Workpad
Indexing In UCL
I’ve been thinking a little about how to support indexing in UCL, as in
getting elements from a list or keyed values from a map. There already
exists an index builtin that does this, but I’m wondering if this can
be, or even should be, supported in the language itself.
I’ve reserved . for this, and it’ll be relatively easy to make use
of it to get map fields. But I do have some concerns with supporting
list element dereferencing using square brackets. The big one being that
if I were to use square brackets the same way that many other languages
do, I suspect (although I haven’t confirmed) that it could lead to the
parser treating them as two separate list literals. This is because the
scanner ignores whitespace, and there’s no other syntactic indicators
to separate arguments to proc calls, like commas:
echo $x[4] --> echo $x [4]
echo [1 2 3][2] --> echo [1 2 3] [2]
So I’m not sure what to do here. I’d like to add support for . for
map fields but it feels strange doing that just that and having nothing
for list elements.
I can think of three ways to address this.
Do Nothing — the first option is easy: don’t add any new syntax to
the language and just rely on the index builtin. TCL does with
lindex, as does Lisp with nth, so I’ll be in good company
here.
Use Only The Dot — the second option is to add support for the dot
and not the square brackets. This is what the Go templating language
does for keys of maps or structs fields. They also have an index
builtin too, which will work with slice elements.
I’d probably do something similar but I may extend it to support index
elements. Getting the value of a field would be what you’d expect, but
to get the element of a list, the construct .(x) can be used:
echo $x.hello \# returns the "hello" field
echo $x.(4) \# returns the forth element of a list
One benefit of this could be that the .(x) construct would itself be a
pipeline, meaning that string and calculated values could be used as
well:
echo $x.("hello")
echo $x.($key)
echo $x.([1 2 3] | len)
echo $x.("hello" | toUpper)
I can probably get away with supporting this without changing the scanner or compromising the language design too much. It would be nice to add support for ditching the dot completely when using the parenthesis, a.la. BASIC, but I’d probably run into the same issues as with the square brackets if I did, so I think that’s out.
Use Parenthesis To Be Explicit — the last option is to use square brackets, and modify the grammar slightly to only allow the use of suffix expansion within parenthesis. That way, if you’d want to pass a list element as an argument, you have to use parenthesis:
echo ($x[4]) \# forth element of $x
echo $x[4] \# $x, along with a list containing "4"
This is what you’d see in more functional languages like Elm and I think Haskell. I’ll have see whether this could work with changes to the scanner and parser if I were to go with this option. I think it may be achievable, although I’m not sure how.
An alternative way might be to go the other way, and modify the grammar rules so that the square brackets would bind closer to the list, which would mean that separate arguments involving square brackets would need to be in parenthesis:
echo $x[4] \# forth element of $x
echo $x ([4]) \# $x, along with a list containing "4"
Or I could modify the scanner to recognise whitespace characters and use that as a guide to determine whether square brackets following a value. At least one space means the square bracket represent a element suffix, and zero mean two separate values.
So that’s where I am at the moment. I guess it all comes down to what works best for the language as whole. I can live with option one but it would be nice to have the syntax. I rather not go with option three as I’d like to keep the parser simple (I rather not add to all the new-line complexities I’ve have already).
Option two would probably be the least compromising to the design as a whole, even if the aesthetics are a bit strange. I can probably get use to them though, and I do like the idea of index elements being pipelines themselves. I may give option two a try, and see how it goes.
Anyway, more on this later.
Tape Playback Site
Thought I’d take a little break from UCL today.
Mum found a collection of old cassette tapes of us when we were kids, making and recording songs and radio shows. I’ve been digitising them over the last few weeks, and today the first recorded cassette was ready to share with the family.
I suppose I could’ve just given them raw MP3 files, but I wanted to record each cassette as two large files — one per side — so as to not loose much of the various crackles and clatters made when the tape recorder was stopped and started. But I did want to catalogue the more interesting points in the recording, and it would’ve been a bit “meh” simply giving them to others as one long list of timestamps (simulating the rewind/fast-forward seeking action would’ve been a step too far).
