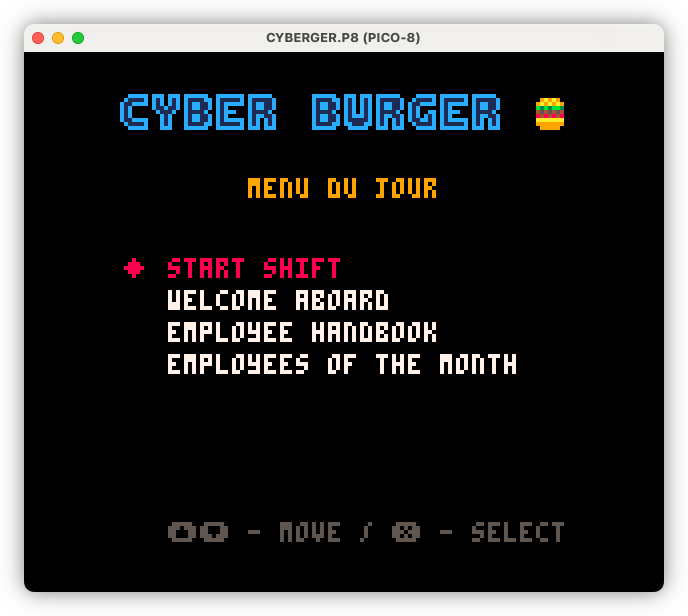 devlog screenshots
devlog screenshots -
As bad as being swooped can get for humans in the Spring, dogs get it so much worse. So it’s good seeing a kelpie running around the park, being swooped by three noisy miners, and not bat an eyelid over it.
-
Interesting to thing that the most useful software tools I use for work are the same ones that, should I make a mistake, can blow my foot off. It struck me that I don’t think it’s possible to have such powerful tools that can be completely safe. You can add guards to stop you from doing silly things — think dry-run switches and confirmation popups — but there needs to be a way to disengage that safety in order to use the full power of the tool. Otherwise, why have the tool at all?
-
Needed to get some hot water to quickly wash something this morning. Turned the kettle on, only to shut it off a few seconds later as I thought the coffee machine would be quicker. So I turned the coffee machine on, only to turn that off a few seconds later as I thought it would’ve just be quicker to get use hot water from the tap. I eventually used the tap, but the total time it took me to wash this thing was longer than it would’ve been if I just chosen one method and stuck with it.
-
Generally, it’s good to know that you’re needed at work. But sometimes, it’s just as good to know that you won’t be needed at work (at least for a time).
-
Table
sub_mappinghas more than one primary key, you say? Ok, you might be on to something.CREATE TABLE sub_mapping ( subscription_id TEXT PRIMARY KEY, customer_id TEXT PRIMARY KEY, local_subscription_id TEXT PRIMARY KEY, user_id TEXT PRIMARY KEY ); -
So apparently I can add a wifi network to MacOS whenever one is advertised but I can’t remove it unless I enter the admin password. That’s a strange security model.
-
Just to add one point of anecdata to Ben’s experience: I’ve never been happy with the performance of the mobile radio of Pixel phones. You can be in the middle of the CBD and still experience weird dropouts while using mobile data. It’s quite frustrating.
videos -
“Geographically-determined relevance deprivation syndrome” is going to be the noun-phrase of the day. 🙌
For no other reason that it’s a great phrase, and also that it’s real.
Via ABC News (CW: US politics)
-
The next train announcements at suburban stations were always made a couple of minutes before the train arrived. They’ve started making them every 10 minutes before departure time too. I’m sure there’s a good reason for this but it’ll take some time for that tinge of urgency to wear off.
-
As an aside: is it possible for me to have any new experience without being nervous? I once lost points at a scale playing competition because I said I was nervous. It offended me so much that I never participated again.