
-
Your Dev Environment is Not Your Production Environment
There will be certain things you’re going to need to do in your development environments that you should never do in production. That’s pretty much a given: playing around with user’s data or potentially doing something that will cause an incident is generally not a good idea. But there are things you shouldn’t do in prod that you may need to do in dev. And make no mistake, there may be a legitimate need to do these things. Continue reading →
-
It’s so much easier to post about how something others have worked on could be made better than it is to write about what I’ve been working on. I think there’s room for both on this blog, but I feel the balance is too many posts on the former and not enough on the latter. I’ll try to do better here.
-
Don’t want to turn this into the “look at what’s wrong with Atlassian’s software” blog, but I found another thing that annoys me about Confluence:
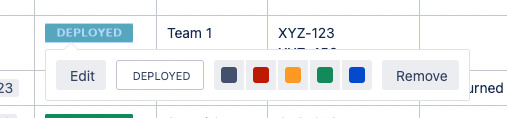
Clicking on a status label brings up a picker, giving you options to change the colour, etc. The picker appears below the label, which usually means it blocks the next thing I want to modify, like the status label in the row below. I need to dismiss the picker first before I can select the label I want to change next.
It’d probably be better if the picker appeared above the label instead.
This is also an issue with dates and links to Jira tickets as well, although with Jira tickets you’re required to make edits within a modal.
-
Given the number of times I make wiki pages that are little more than pseudo-databases-as-a-table, it would be nice if Confluence had a way to make this better. Maybe something like Notion databases, just to organise information a little neater than the free-for-all you get from tables.
-
Day 28: workout
It was a quiet evening in the gym that evening, which is unusual for a Thursday. I suspect that bolt of lightening that blew up a nearby transformer scared people away. #mbsept

