
Workpad
-
Yes, this is probably just a rationalisation for trying to minimise sunk-costs, but I’ve got nothing else to work on, so why not this? ↩︎
-
This is still true to this day. ↩︎
- I spent some time last weekend playing with Htmgo by making a simple world clock that would update every second. I ended up remaking this as a static web page backed by some WASM code. Knowing the time in UTC and some American cities could come in handy for my job. At least, that’s the theory: I haven’t had a need for it yet.
- I also made some changes to Nano Journal to add support for uploading multiple attachments at once.
I’ve been using UCL a lot recently, which is driving additional development on it. Spent a fair bit of time this evening fixing bugs and adding small features like string interpolation. Fix a number of grammar bugs too, that only popped up when I started writing multi-line scripts with it.
Project Update: DSL Formats For Interactive Fiction
Still bouncing around things to work on at the moment. Most of the little features have been addressed, and I have little need to add anything pressing for the things I’ve been working on recently. As for the large features, well apathy’s taking care of those. But there is one project that is tugging at my attention. And it’s a bit of a strange one, as part of me just wants to kill it. Yet it seems to be resisting.
About 6 months ago, I started working on some interactive fiction using Evergreen. I got most of the story elements squared away but much of the interactive elements were still left to be done. And as good as Evergreen is for crafting the story, I found it a little difficult tracking down all the scripts I needed to write, debug and test.
So in early November, I had a look at porting this story over to a tool of my own, called Pine Needle (yes, the name is a bit of a rip-off). Much like Evergreen, the artefact of this is a choose-your-own-adventure story implemented as a static webpage. Yet the means of building the story couldn’t be more different. Seeing that I’m more comfortable working with code and text files, I eschewed building any UI in favour of a tool that simply ran from the command line.
But this meant that I needed someway to represent the story in text. Early versions simply had the story hard coded in Go, but it wasn’t long before I started looking a using a DSL. My first attempt was a hand-built one based on Markdown with some additional meta-elements. The goal was to keep boilerplate to a minimum, with the meta-elements getting out of the way of the prose. Here’s a sample of what I had working so far:
// Three dashes separate pages, with the page ID following on.
// Also these are comments, as the hash is reserved for titles.
--- tulips-laundry-cupboard
You open the cupboard door and look at the shelf
above the brooms. There are a couple of aerosol cans up there,
including a red one that says "Begone Insecticide".
You bring it out and scan the active ingredients. There are a
bunch of letters and numbers back there, and none of them have
the word "organic."
\choice 'Take Insecticide' to=tulips-take-insecticide
\choice 'Leave Insecticide' to=tulips-leave-insecticide
--- tulips-take-insecticide
You return to the tulips with the insecticide, and start
spraying them. The pungent odour of the spray fills the air,
but you get the sense that it's helping a little.
\choice 'Continue' to=tulips-end
--- tulips-leave-insecticide
You decide against using the can of insecticide. You put the
can back on the shelf and close the cupboard door.
\choice 'Look Under The Trough' to=tulips-laundry-trough
\choice 'Exit Laundry' to=tulips-exit-laundry
The goal was to have the meta-elements look like LaTeX macros — for example, \option{Label}{target-screen} — but I didn’t get far in finishing the parser for this. And I wasn’t convinced it had the flexibility I wanted. LaTeX macros relies pretty much on positional arguments, but I knew I wanted key-value pairs to make it easier to rely on defaults, plus easier to extend later.
I did imagine a fully LaTeX inspired DSL for this, but I quickly dismissed it for how “macro-heavy” it would be. For reference, here’s how I imagined it:
\screen{tulips-laundry-cupboard}{
You open the cupboard door and lo ok at the shelf
above the brooms. There are a couple of aerosol cans up there,
including a red one that says "Begone Insecticide".
You bring it out and scan the active ingredients. There are a
bunch of letters and numbers back there, and none of them have
the word "organic."
\choice{Take Insecticide}{to=tulips-take-insecticide}
\choice{Leave Insecticide}{to=tulips-leave-insecticide}
}
\screen{tulips-take-insecticide}{
You return to the tulips with the insecticide, and start
spraying them. The pungent odour of the spray fills the air,
but you get the sense that it's helping a little.
\choice{Continue}{to=tulips-end}
}
\screen{tulips-leave-insecticide}{
You decide against using the can of insecticide. You put the
can back on the shelf and close the cupboard door.
\choice{Look Under The Trough}{to=tulips-laundry-trough}
\choice{Exit Laundry}{to=tulips-exit-laundry}
}
I wasn’t happy with the direction of the DSL, so I looked for something else. I briefly had a thought about using JSON. I didn’t go so far as to try it, but the way this could work is something like this:
{"screens": {
"id": "tulips-laundry-cupboard",
"body": "
You open the cupboard door and look at the shelf
above the brooms. There are a couple of aerosol cans up
there, including a red one that says \"Begone Insecticide\".
You bring it out and scan the active ingredients. There
are a bunch of letters and numbers back there, and none of
them have the word \"organic.\"
",
"options": [
{
"screen":"tulips-take-insecticide",
"label":"Take Insecticide",
},
{
"screen":"tulips-leave-insecticide",
"label":"Leave Insecticide",
}
]
}, {
"id":"tulips-take-insecticide",
"body":"
You return to the tulips with the insecticide, and start
spraying them. The pungent odour of the spray fills the air,
but you get the sense that it's helping a little.
",
"options": [
{
"screen":"tulips-end",
"label":"Continue"
}
]
}}
I generally like JSON as a transport format, but it didn’t strike me as a format that suited the type of data I wanted to encode. Most of what this format would contain would be prose, which I’d prefer to keep as Markdown. But this would clash with JSON’s need for explicit structure. Setting aside the additional boilerplate this structure would require, all the prose would have to be encoded as one big string, which didn’t appeal to me. Also no comments, especially within string literals, which is a major deal breaker.
So, the current idea is to use something based on XML. This has some pretty significant benefits: editors have good support for XML, and Go has an unmarshaller which can read an XML directly into Go structures. JSON has this too, but I think it’s also a pretty decent format for at editing documents by hand, so long as you keep your XML elements to a minimum.
I think one aspect that turned people off XML back in the day was format designer’s embrace of XML’s ability to represent hierarchical data without leaning into it’s use as a language for documents. The clunky XML documents I had to deal with were purely used to encode structure, usually in a way that mapped directly to an domain’s class model. You had formats where you need 10 nested elements to encode a single bit of information that were a pain to read or edit by hand. These were usually dismissed by the designers with promises like, “Oh, you won’t be editing this by hand most of the time. You’ll have GUI design tools to help you.” But these were awful to use too, and that’s if they were available, which they usually were not (did you know building GUIs are hard?)
If you have an XML format that skews closer to HTML rather than something that’s representable in JSON, I think it could be made to work. So yesterday I had a go at seeing whether it this could work for Pine Needle. Here’s what I’ve got so far:
<?xml version="1.0">
<story>
<screen id="tulips-laundry-cupboard">
You open the cupboard door and look at the shelf
above the brooms. There are a couple of aerosol cans up
there, including a red one that says "Begone Insecticide".
You bring it out and scan the active ingredients. There
are a bunch of letters and numbers back there, and none of
them have the word "organic."
<option screen="tulips-take-insecticide">Take Insecticide</option>
<option screen="tulips-leave-insecticide">Leave Insecticide</option>
</screen>
<screen id="tulips-take-insecticide">
You return to the tulips with the insecticide, and start
spraying them. The pungent odour of the spray fills the air,
but you get the sense that it's helping a little.
<option screen="tulips-end">Continue</option>
</screen>
<screen id="tulips-leave-insecticide">
You decide against using the can of insecticide. You put the
can back on the shelf and close the cupboard door.
<option screen="tulips-laundry-trough">Look Under The Trough</option>
<option screen="tulips-exit-laundry">Exit Laundry</option>
</screen>
</story>
The idea is that the prose will still be Markdown, so things like blank lines will still be respected (the parser strips all the leading whitespace, allowing one to easily indent the prose). Attributes satisfy the key/value requirement for the elements, and I get the features that make this easy to modify by hand, such as comments and good editor support.
I think it’s going to work. It would require some custom code, as Go’s unmarshaller doesn’t quite like the mix of prose and declared <option> elements, but I think it’s got the bones of a decent format for this interactive fiction. Already I’m coming up with ideas of how to add script elements and decompose fragments into sub-files to make it easier to test.
