
-
Oh, it turns out it’s an older style of referencing targets and is no longer supposed to be used. That’s a shame.

-
Upgraded my work laptop to Sequoia. “Love” the experience that this new version provides, especially the mouse-and-patience exercise I get in the morning. 👎
<img src=“https://cdn.uploads.micro.blog/25293/2024/cleanshot-2024-11-26-at-07.30.252x.png" width=“600” height=“541” alt=“Three permission requests stacked up, with the top one displayed asking if an app called “Obsidian” can find devices on local networks, with options to “Don’t Allow” or “Allow”.">
-
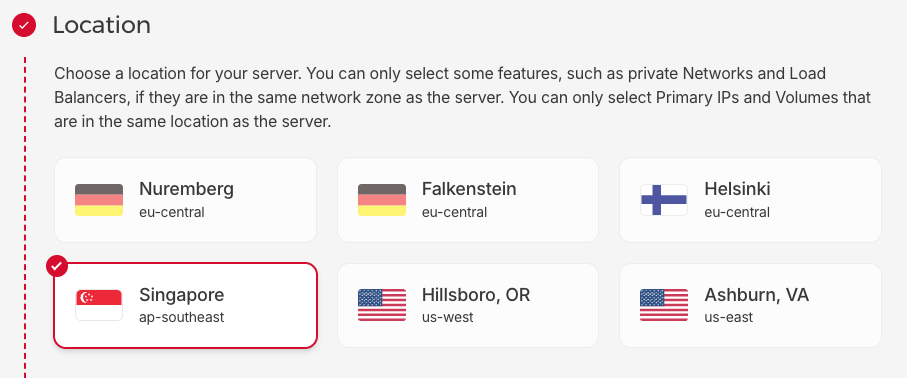
Now this is cool: Hetzner has opened up a region in Singapore. The tyranny of distance is starting to abate.
-
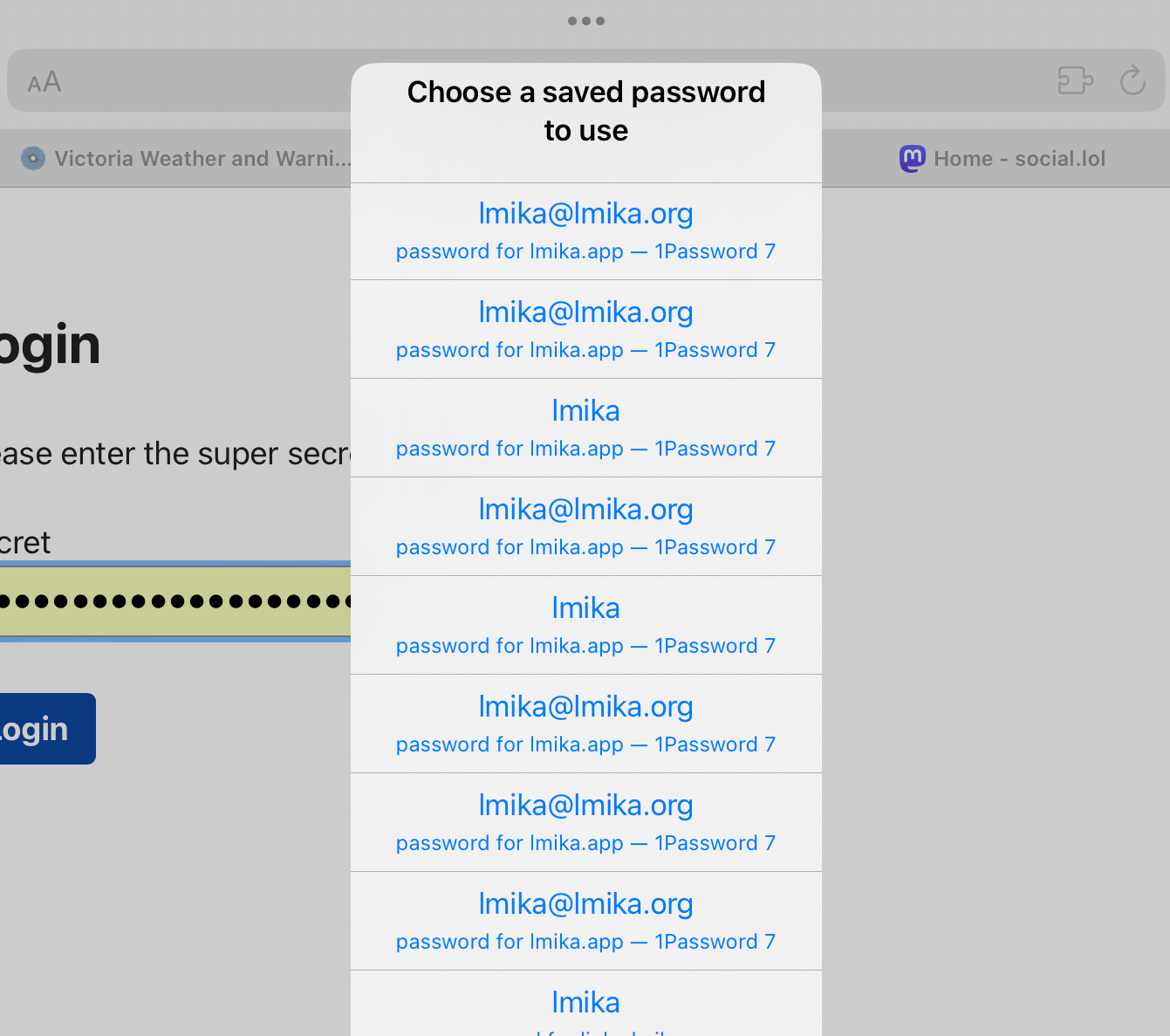
Now that my 1Password subdomain woes with Android Vivaldi has been tamed, it’s time to turn my attention to Safari:
-
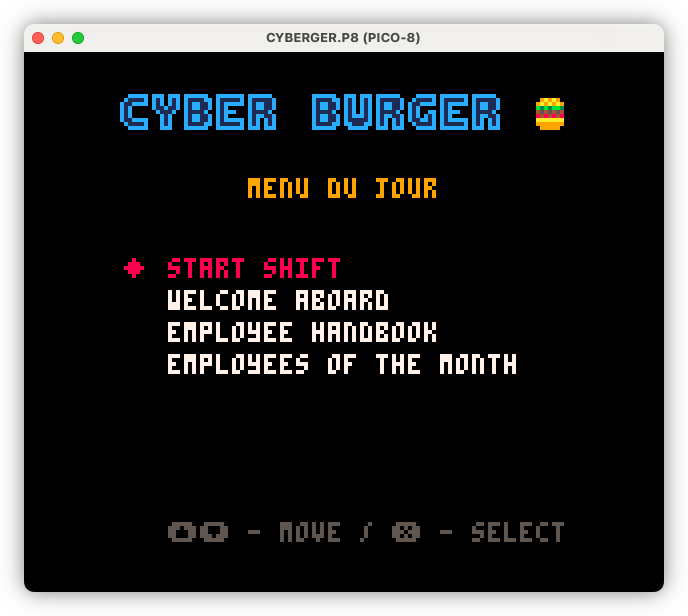
Building out the meta elements of Cyber Burger, including the “menu du jour” a.k.a. the main menu. I’ve used food-service terms for the menu items to maintain the theme, but there is a button to switch them over to more conventional names should it be too unclear.