-
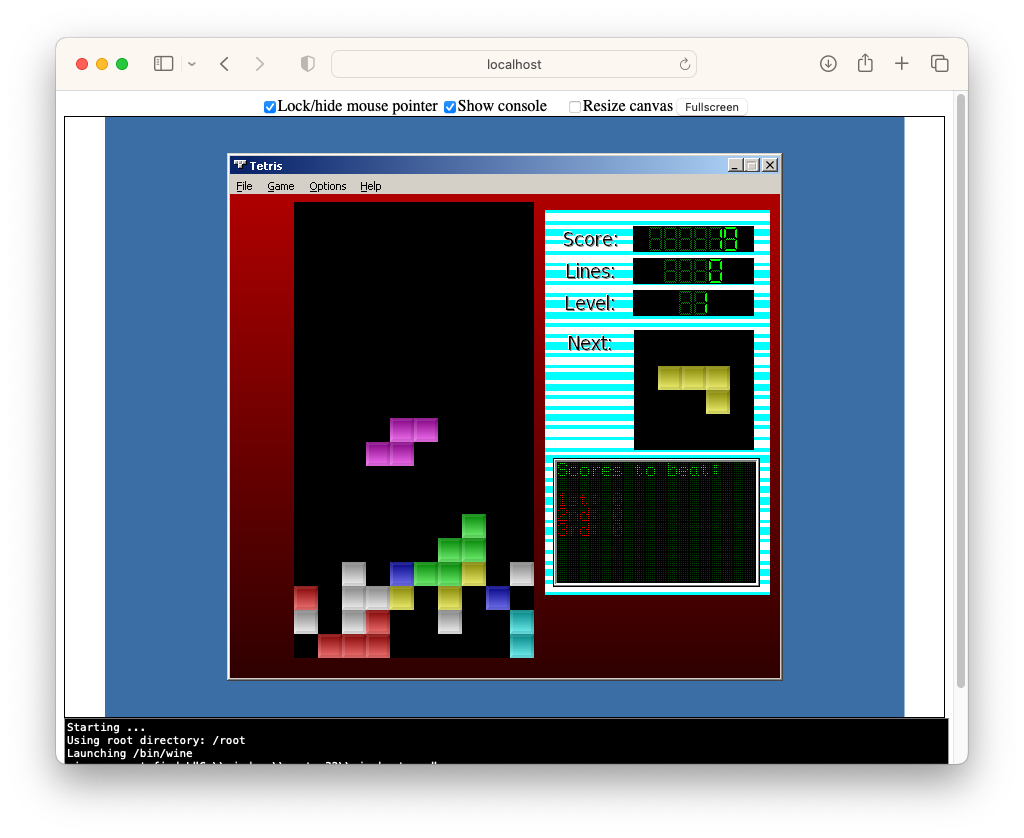
After having some success getting my early QBasic programs running in the browser I had a bit of a look this morning to see if I could do the same for my Delphi apps. I found a project called BoxedWine which looks promising. Seems to be a minified version of Wine that that runs in browser using WASM.
I downloaded the example and had a bit of a play around with a Tetris clone I built. It worked… to a degree. It was a little slow, and some of the colours were off. But it ran, and was actually usable.
I did another test with an app that used OpenGL, which was less successful.
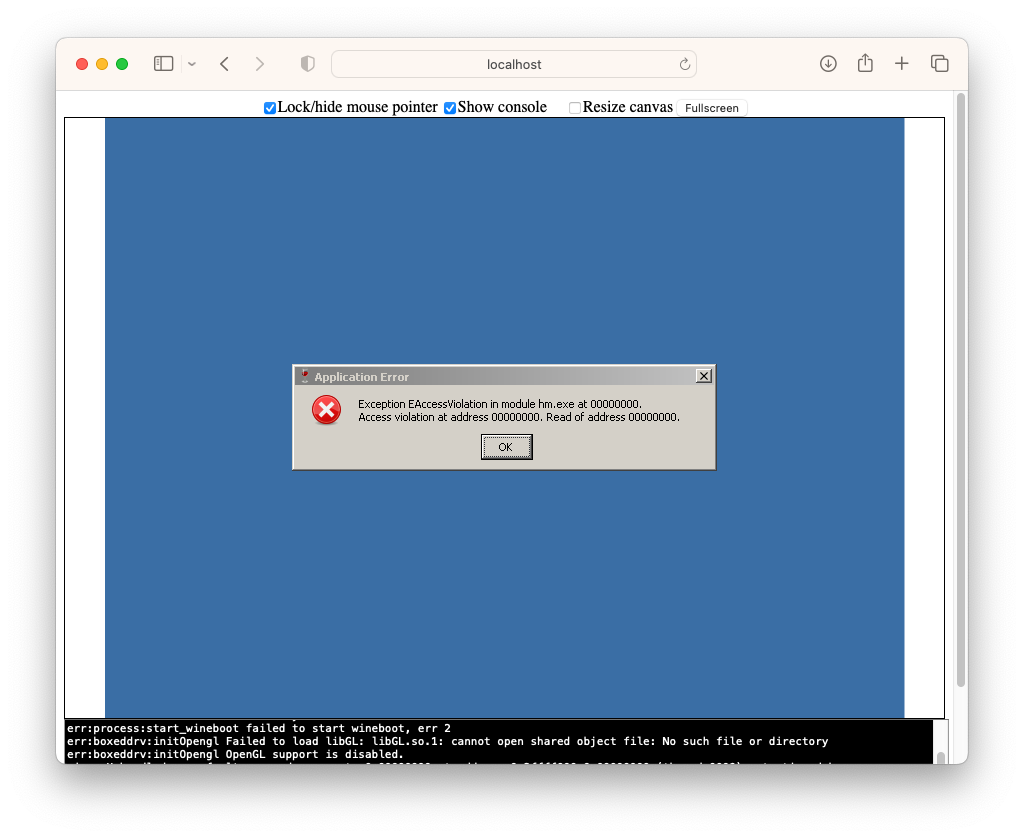
I think some of the OpenGL shared objects are not in the minified Wine distribution it was using. It might be possible to include them: there are instructions, and a few demos, on how to load files from the full Wine distribution on demand.
Anyway, not sure if I’ll pursue this further but it was a fun little exercise nonetheless. I’m pretty impressed that this is even possible at all. The Web stack is pretty freaking awesome.
-
Day 27: embrace
Photo credit goes to my sister, who captured this pair showing affection for each other. #mbsept

-
Day 26: beverage #mbsept

-
Day 25: flare #mbsept

-
Day 24: belt
Sometimes a 40 inch belt is just a 40 inch belt, as I realised when I bought mine (honestly, they should describe belt lengths as a range: 38 — 42 inches, for example). #mbsept