I’ll talk more about this project in the future if I’m still working on it. I don’t know if the story that started all this will see the light of day. I’ve gone through it a few times, and it’s not great. But shipping stuff you’re proud of comes from shipping stuff you’re not proud of, and given how far along it is, it probably deserved to be release in one form or another. That’s probably why it’s been saved from the chopping block so far1.
I recently got a new phone, a Pixel 9 Pro, which meant I needed to bring Alto Player up to date. I probably could’ve gotten away using the version I was using on my Pixel 6. But I didn’t have a binary build, and I needed to upgrade Gradle anyway, so I decided to spend a bit of time bringing it up to date to API version 35, the version used in Android 15.0. Fortunately it was only a few hours in total, and once I got it running in the simulator, I side-loaded it onto my phone and started using it.
It worked, but there were some significant UI issues. The title-bar bled into the status bar, the album image in the Now Playing widget was cropped by the curved corners of the phone, and the media notification didn’t display playback controls.
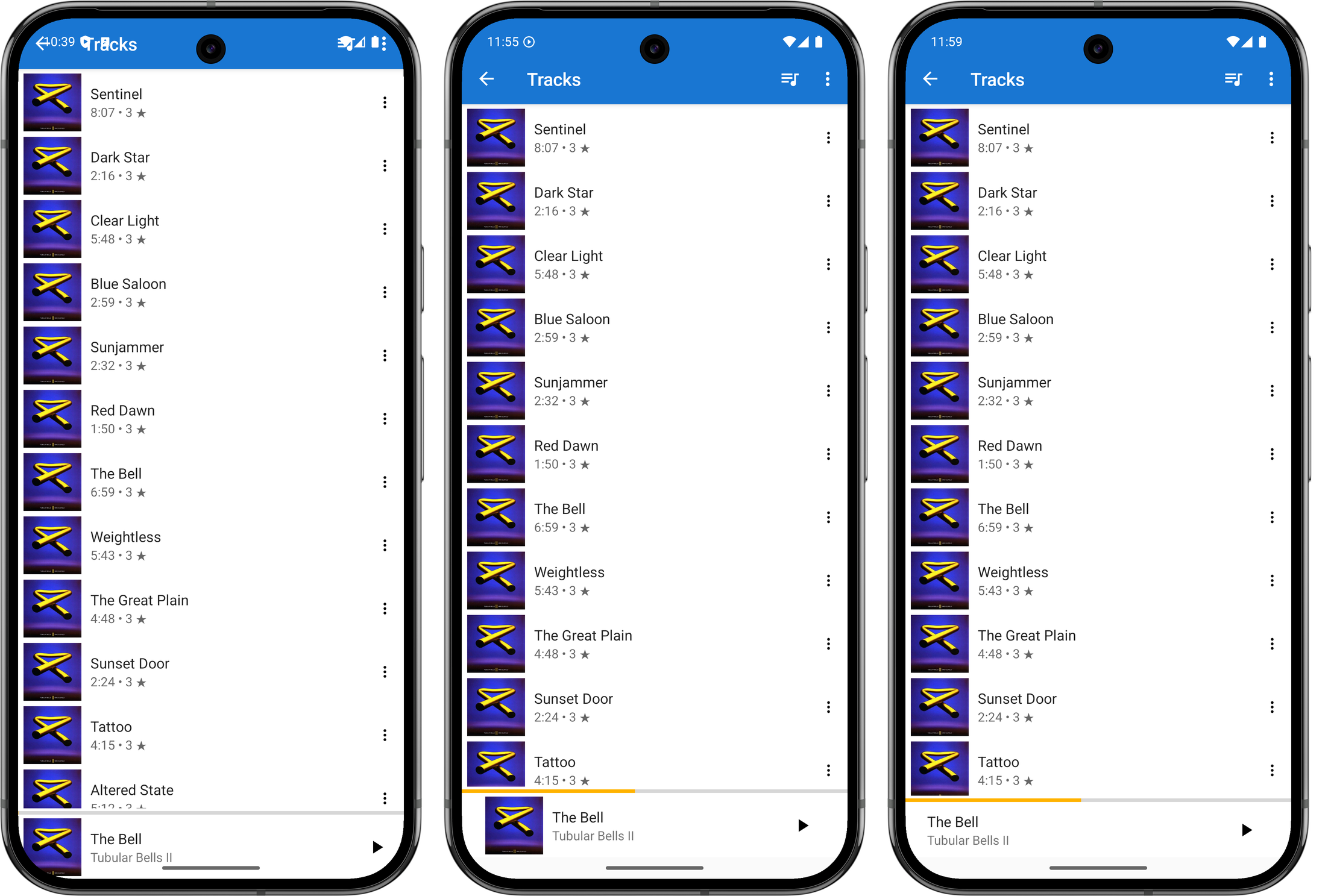
I set about fixing these issues today, starting with the title-bar and Now Playing widget. These was an issue with the views not respecting the window insets, and after a quick Google search, I found this article showing how one could resolve this by adding a ViewCompat.setOnApplyWindowInsetsListener and reacting to it by adjusting the margins of the view.
val topLevelLayout = findViewById(R.id.top_level_layout) as CoordinatorLayout
ViewCompat.setOnApplyWindowInsetsListener(topLevelLayout) { v, windowInsets ->
val insets = windowInsets.getInsets(WindowInsetsCompat.Type.systemBars())
v.updateLayoutParams<ViewGroup.MarginLayoutParams> {
leftMargin = insets.left
bottomMargin = insets.bottom
rightMargin = insets.right
// applying a top margin here would work, but will not have the toolbar
// background colour "bleed" into the status bar, which is what I want.
}
val t = v.findViewById<Toolbar>(R.id.toolbar)
t.updateLayoutParams<ViewGroup.MarginLayoutParams> {
// make the toolbar a little "narrower" than full height
topMargin = insets.top * 3 / 4
}
WindowInsetsCompat.CONSUMED
}
It took a few attempts, but I managed to get this working. Just using the top inset for the toolbar margin made it a little larger than I liked, so I adjusted the height to be 75% of the inset. This means the toolbar will actually encroach into the area reserved for cut-outs like the front-facing camera. This is arguably not something a “real” Android apps should do, but this is just for me and my phone so it’s fine.
I went through a few iterations of the album artwork cutoff on the bottom right corner trying to find something I liked. I tried bringing in the horizontal margins a little, but I didn’t like the alignment of the album art in the player, particularly compared to the covers that appear in the track list screen. One thing I didn’t try was raising the bottom margin so that it would fit “above” the curve. But those corners curve in quite a bit, and doing this would sacrifice a lot of vertical space. So I settled on hiding the album art altogether. It’s a bit of a shame to loose it, but at least it looks neater now.
The next thing I looked at was fixing the playback controls in the media notification. After some investigating, I found that this was because I was not setting the available actions in the PlaybackStateCompat builder. This, if I understand correctly, is used to communicate to various systems the current state of the playing media: what the track name is, whether it’s playing, whether one can skip forward or back. I have my own types for tracking this information — which is probably not correct but I wasn’t completely sure as to what I was doing at the time with Android’s media stack1 — and when I needed to convert this to a type understood by the framework, I made instances of this builder without setting the available actions. Earlier versions of Android seemed not to care, and the controls always appeared on the notification. But I guess they changed that.