-
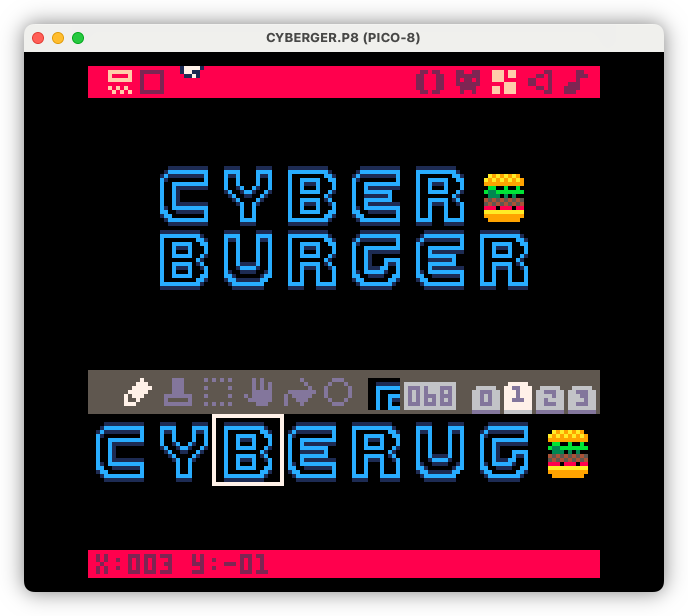
Title design this morning. Trying to get as close as I can to the Cyberspace Raceway font as my pixel art skills will allow for.
-
I finished my experiment with htmgo, building the worlds most inefficient world clock. It uses HTMX swapping to get the time from the server every second.
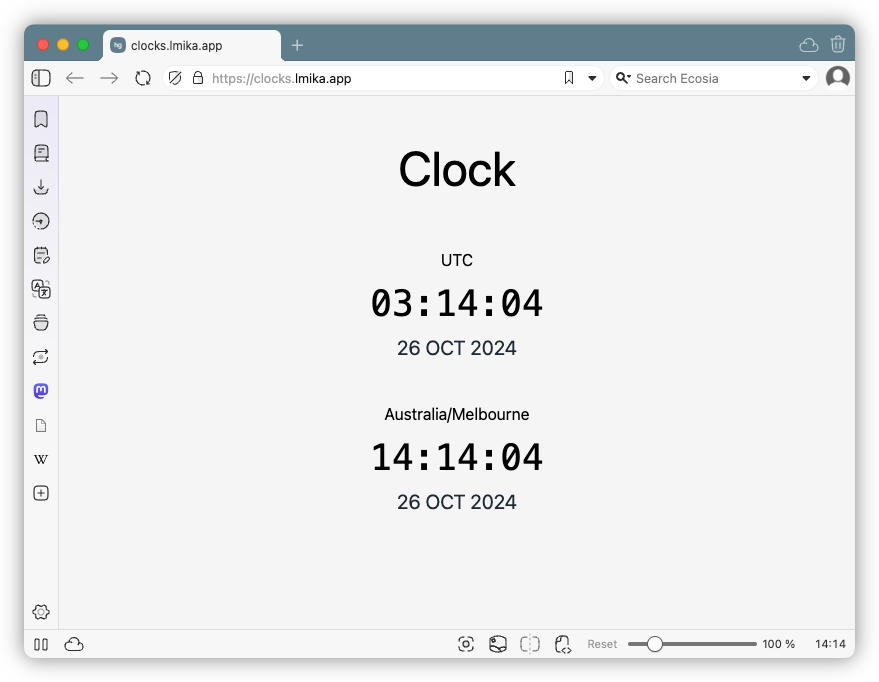
It’s an interesting framework. Not sure it’s fully ready yet (you can’t change the bind port, for example) but might be useful in the future.
-
I was poking around Dave Winer’s Software Snacks — a brilliant name for those — and I stumbled across Little Card Editor. Decided to give it a try.