-
The day has arrived. After a meeting in the new office we were told to pack up our things. We won’t see them again until our desks in the new office are ready. 📦
On my last bus ride home from Port Melbourne. Can’t say that I’ll miss it. 👋🚌
-
Lost another comment to Jira today. Oof! Don’t get attached to anything you write there. Jira will eat your comment and you’ll never see it again. 🙁
You would’ve though, after 15 years of using Jira, that I’d learn this by now. 🤦♂️
-
Electrification of Melbourne Suburban Railways Plaque
Found this plaque while passing through Southern Cross station this morning. I didn’t have time to read it, and the subject matter looks really interesting to me (Trains? Power Lines? What’s not to love? 😀). I also don’t know how long it’ll be up for, and I’ve been burned in the past of not capturing something when I had the chance. So I’m posting photos of it here for posterity reasons. Continue reading →
-
I’ve got a bit behind my photos for the September Photo Challenge. I’ve got one for today that I’d really like to post. But I can’t do so until I post the days I’ve missed, lest they appear out of order. I better get on that.
-
I was planning to go into the office today. The train went two stops in before everyone was instructed to transfer to busses. Now on a train heading the other way so I can work from home instead. It’s great that this is now an option.
-
Day of firsts today. Had a session of indoors go-karts as part of a bucks party. Loads of fun. Won the wooden spoon (although only 3 second slower than the winner).


-
Started practice sessions again as I’ve been asked to play the piano at an event. I thought I’d try something new this time, and start recording them. Sometimes, during these sessions, I come up with an idea or arrangement that sounds pretty good to me. But a few minutes go by and I forget exactly how I got it to sound that way. When I try to recreate it later, it usually comes up short. So I want to find a way to avoid that happening here.
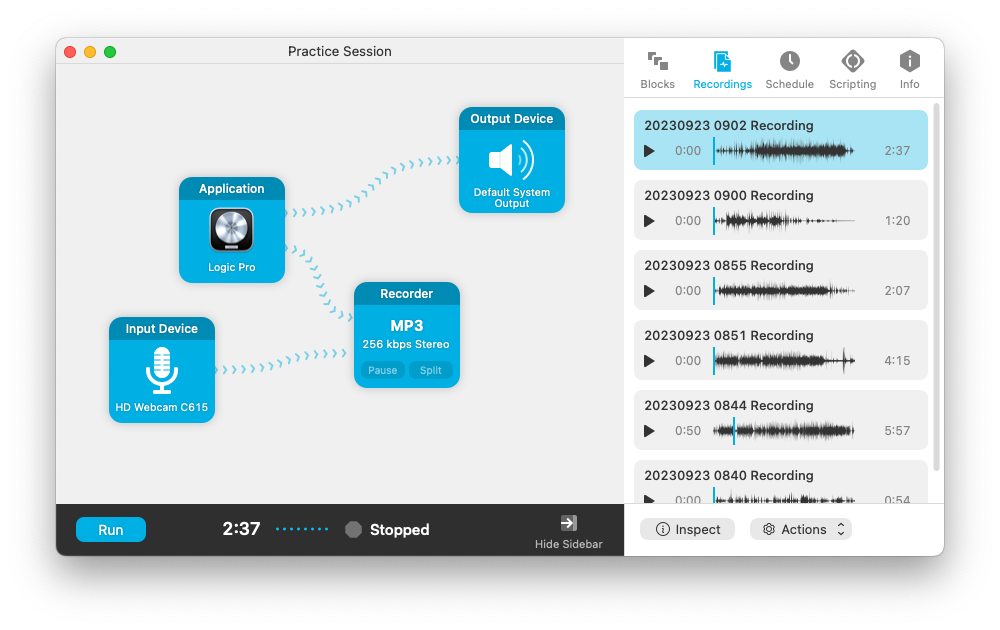
Audio Hijack is proving to be quite useful for this. I’ve got my webcam, which I’m using as a microphone, and Logic Pro being piped into a recorder. My (music) keyboard is hooked up via MIDI and I’m using Logic Pro as a live software synth (I prefer the piano patches there). The mic is for making a running commentary of what sounded good or not. I didn’t want to monitor of my speech but I did need to hear Logic Pro, so that’s piped directly to the output and through my headphones.
This is the first session I’ve tried this and so far it worked well. Hardly stage quality — the mic is pretty ordinary, and picks up the action on the keyboard — but it’s good enough for what I need.
-
Day 23: day in the life of
Saturday mornings usually mean an extended walk to the cafe for breakfast. I took some photos of my route today. This is probably my favourite one. #mbsept