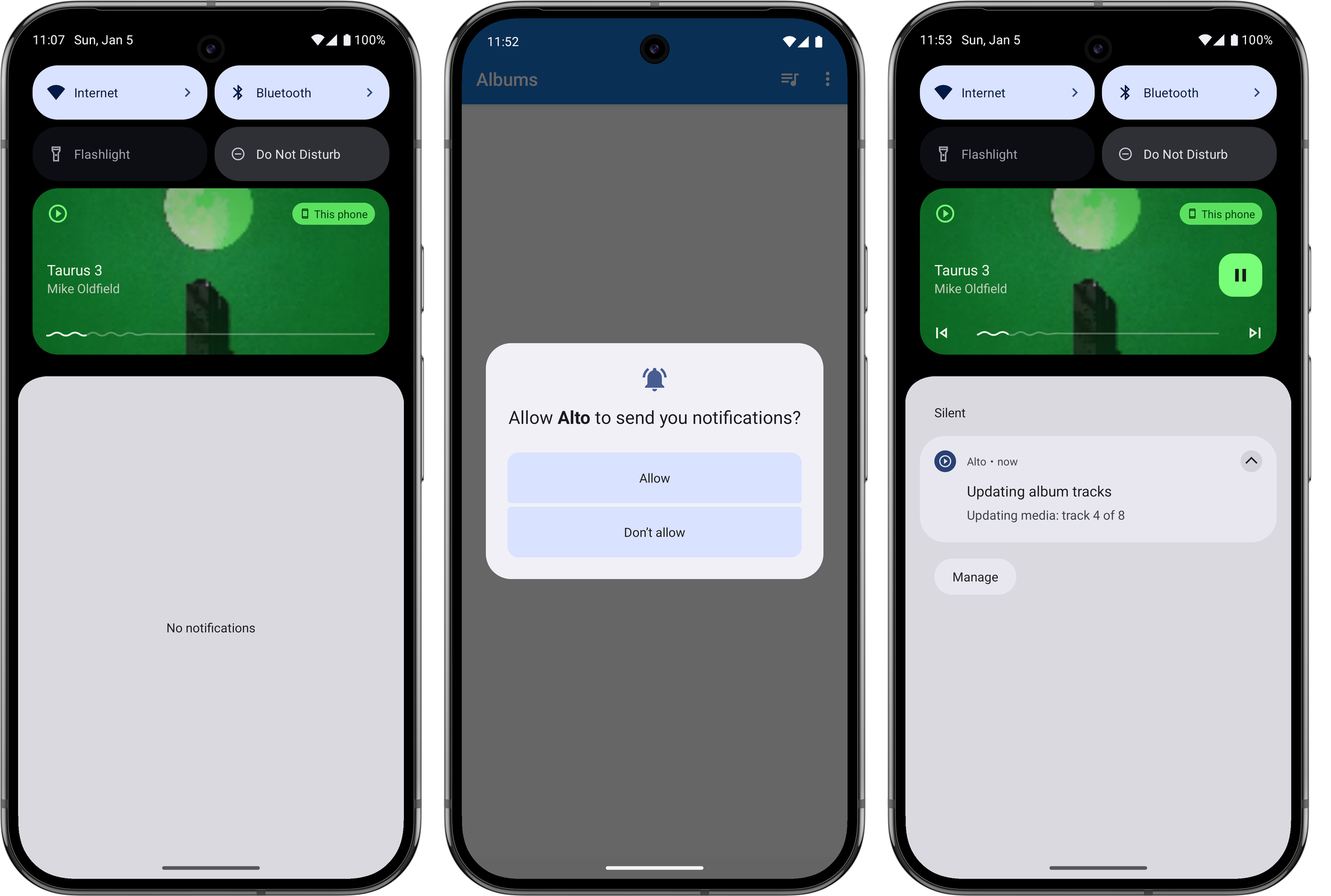
One other thing I needed to do was to explicitly ask the user permission to show a notification before I could publish one. This is also relatively new: my experience with Android goes back to the early days where these permissions were disclosed up front when the app was installed. But I can completely understand why they changed it, as it was easy to simply tap through those screens with reading them. I am wondering whether media playback notifications are in some way exempt from these permission checks, as I was actually getting one to appear before I made this changes. But I figured it was probably worth doing anyway, so I added this permission request on first launch. Arguably I should be asking for this permission when playback starts, but again, this is just for me.
One final thing I needed to address were long album titles. The text view displaying the the album title had a width that autosized to the title itself, and the start and end constraints were set such that it appears centred in the view. This worked for “normal” length titles but when the length became excessive, the text view would fill the entire width of the screen and the title will appear left justified.
The fix for this was to set the text width to be calculated by the start and end constraints (setting layout_width to 0dp), bringing in the margins a little, and making the label text centre justified. I did this already for the track title, so it was easy to do this here too. Not sure why I didn’t do it earlier, or why I haven’t done it for the artist’s name yet.
This was all rushed, and I’ll admit I wasn’t 100% sure what I was doing. I was going down the route of trial-and-error to get this working, mixed in with web searches and a trip to ChatGPT. And yeah, the methods I used won’t make this a portable Android app that would work on every phone out there. But I’m reasonably happy with how it turned out.
Thanks for my new found fondness of buying mainstream music instead of streaming it, I needed a way to get these albums into Alto Catalogue. There exists a feature for fetching and importing tracks from a Zip referenced by a URL. This works great for albums bought in Bandcamp, but less so for any tracks I may have on my local machine.
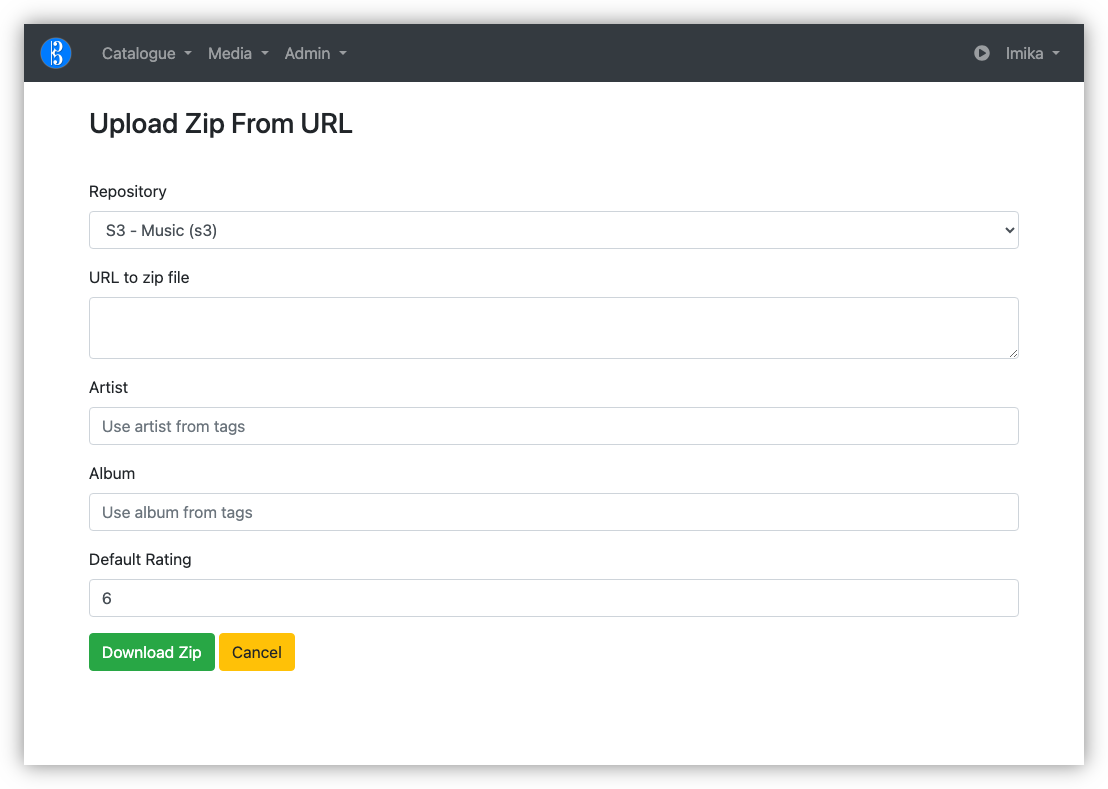
I’ve managed to get Alto Catalogue building again after updating Webpack and a few NPM packages, so in theory, I could add an Upload Zip file action. But there’s more to this than simply accepting and unpacking a Zip file. I have to read the metadata, maybe even preview the tracks that will be imported, just in case I’m importing something I rather not (I did see this once, where zipping a bunch of tracks in the Finder introduced duplicates). This already exists for Zip files that are downloadable online.
I had a though about what my options are, until I remembered that I had a Gokapi instance running in Pikapods. So I tried using that to temporarily host the Zip file with a publicly available URL that could be read by Alto Catalouge.
The only problem is my internet upload speed is sooooo sloooooow. The Gokapi instance is hosted in Europe, and I suspect the instance itself is a little underpowered. So uploading 100 MB Zip files would take a fair bit of time: maybe 15-30 minutes. When I tried doing this via the web frontend, the connection timed out.
Fortunately, Gokapi has an API and one of the methods allows you to upload a file in “chunks,” which Gokapi will assemble back into the original file. Even better is that this chunking can be uploaded in parallel.
So I built a CLI tool which made of this chunking API to upload the Zip files. Once the upload is complete, the tool will display the hot-link URL, which I can copy-and-paste into Alto Catalogue.
The whole process isn’t fast (again, slow upload speeds). But it works, and I can use this tool to queue a bunch of uploads and let it do its thing while I’m doing something else. I really like tools that do this, where you’re not forced to babysitting them through the process.
There are a few limitations with it. It doesn’t allow for an awful lot of customisations on the lifecycle of the uploaded file. And the tool stalled out once when my computer went to sleep, and I had to start the upload from scratch. I could probably add something to track the chunks that were successful, allowing one to continue a stalled upload. If this happens frequently, I may look more into adding this.