-
I don’t use Wordpress so this war between Matt Mullenweg and WP Engine is little more than #internet-drama to fuel my amusement. But Matt’s recent actions in this battle have started dragging users into the crossfire, and this is something I absolutely do not like. First by the blocking access to the plugin directory for those using WP Engine, and now by adding childish, your-with-me-or-agents-me UI elements on the wordpress.org login page:
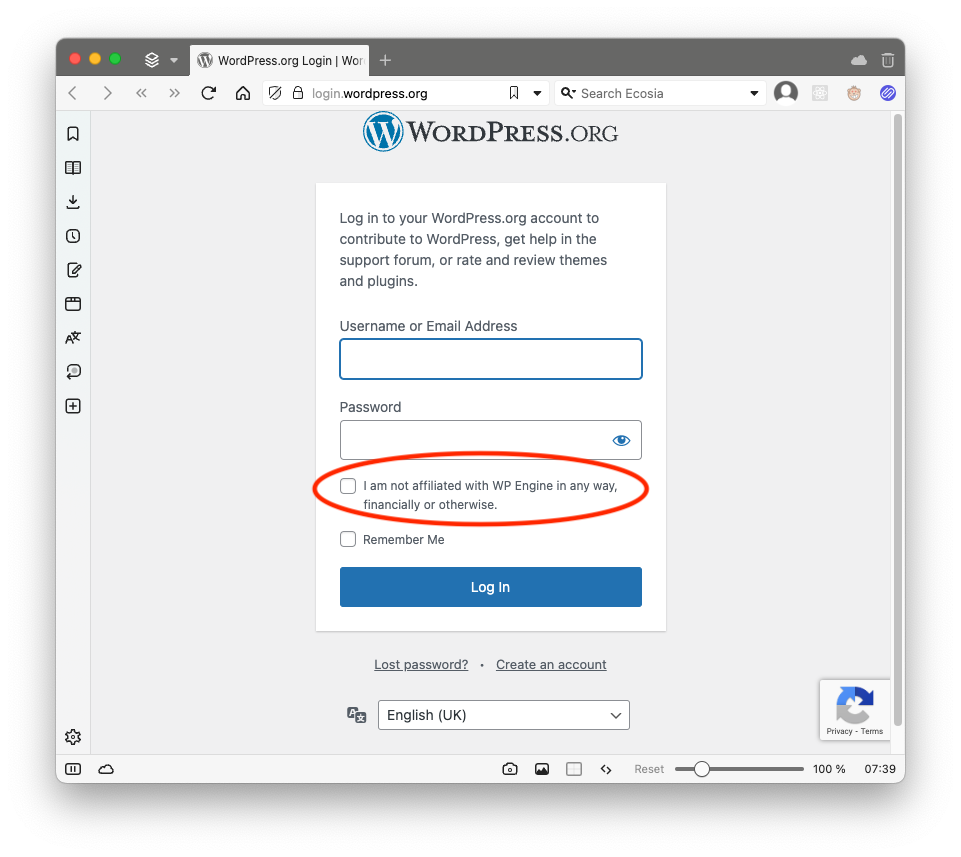
I had to see it for myself to believe it. Granted, this looks to be a login form for plugins and forums, not actual blogs. But even so, Matt, is this necessary? You may have had a reason for going after WP Engine for some reason. I have no idea what those reasons are, and quite frankly, I no longer care. You start making changes to things in service of your war, I loose all respect for you.
I may not use Wordpress, but I do use software that’s now owned by Automattic, like Pocketcasts, and seeing this makes me uneasy. What’s to say that these won’t be used in a similar way in the future?
Edit: Part of me wonders now whether this checkbox was added in jest. No evidence to support that apart from seeing various posts on Mastodon (I don’t have evidence to support that it wasn’t added in jest). If so, then I am a fool for taking the bait and getting worked up about this. It is an indication of how vicious this fight looks to me though, where adding such a checkbox would seem like a genuine escalation.
-
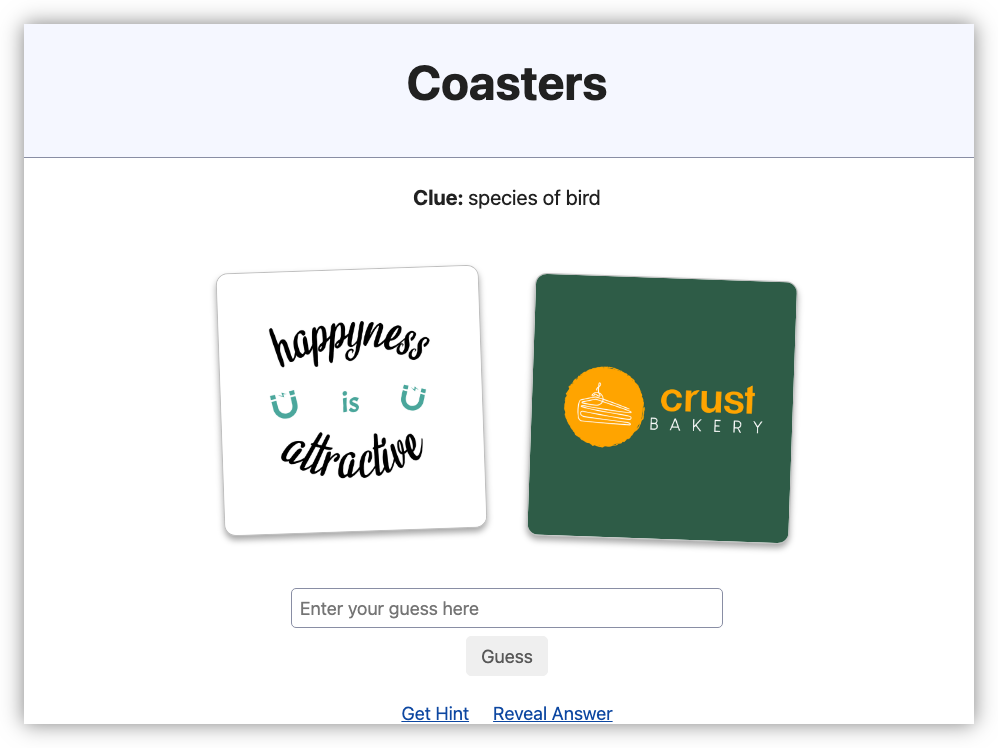
I’ve spent the last week working on a small puzzle game called Coasters, where you presented with two images and a clue, and you need to guess the word or phrase. One puzzle a day, sort of like Wordle. I’ve got 10 puzzles ready to go and I may add more but no promises. Check it out if you like.