-
It would be nice if there was an option in Mastodon’s web-app to turn off displaying alt text as a popup when mousing over an image. Some alt test descriptions are quite comprehensive, and while I’m browsing the feed, my mouse cursor lands naturally in the centre of an image if the post has one. I start looking at the image and then the popup appears and blocks a significant part of the it.
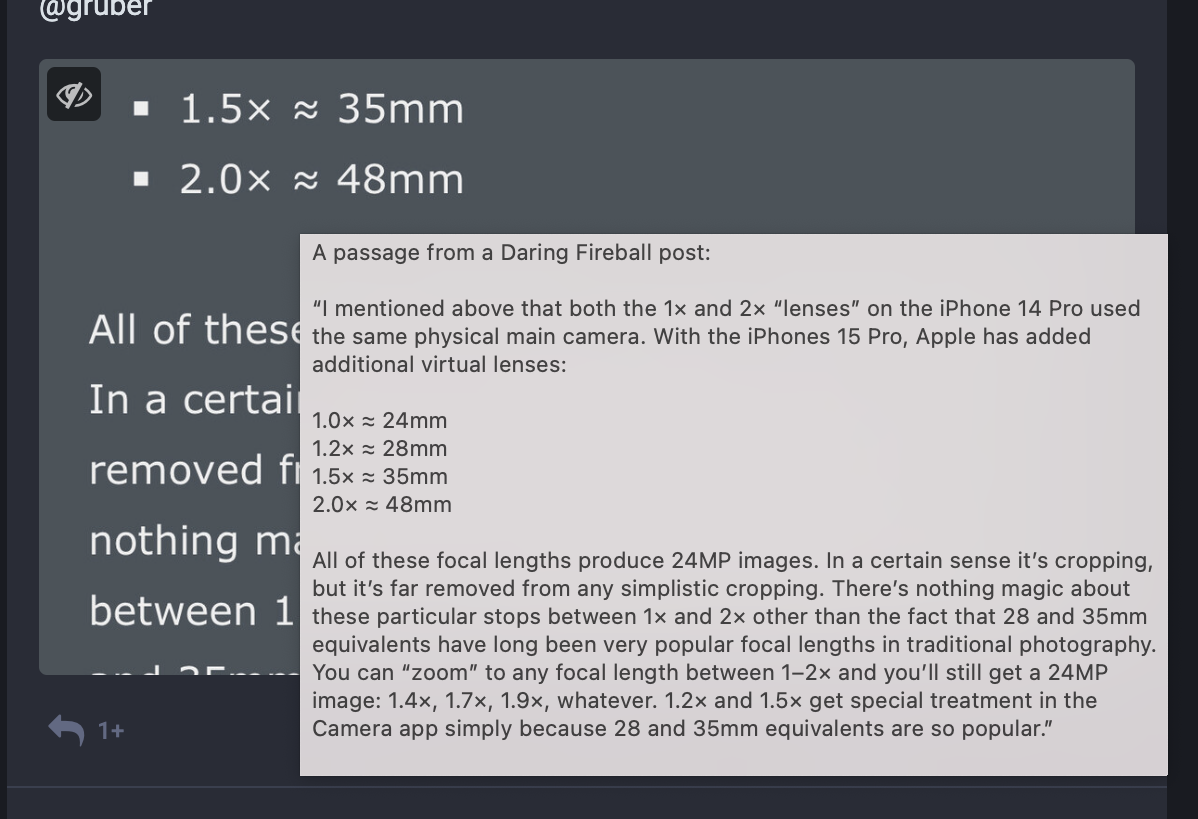
I’m perfectly fine with having the popup show up by default, but having the option to turn it off would be nice. An even better option would be to position the alt text below the image, so that it appears without obscuring the image at all. That would also be welcomed.
-
Day 21: fall
This shed hasn’t fallen down yet, but it’s in a bit of a precarious state. #mbsept

-
Day 20: disruption
Going to take this opportunity to say that I like the design of our road works signs. They have a standard frame from which you can swap out the sign panels based on what you need to convey. Beautiful modularity. #mbsept

-
🎵 Pippin, the New Broadway Cast Recording, by Stephen Schwartz.
One of the defining memories of my life was in Year 10, playing the viola in the pit orchestra of our high-school production of Pippin. Good times.