But even so, this could be a useful addition to my use of Gokapi for transferring temporary files. If you think this might be useful to you, you can find the tool here.
Fixed the UI of Alto Player, plus addressed some long standing issues I’ve been having.
One was displaying the album covers for playlists instead of the generic “missing album” image. It’s technically possible to set an album cover on a playlist, but I never built the UI to do this in the web-app. So the app now uses the album cover of the first track in the playlist if one isn’t specified. Another was getting automated release builds working in GitHub, as per these instructions
But the biggest improvement was finally getting around to storing the position of the album list, so that going back up the navigation stack wouldn’t reposition the list to the top. I tried this a way back, but couldn’t get it working, probably because I was testing RecyclerView.scrollToPositionWithOffset by passing last constant numbers, like 100, only to find the list not actually scrolling. It turns out that this method actually takes the index of the item to position at the top, not a pixel offsets. So the view wouldn’t scroll if you happen to have a list with less than 100 items. It only started working after I tried smaller numbers, like 5.
So all in all, a good day.
Only took two hours to uplift Alto Player from Android SDK version 30 to 35. Fought an upgrade to Gradle (because of-course), skirted around a migration from ExoPlayer to Media 3, and battled a NullPointerException due to my inability to properly my own navigation args. All in all, not bad.
More fun today working on Blogging Tools. Finished a feature for uploading larger videos to object storage so they can be added to a post using the standard video tag, as opposed to an embedded video player. If you see the screencast below, that means it’s working.
Exploring Godot to see if I could use it to make a card game. I got this far:
Yep, I’m on a roll. 😄
Might need to work through a couple Godot tutorials first, just so that I understand the basics.
I plan to integrate UCL into another tool at work, so I spent last night improving it’s use as a REPL. Added support for onboard help and setting up custom type printing, which is useful for displaying tables of data. I started working on the tool today and it’s already feeling great.
In other building-small-things-for-myself news, I spent a bit of time this morning on the image processor for Blogging Tools. The big new change was adding support for working with multiple source images, instead of just one. This made way for a new “Phone Shot” processor, which arranges multiple screenshots of phone apps in a row, while also downscaling them and proving some quick crops and distribution options.