-
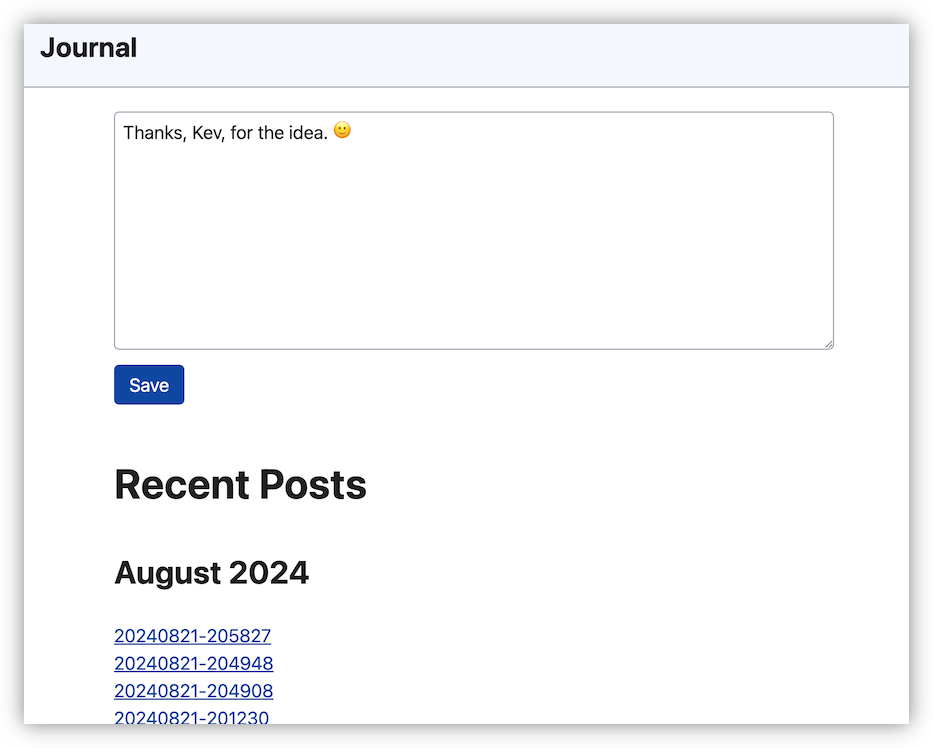
I enjoyed reading Kev Quirk’s post about building a simple journal. I’m still using Day One, but I am still thinking of moving off it. So I was inspired to build a prototype similar to Kev’s, just to see if something similar works for me. Built using Go instead of PHP, but it also uses Simple CSS.
-
Reddit’s decision to allow only Google to index their site will probably mean I’ll be seeing them far less often than I do — which is almost never anyway, and generally from the results of a search. So I’m recording this screenshot, which I call “Reddit in the results”, for posterity.
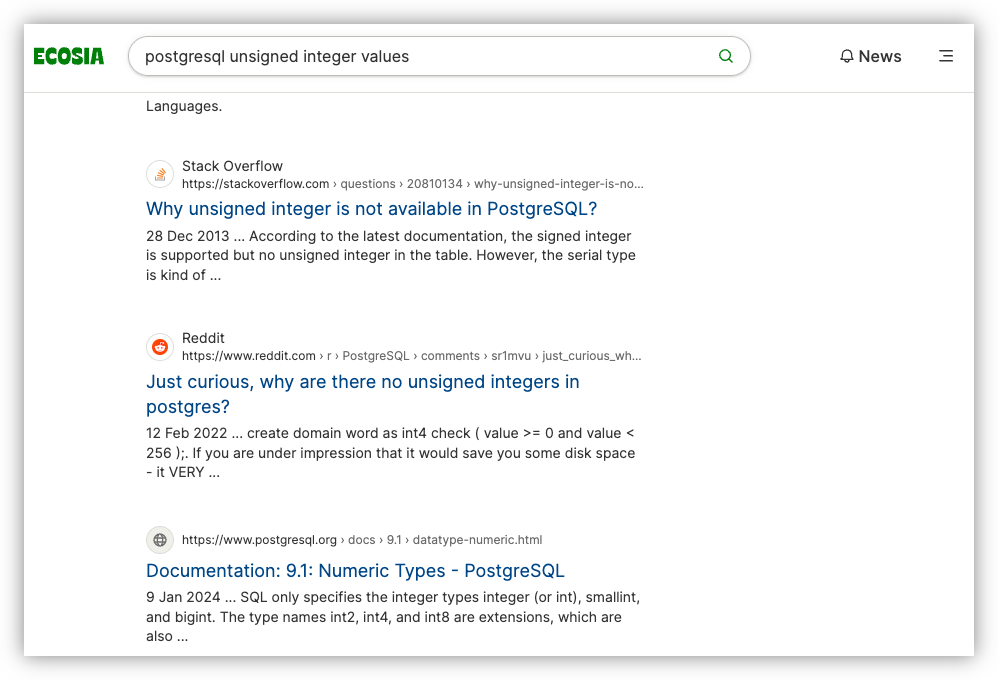