Plus, simply emailing MP3 files wasn’t nearly as interesting as what I did do, which was to put together a private site where others could browse and play the recorded tapes:
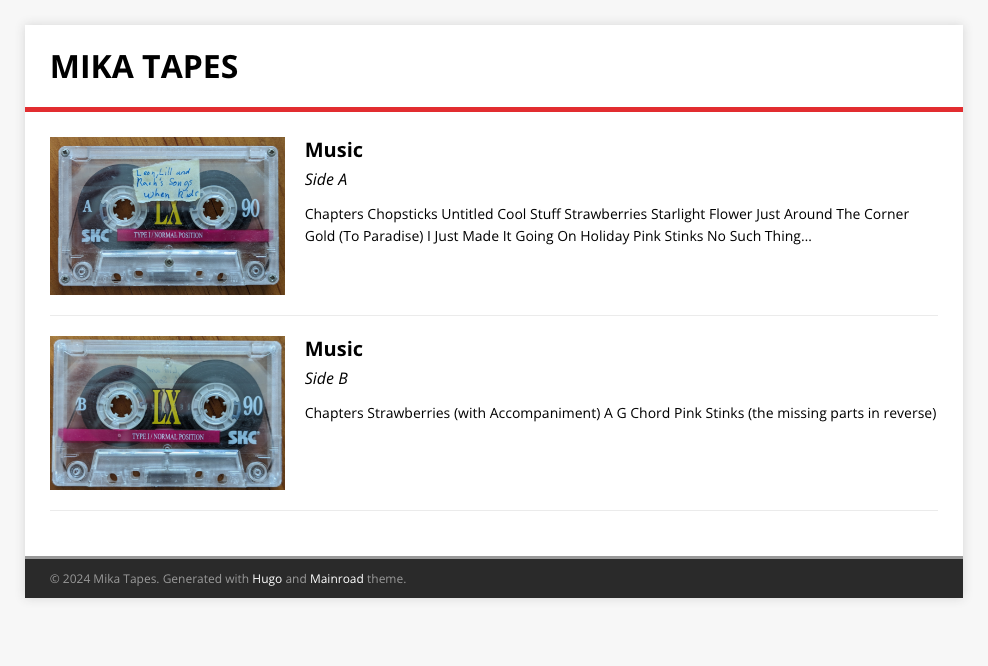
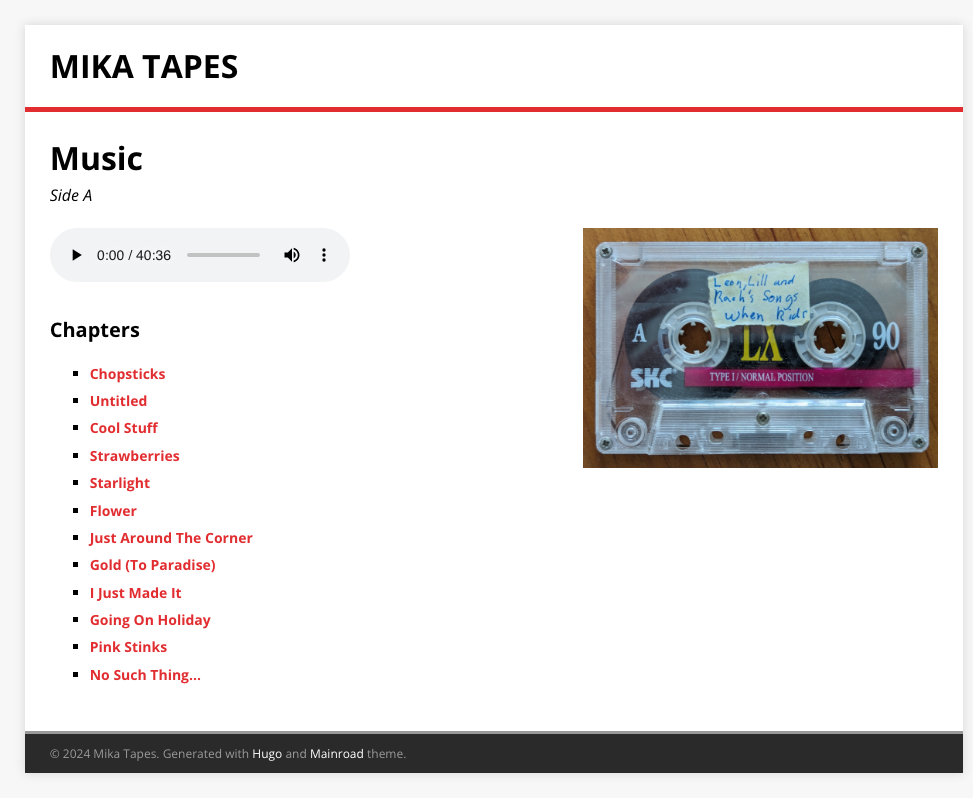
The site is not much to talk about — it’s a Hugo site using the Mainroad theme and deployed to Netlify. There is some JavaScript that moves the playhead when a chapter link is clicked, but the rest is just HTML and CSS. But I did want to talk about how I got the audio files into Netlify. I wanted to use `git lfs` for this and have Netlify fetch them when building the site. Netlify doesn’t do this by default, and I get the sense that Netlify’s support for LFS is somewhat deprecated. Nevertheless, I gave it a try by adding an explicit `git lfs` step in the build to fetch the audio files. And it could’ve been that I was using the LFS command incorrectly, or maybe it was invoked at the wrong time. But whatever the reason, the command errored out and the audio files didn’t get pulled. I tried a few more times, and I probably could’ve got it working if I stuck with it, but all those deprecation warnings in Netlify’s documentation gave me pause.