This should reduce the vertical size of mobile app screenshots I post here, something that’s been bothering me a little.
Some more work on that feed reader app. You know how I said that I wanted to hold off looking at appearances? Well, I abandoned that approach when I installed the app on my phone and tried viewing a few articles. And oof! There’s work to be done there.
First, it’s slow. Very slow. It’s taking a good second or two to pull feeds and entries from Feedbin. I was expecting this, and I’ve got a few plans on how to speed this up. But the biggest concern is the janky list scrolling. I mean, I wasn’t expecting the buttery smoothness of iPhone list scrolling, but I expected Flutter to be better than what I was experiencing. I’m hoping that it’s just because I was running a debug build, but part of me fears that Flutter is just not optimised for smooth list scrolling, favouring ease of development and a common runtime. I rather not change frameworks now, especially after spending an evening dealing with all the build issues, but I don’t want to live with this for ever.
But speed is not the biggest issue. The biggest offender was the feed reader view. The embedded web-view was only lightly styled, and it felt like it. The margins were all off, and I didn’t like the default font or colours. It made reading the article a bad experience to a surprising degree. I’ve dealt with rushed or poorly designed UIs in the past, but I didn’t have much tolerance for this. Not sure why this is, but I suspect it’s because I’ve been using feed readers that put some effort into the design of their reader screen.
In any case, a couple of evenings ago, I decided to put some effort into the styling. I replace the body text font with Noto Sans and the fixed-font with Ubuntu Mono. I dropped the font-size a little to 1.05 em (it was previously 1.1 em, with felt a little big, and 1.0 em felt a little small). I bought the margins in a little. And I styled the block-quote, figure, and pre elements to an appearance that, despite being a little overused, felt quite modern.
The results look much better, at least to my eye (and my emulator). Here are some side-to-side comparison shots of the changes (left side is the unstyled version, while the right side has the new styling changes):
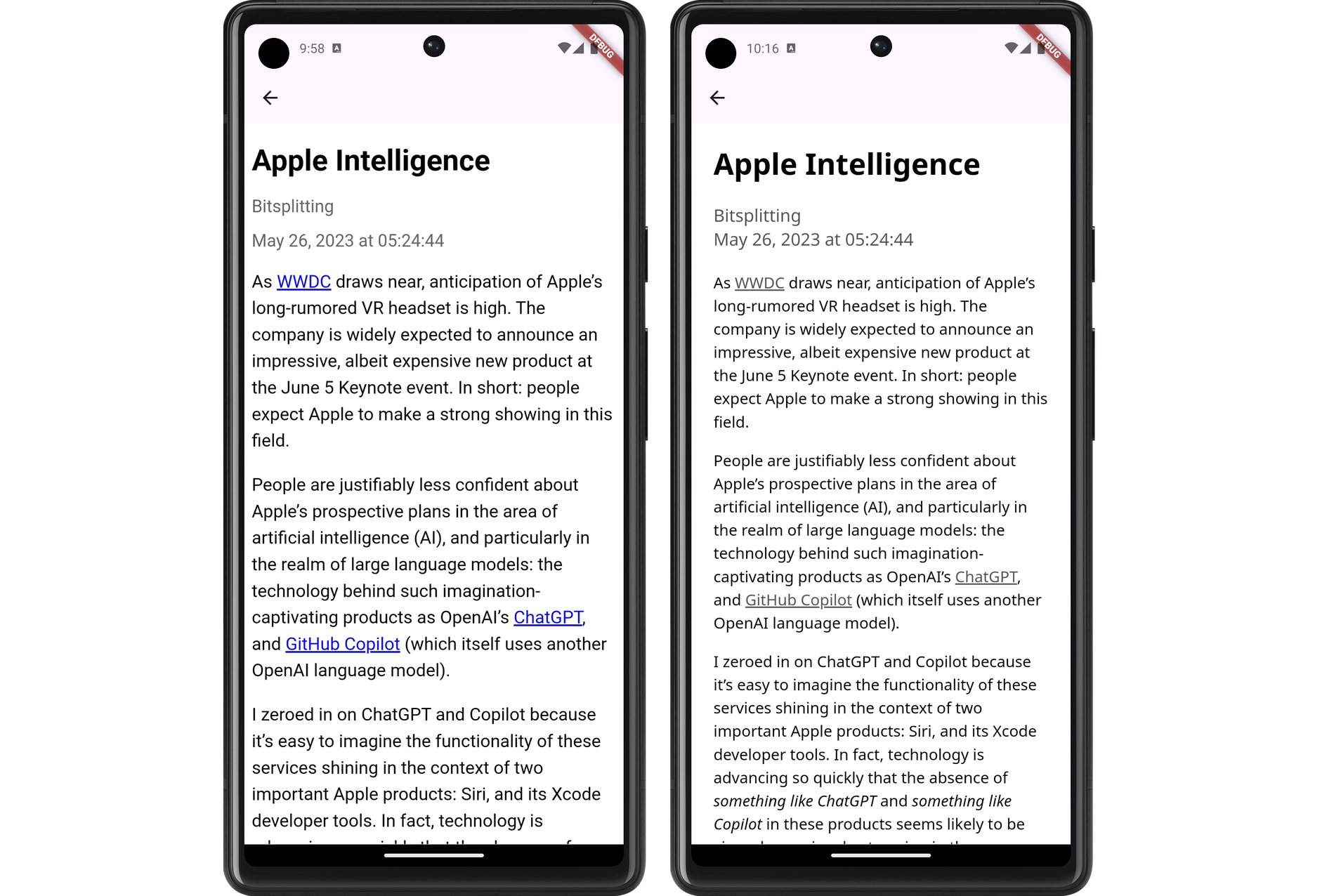
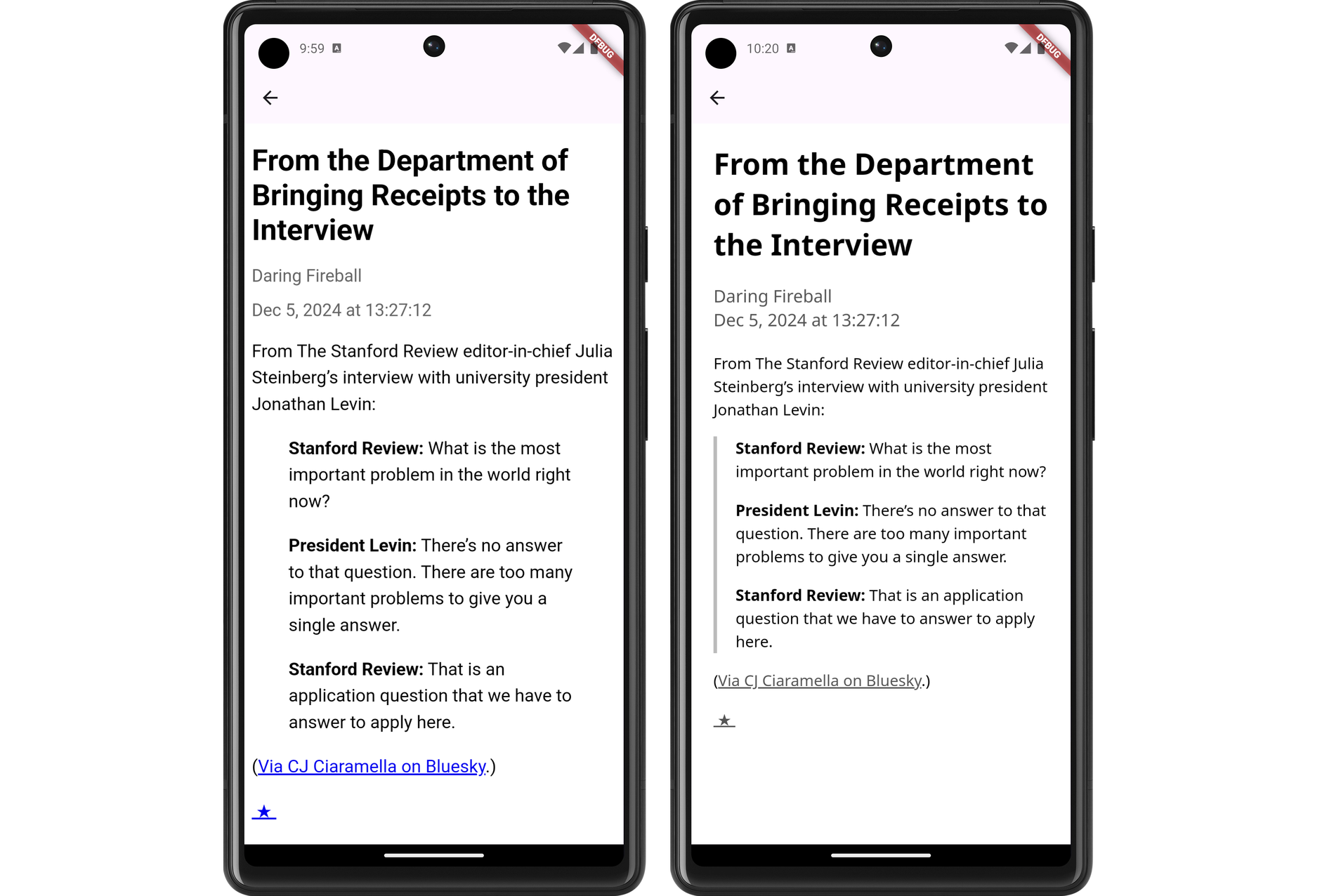
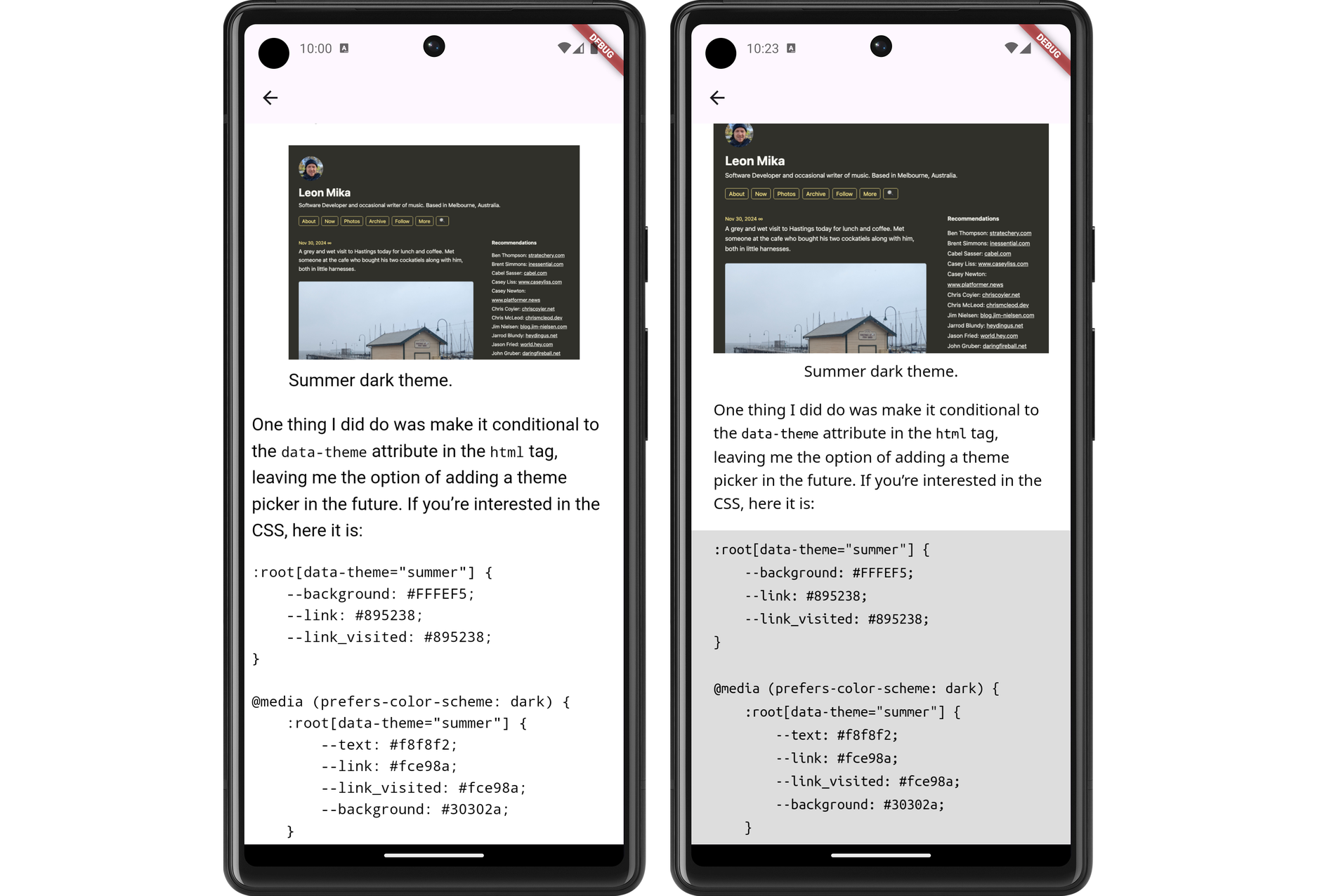
I still need to actually install this on my phone and try it out. I’m wondering whether I should do so after a bit more work syncing the read status with Feedbin. That’s a feature that’s keeping me on Feedbin’s PWA for now.