Edit: Turns out Ecosia sources some of their index from Google, so these Reddit links will likely remain in my searches. I guess that makes this post unnecessary. I’m going to keep it up though, for posterity of my unnecessary effort to post for posterity. 😄
-
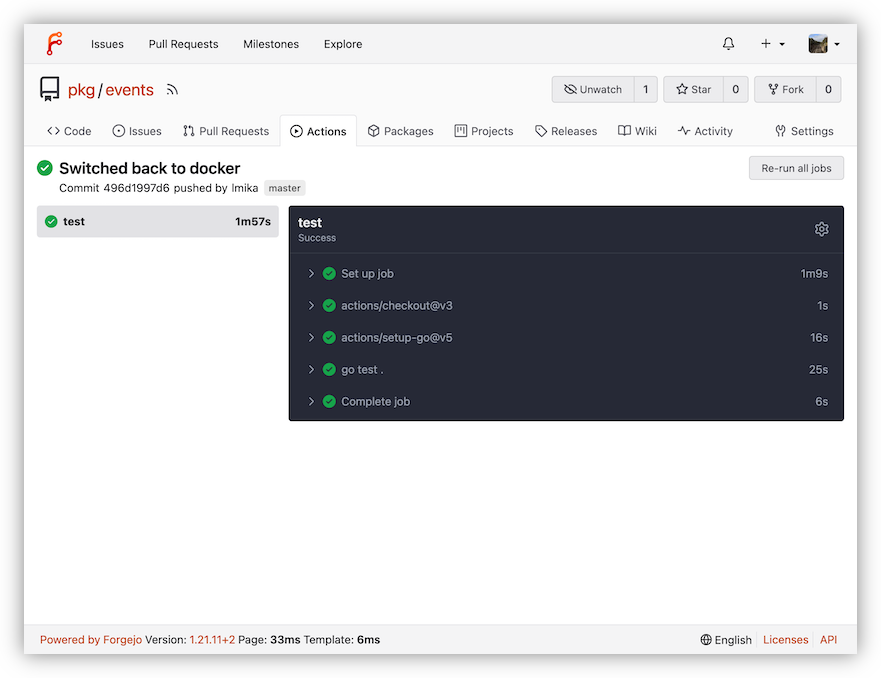
Mark the date. First successful CI/CD run of a Go project running on my own Forgejo instance, running in Hetzner. 🙌
-
Coding standards at work calls for US English in our codebase. So I’m typing words like “color,” “initialize,” and “data center.” And it pains me. I know that’s irrational but, you know, I never claimed to be rational when it comes to things like this.
At least the spell-checker’s on my side.

-
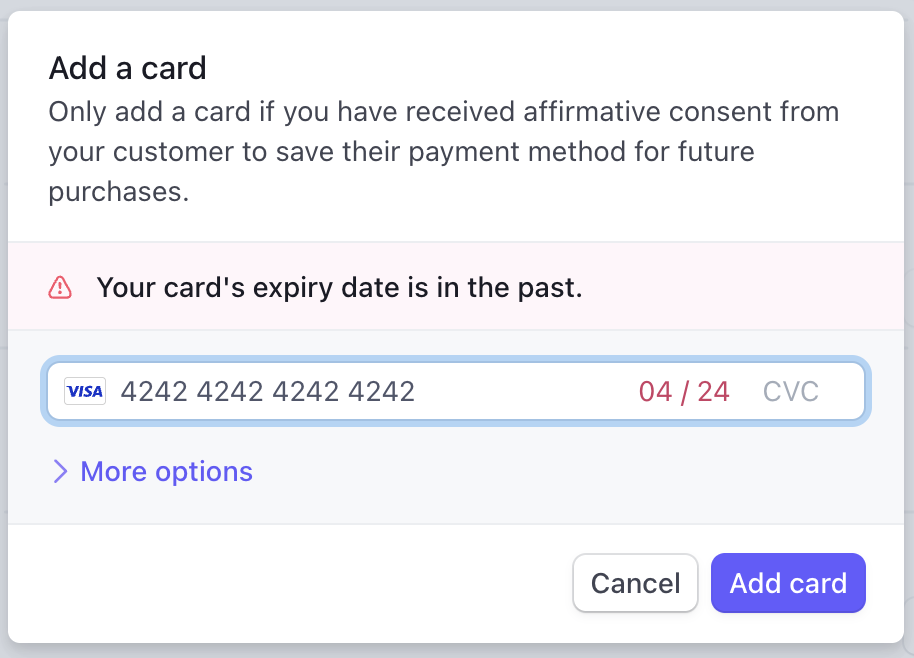
For the last few years, I’ve been using 4/24 as the expiry date of test credit cards within Stripe. Well those days are literally in the past now.
-
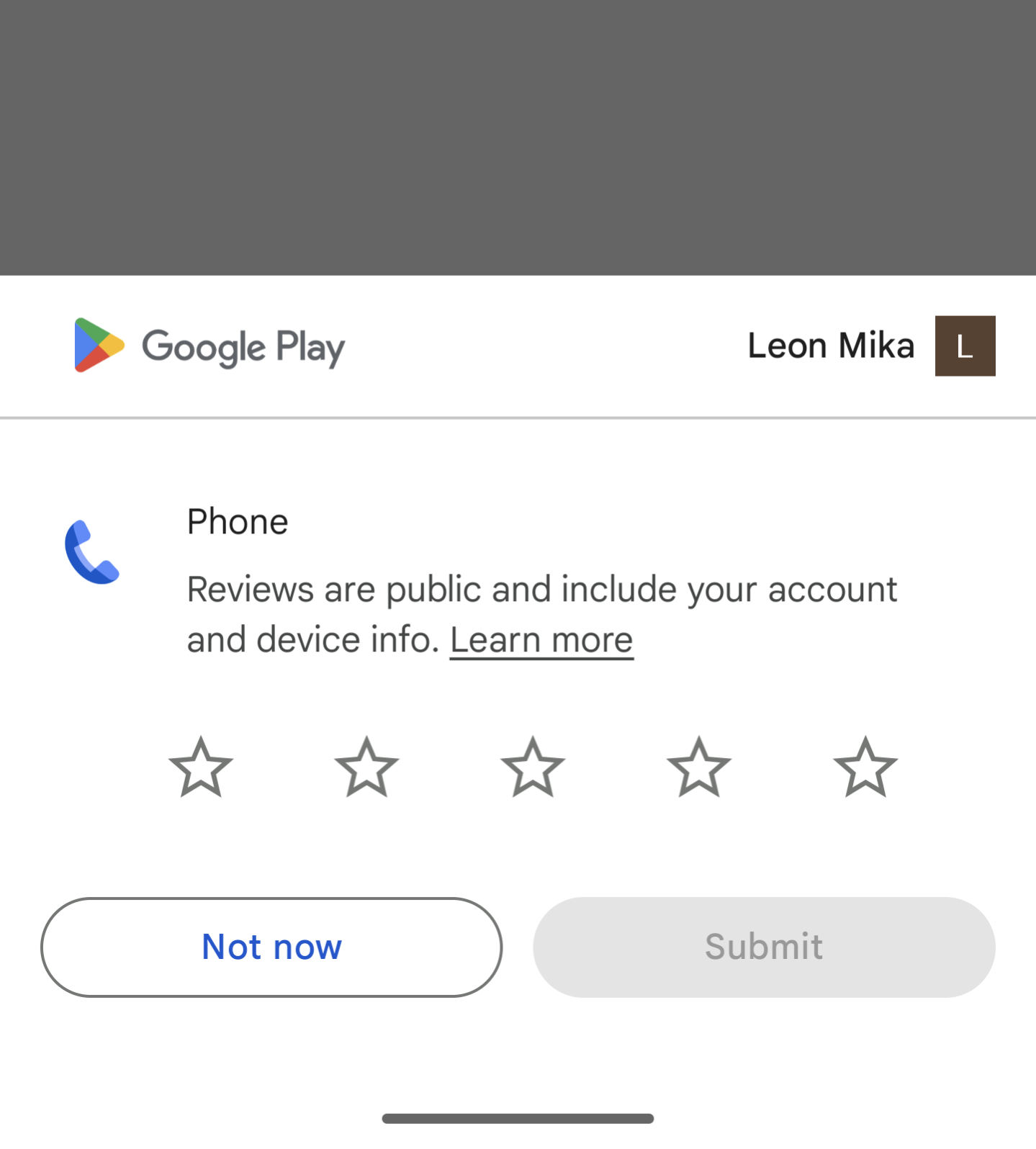
Interesting to see Google starting to solicit reviews for apps that came with the phone, such as the… Phone.
-
Love the new categories feature in Scribbles. Went back and added them to the posts on Coding Bits and Workpad. They look and feel great.
-
Took a while to troubleshoot why my shell script wasn’t running in Keyboard Maestro. Turns out I needed to add
#!/bin/zsh -lto launch it with ZSH, with the-lswitch to read my zprofile dot file.<img src=“https://cdn.uploads.micro.blog/25293/2024/screenshot-2024-04-16-at-8.10.49am.png" width=“600” height=“310” alt=“Screenshot of a Keyboard Maestro “run shellscript” step with the hash-bang line set to /bin/zsh with the -l switch”>
-
Blogroll ported to Micro.blog and placed in a sidebar on the post list screen using Tiny Theme Microhooks. I’ve yet to port the Blogroll page, and may trim some of the recommendations appearing in the sidebar, but not bad for a first pass.
-
Photo Bucket Update: Exporting To Zip
Worked a little more on Photo Bucket this week. Added the ability to export the contents of an instance to a Zip file. This consist of both images and metadata.
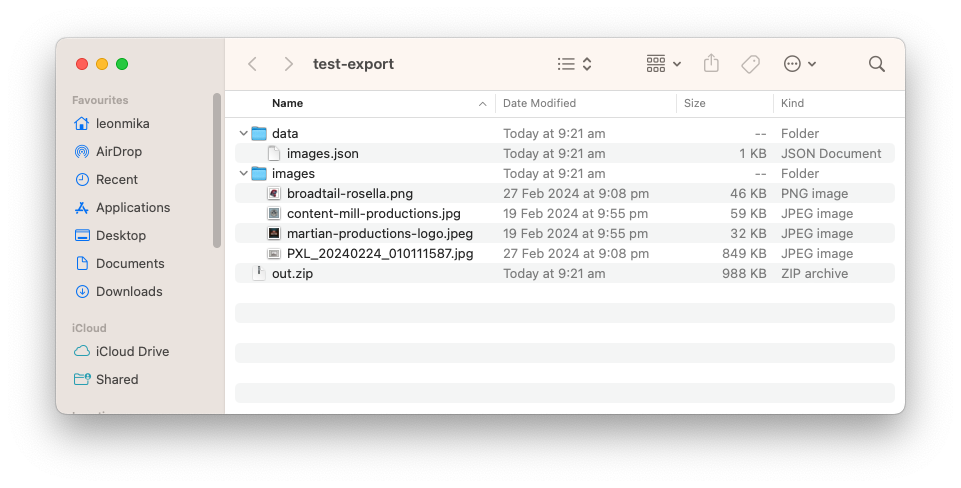
I’ve went with lines of JSON file for the image metadata. I considered a CSV file briefly, but for optional fields like captions and custom properties, I didn’t like the idea of a lot of empty columns. Better to go with a format that’s a little more flexible, even if it does mean more text per line.
Continue reading → -
Photo Bucket Update: More On Galleries
Spent a bit more time working on Photo Bucket this last week1, particularly around galleries. They’re progressing quite well. I’m made some strides in getting two big parts of the UI working now: adding and removing images to galleries, and re-ordering gallery items via drag and drop.
I’ll talk about re-ordering first. This was when I had to bite the bullet and start coding up some JavaScript. Usually I’d turn to Stimulus for this but I wanted to give HTML web components a try. And so far, they’ve been working quite well.
Continue reading → -
Signed up as a lifetime member to Scribbles. Given how fun it is to use, it was an easy decision. Fantastic work, Vincent.
-
Spent some time this evening working on my image hosting tool. It’s slowly coming along, but wow do I suck at UI design (the “Edit Photo” screen needs some rebalancing).