Spent the last few evenings continuing work on a Flutter-based RSS feed reader. This project is now further along then my previous attempts at doing this. I’m at the point where feeds and feeds items are being fetch from Feedbin and displayed in a list view:
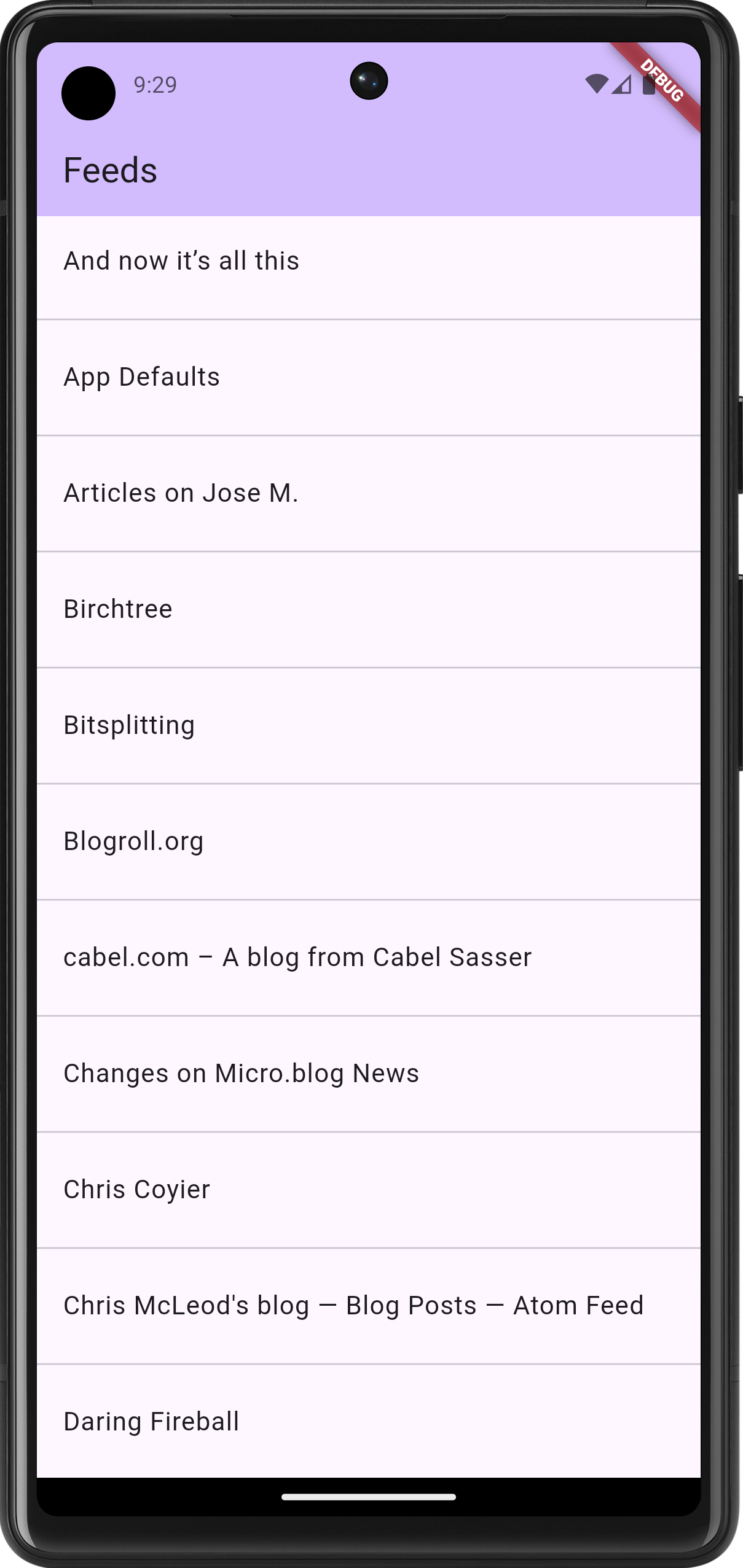
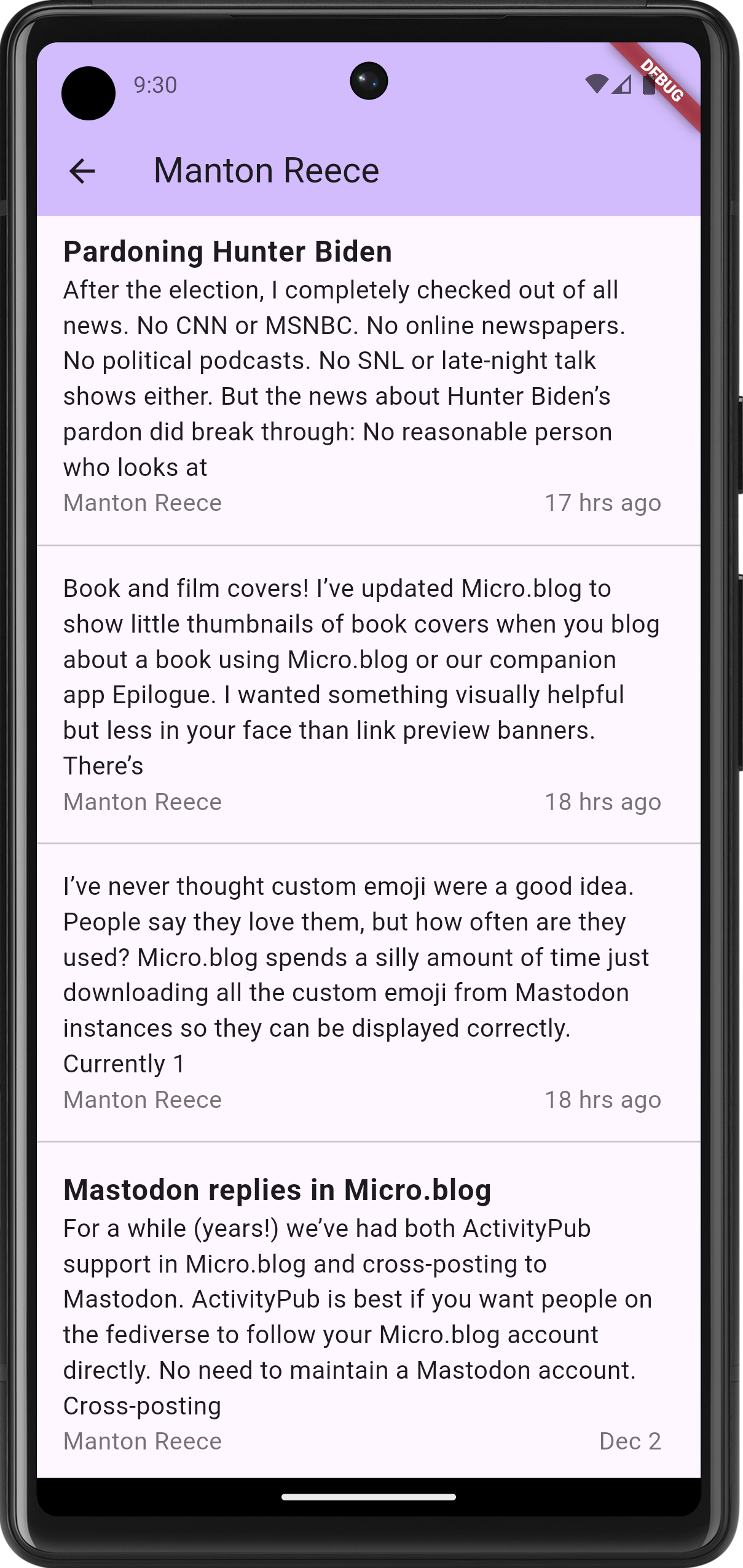
The aesthetics are taking a bit of a back seat in favour of functionality for now; I haven’t even changed the default accent colour. But the infrastructure is there: tapping a feed will bring up the entries for that feed. This is using named routes for navigation, and cubits for state management. It’s a bit more work upfront, but it does make for a neater codebase.
The biggest challenge so far was getting the actual reader view working. I hoping to use the webview plugin, but when I tried adding it, I ran into a bunch of Gradle errors. These were either class version errors or dependency errors, depending on what I tried to fix it (I didn’t get screenshots, sorry). I eventually stumbled upon this Flutter Gradle plugin migration guide, and following this, along with upgrading Java to OpenJDK 25, got Gradle working again.
But I was still getting build errors. The first couple were Gradle plugins com.android.application and org.jetbrains.kotlin.android that needed to be updated. Easy stuff. And then I got this error message:
Execution failed for task ':webview_flutter_android:compileDebugJavaWithJavac'.
> Could not resolve all files for configuration ':webview_flutter_android:androidJdkImage'.
> Failed to transform core-for-system-modules.jar to match attributes {artifactType=_internal_android_jdk_image, org.gradle.libraryelements=jar, org.gradle.usage=java-runtime}.
> Execution failed for JdkImageTransform: /Users/leonmika/Library/Android/sdk/platforms/android-34/core-for-system-modules.jar.
> Error while executing process /Users/leonmika/Applications/Android Studio.app/Contents/jbr/Contents/Home/bin/jlink with arguments {--module-path /Users/leonmika/.gradle/caches/8.10.2/transforms/575ccd1a7426c0be21d9fe3a81898be3-05a021da-a1a7-409f-a30a-bba769b57371/transformed/output/temp/jmod --add-modules java.base --output /Users/leonmika/.gradle/caches/8.10.2/transforms/575ccd1a7426c0be21d9fe3a81898be3-05a021da-a1a7-409f-a30a-bba769b57371/transformed/output/jdkImage --disable-plugin system-modules}
Running a web search on the error revealed this Stack Overflow answer, which resolve it. There were still a few complaints about the the NDK version but after all that, the app finally launched with the web-viewer.