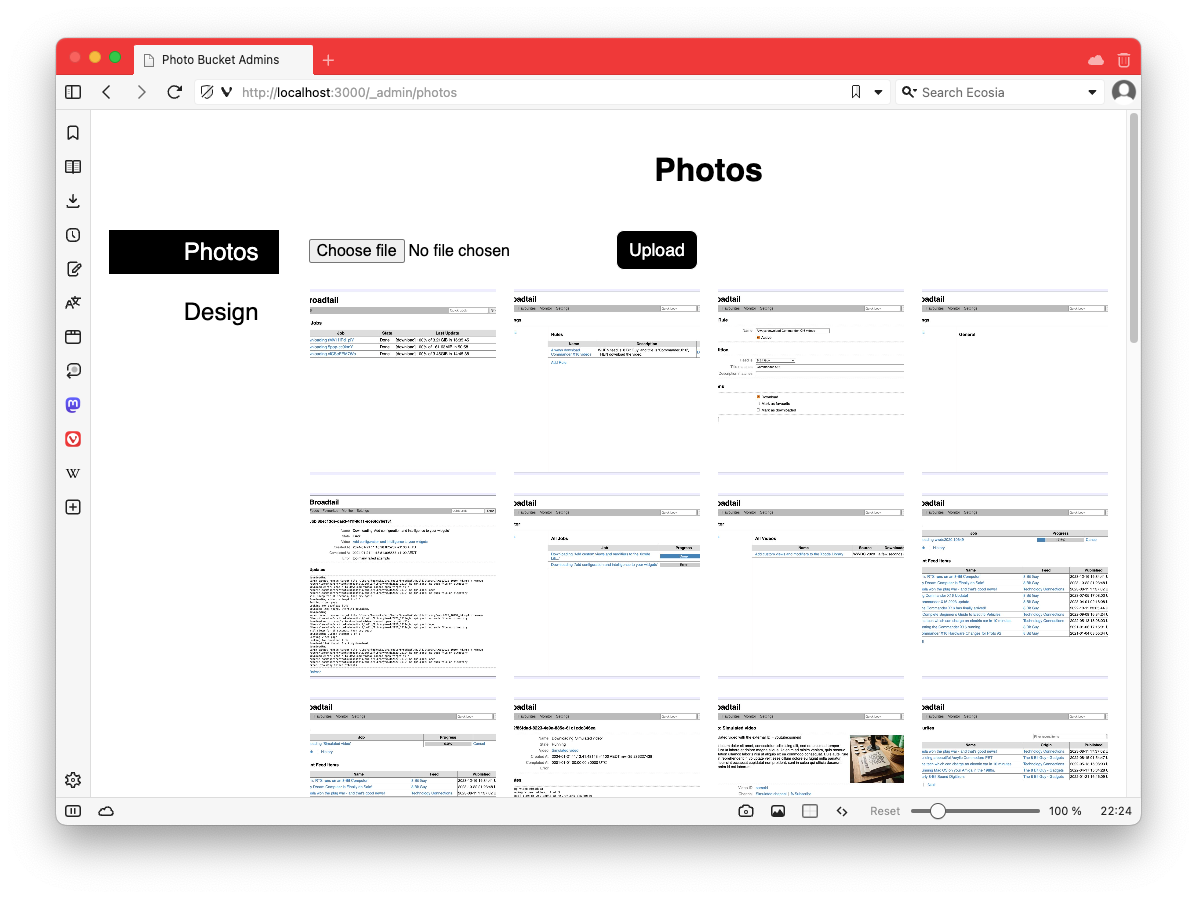
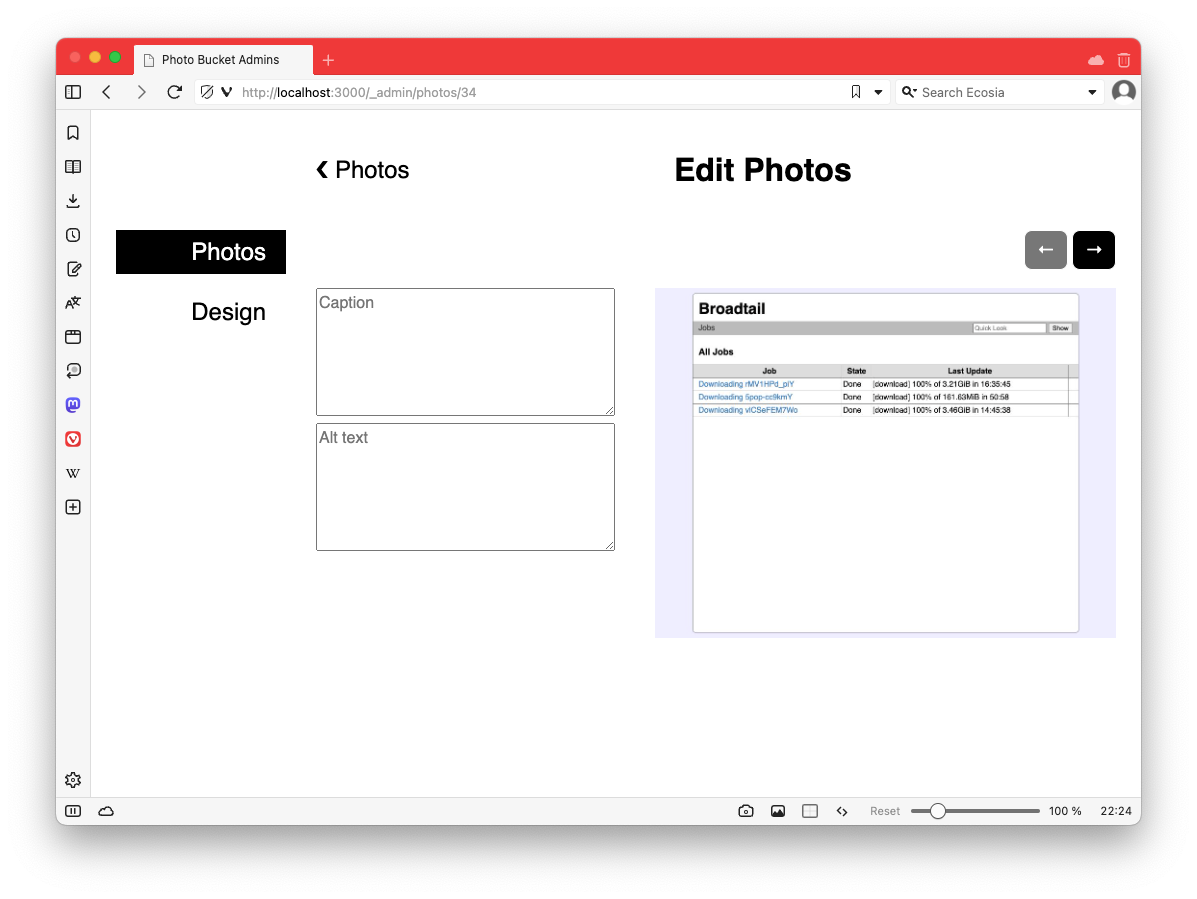
-
Test Creek: A Test Story With Evergreen.ink
Had a play with Evergreen.ink this afternoon. It was pretty fun. Made myself a test story called Test Creek which you can try out (the story was written by me but all the images were done using DALL-E).