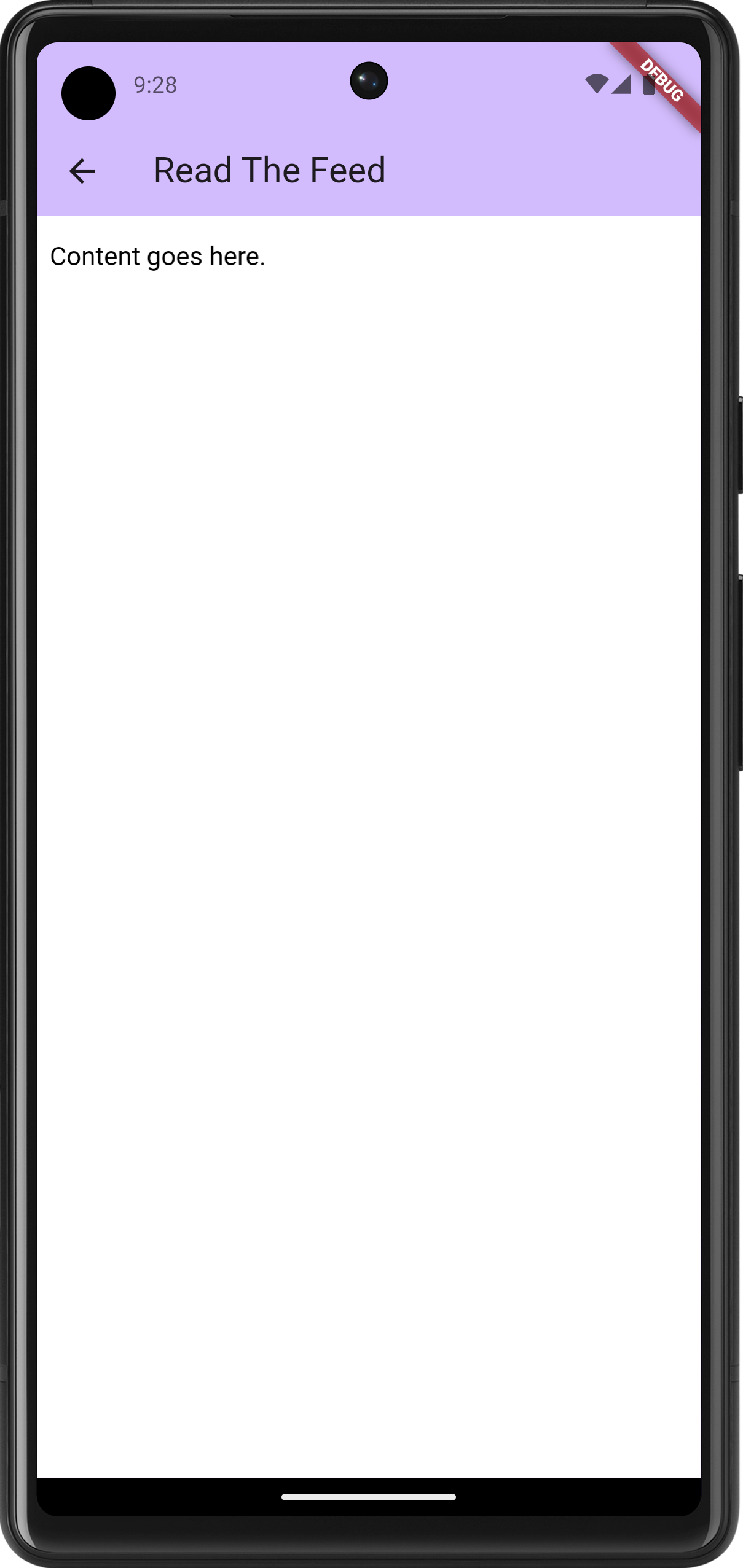
I still need to actually render the entry, plus style the HTML a bit. The immediate goal after this, once the reader view, is getting this on my phone to start playing with it. It’s just barebones for now, but I find that the sooner I can start using a project myself, the more likely I am to keep at it.
Looking for my next project to work on. I have a few ideas but my mind keeps wandering back to an RSS reader for Android. I read RSS feeds quite frequently on my phone and Feedbin’s web app is great, but I think I prefer a native app.
I just need to get over the hump of setting up my Android Studios. There’s something about starting a new project there that just sucks the life out of you.
Playing around with some possible UI design choices for that Android RSS Feed Reader. I think I will go with Flutter for this, seeing that I generally like the framework and it has decent (although not perfect) support for native Material styling.
Started looking at the feed item view. This is what I have so far:
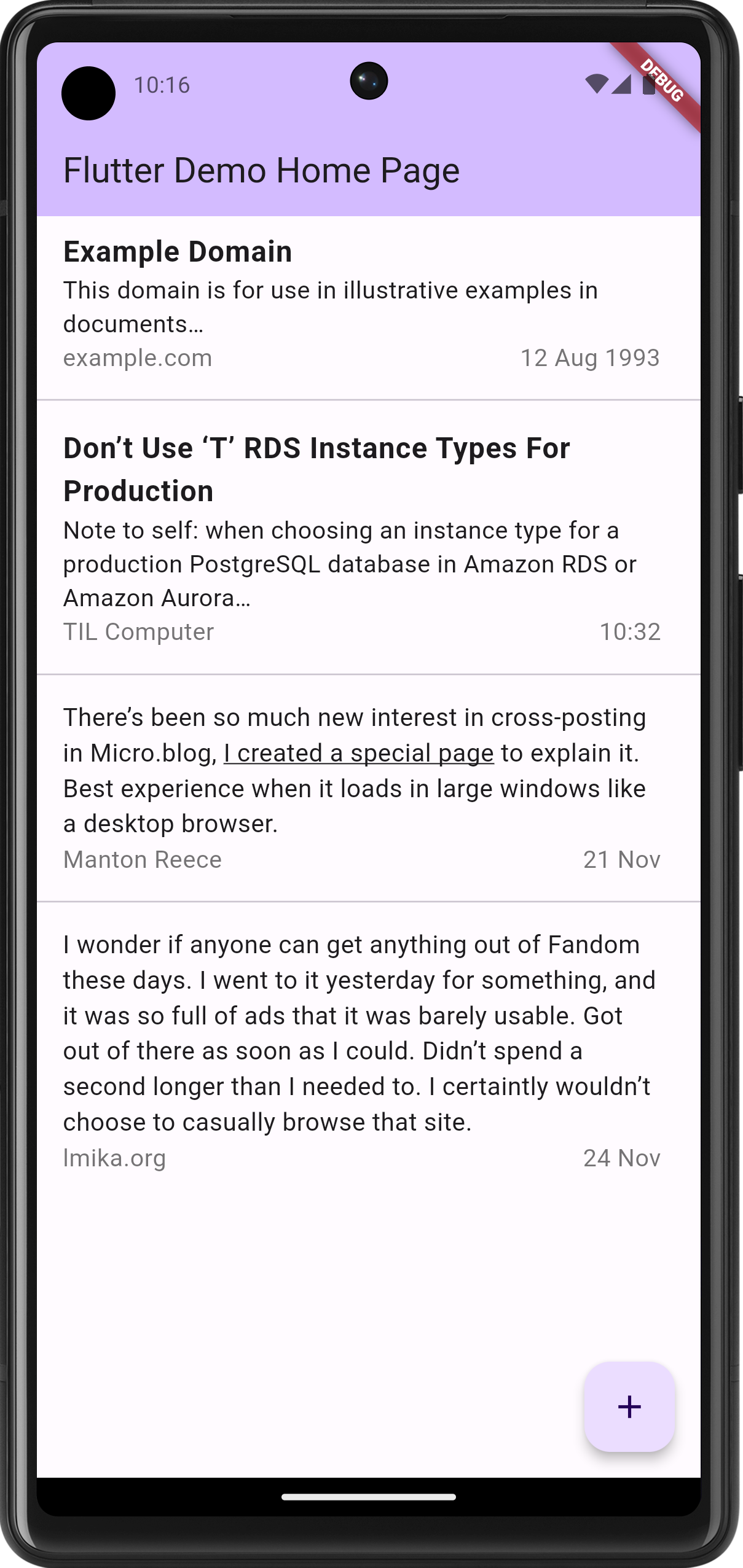
Note that this is little more than a static list view. The items comes from nowhere and tapping an item doesn’t actually do anything yet. I wanted to get the appearance right first, as how it feels is downstream from how it works.