The experience was quite intuitive. I’ve yet to try out the advanced features, like the Sapling scripting engine, but the basics are really approachable for anyone not interested with any of that.
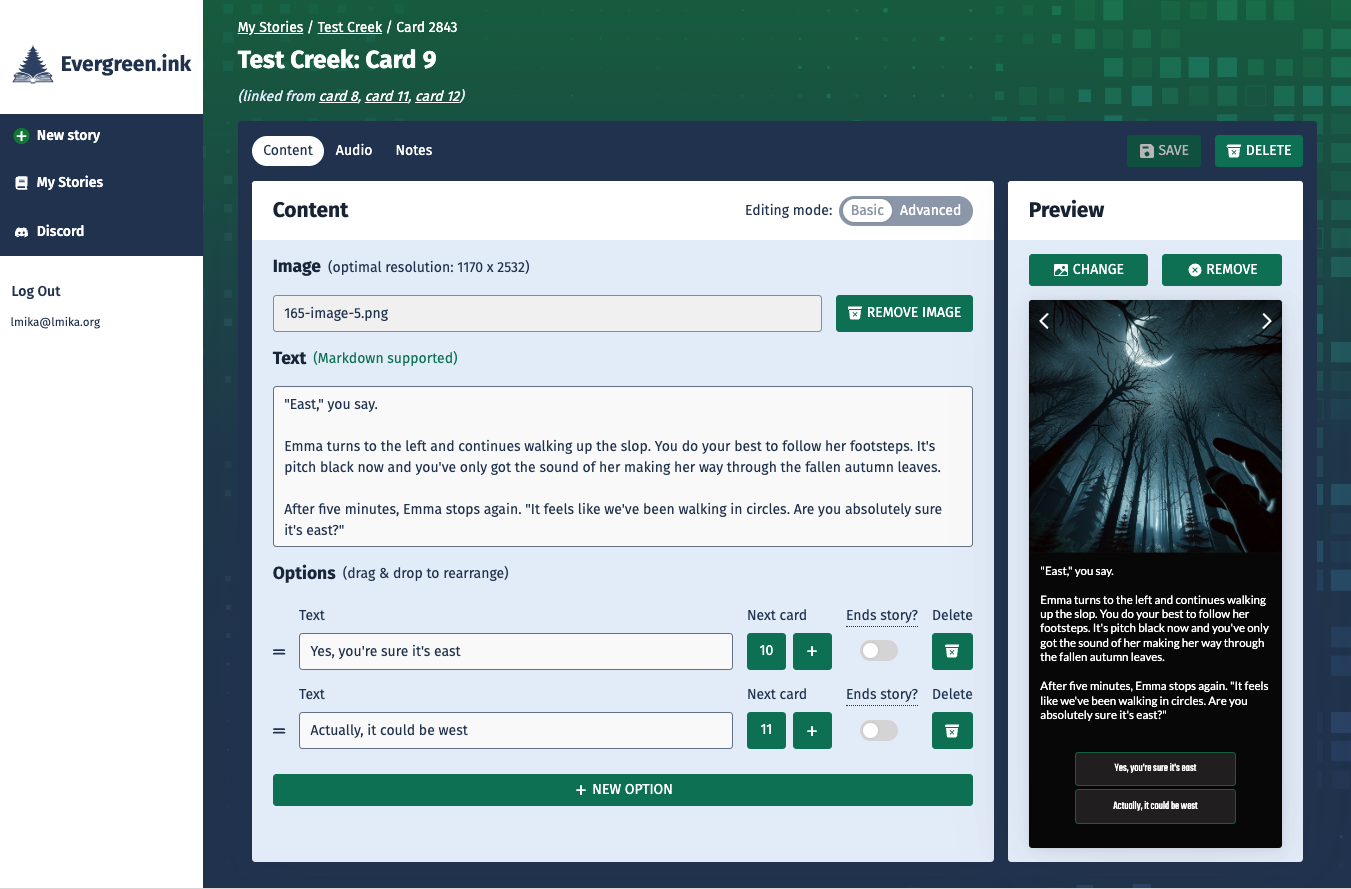
I would recommend not writing too much on a single card. Keep it to maybe two or three paragraphs. Otherwise the text will start to flow over the image, like it does on one of the cards in this story. Evergreen.ink does keep the text legible with a translucent background. But still, it’s just too much text.
Continue reading →
{kind=link}
{kind=link}