The current plan is to show most of the body for items without titles, similar to what other social media apps would show. It occurred to me that in doing so, people wouldn’t see links or formatting in the original post, since they’ll be less likely to click through. So it might be necessary to bring this formatting to the front. Not all possible formatting, mind you: probably just strong, emphasis, and links. Everything else should result with an ellipsis, encouraging the user to open the actual item.
Anyway, still playing at the moment.
It’s done! Cyber Burger, the Pico-8 arcade game I’ve been working on for the last few months, is finished and can now be played online in a (desktop) browser. Check it out here.

I also decided to put the documentation “on-board”, as opposed to putting it on the web. Yes, it breaks from what was typical during the 8-bit gaming period, but I’ve got the space, and it makes adding illustrations easier.
Also forces me to keep it brief, which is no bad thing.
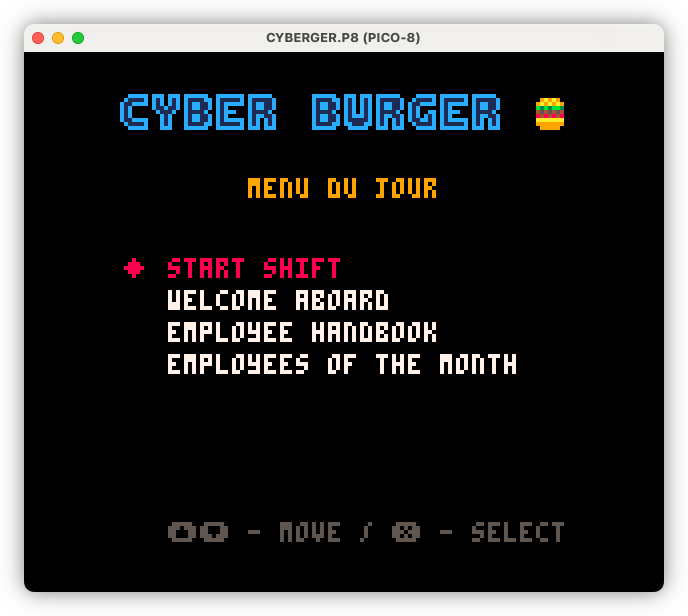
Building out the meta elements of Cyber Burger, including the “menu du jour” a.k.a. the main menu. I’ve used food-service terms for the menu items to maintain the theme, but there is a button to switch them over to more conventional names should it be too unclear.
Weekly Update - 3 Nov 2024
I probably should stop calling these “weekly updates,” seeing that they come up a lot less frequently than once a week. Maybe I should switch to something like “Sunday updates,” or maybe something closer to what this is, which is an excuse to procrastinate by writing about what I’ve been working on, rather than just working on it.
But I’m sure you’re not interested in my willowing about the frequency of these updates, so let’s just get straight to the meat of it.
Cyber Burger
All the logic, graphics, and sound-effects for power-up/power-downs are now finished. They now spawn in randomly, with a frequency and specific types dictated by the current stage. I also added the notion of a “milkshake bonus” which awards the player a bonus multiplier for a short amount of time.
I’ve also made a few balancing changes around demerits. Based on my own testing, I was pretty blasé about loosing demerits, as you could recover a demerit every time you finish a burger. I wanted to discourage that, so I changed things around a little. You still loose demerits if you screw up the burger your trying to build — such as making it too high or not catching the correct item — but you no longer recover demerits for every burger you complete. Instead, you recover one demerit for every $50 you’re awarded. This is now every three to four burgers, depending on how sophisticated they are, which I hope would make loosing demerits something the player would want to avoid.
There’s still the difficulty curve stuff left to do, but I think I’ll start working on the meta elements, like the title screen, main menu and high score tables. I can probably leave out the addition of stages and a difficulty curve if I’m honest, but I would like to have a decent title and menu screen.
The other thing to do is write the manual. I made a start the other day, but there’s much left to do on this front. Part of me wonders whether it make sense adding “on-board documentation.” But part of the fun of using Pico-8 on this project is to imagine a time where this game came out during the late 70’s and early 80’s and the 8-bit era of home consoles. And those games didn’t have on-board documentation. That said, I might add a quick start guide for those that didn’t RTFM.
UCL
I’ve been using that tool I’ve written for work quite often so there was a need to add some additional features to UCL. The biggest one was adding exceptions, but there’ve been a lot of little things like rounding out the standard library.
All the code written in a rush is starting to weigh this project down though, and I do think I’ll need to do some refactoring to tidy things up a little. I may need to work on documentation too, just for my own sake more than anything else. I doubt this would be anything more than the toy language it currently is, but it does have it’s uses, and whenever I need to reference a built-in, I’m always going to the source code. Which is fine, but I think I can do better on this front.
Other Projects
A few other things I worked on during the last fortnight:
So that’s the update for this past fortnight.
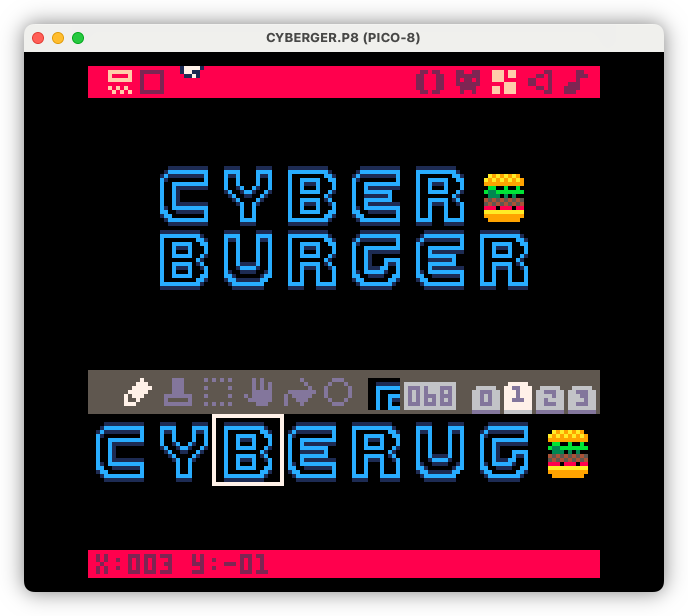
Title design this morning. Trying to get as close as I can to the Cyberspace Raceway font as my pixel art skills will allow for.
Try-Catch In UCL - Some Notes
Stared working on a try command to UCL, which can be used to trap
errors that occur within a block. This is very much inspired by
try-blocks in Java and Python, where the main block will run, and if any
error occurs, it will fall through to the catch block:
try {
echo "Something bad can happen here"
} catch {
echo "It's all right. I'll run next"
}
This is all I’ve got working at the moment, but I want to quickly write some notes on how I’d like this to work, lest I forget it later.
First, much like everything in UCL, these blocks should return a value. So it should be possible to do something like this:
set myResults (try {
result-of-something-that-can-fail
} catch {
"My default"
})
--> (result of the thing)
This is kind of like using or in Lua to fallback to a default, just
that if the result fails with an error, the default value can be
returned from the catch block. In might even be possible to simply
this further, and have catch just return a value in cases where an
actual block of code is unnecessary:
set myResults (try { result-of-something-that-can-fail } catch "My default")
One other thing to consider is how to represent the error. Errors are
just treated out-of-band at the moment, and are represented as regular
Go error types. It might be necessary to add a new error type to
UCL, so that it can be passed through to the catch block for logging
or switching:
try {
do-something
} catch { |e|
echo (cat "The error is " $e)
}
This could also be used as the return value if there is no catch
block:
set myResult (try { error "my error" })
--> error: my error
Another idea I have is successive catch blocks, that would cascade one after the other if the one before it fails:
try {
do-something
} catch {
this-may-fail-also
} catch {
echo "Always passes"
}
Unlike JavaScript or Python, I don’t think the idea of having catch
blocks switching based on the error type would be suitable here. UCL is
dynamic in nature, and having this static type checking feels a little
wrong here. The catch blocks will only act as isolated blocks of
execution, where an error would be caught and handled.
Finally, there’s finally, which would run regardless of which try or
catch block was executed. I think, unlike the other two blocks, that the
return value of a finally block will always be swallowed. I think this
will work as the finally block should mainly be used for clean-up, and
it’s the result of the try or catch blocks that are more important.
set res (try {
"try"
} catch {
"catch"
} finally {
"finally"
})
--> "try"
Anyway, this is the idea I have right now.
Update — I just realised that the idea of the last successful try block return an error, rather than letting it climb up the stack defeats the purpose of exceptions. So having something like the following:
try { error "this will fail" }
Should just unroll the stack and not return an error value. Although if there is a need to have an error value returned, then the following should work:
try { error "this will fail" } catch { |err| $err }
--> error: this will fail