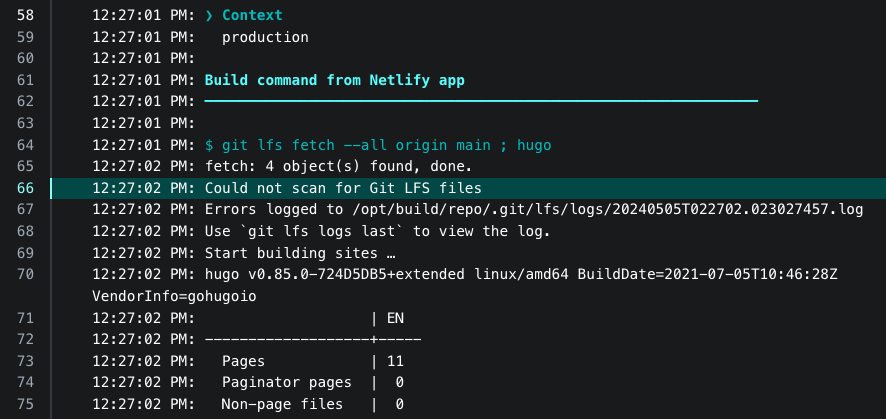
So what I ended up doing was turning off builds in Netlify and using a Github Action which built the Hugo site and publish it to Netlify using the CLI tool. Here’s the Github Action in full:
name: Publish to Netify
on:
push:
branches: [main]
jobs:
build:
name: Build
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
with:
submodules: true
fetch-depth: 0
lfs: true
- name: Setup Hugo
uses: peaceiris/actions-hugo@v3
with:
hugo-version: '0.119.0'
- name: Build Site
run: |
npm install
hugo
- name: Deploy
env:
NETLIFY_SITE_ID: ${{ secrets.NETLIFY_SITE_ID }}
NETLIFY_AUTH_TOKEN: ${{ secrets.NETLIFY_AUTH_TOKEN }}
run: |
netlify deploy --dir=public --prod
This ended up working quite well: the audio files made it to Netlify and were playable on the site. The builds are also quite fast; around 55 seconds (an earlier version involved building Hugo from source, which took 5 minutes). So for anyone else interested in trying to serve LFS files via Netlify, maybe try turning off the builds and going straight to using Github Action and the CLI tool. That is… if you can swallow the price of LFS storage in Github. Oof! A little pricy. Might be that I’ll need to use something else for the audio files.
UCL: Brief Integration Update and Modules
A brief update of where I am with UCL and integrating it into Dynamo-browse. I did managed to get it integrated, and it’s now serving as the interpreter of commands entered in during a session.
It works… okay. I decided to avoid all the complexities I mentioned in
the last post — all that about continuations, etc. — and simply kept the
commands returning tea.Msg values. The original idea was to have the
commands return usable values if they were invoked in a non-interactive
manner. For example, the table command invoked in an interactive
session will bring up the table picker for the user to select the table.
But when invoked as part of a call to another command, maybe it would
return the current table name as a string, or something.
But I decided to ignore all that and simply kept the commands as they are. Maybe I’ll add support for this in a few commands down the line? We’ll see. I guess it depends on whether it’s necessary.
Which brings me up to why this is only working “okay” at the moment.
Some commands return a tea.Msg which ask for some input from the user.
The table command is one; another is set-attr, which prompts the
user to enter an attribute value. These are implemented as a message
which commands the UI to go into an “input mode”, and will invoke a
callback on the message when the input is entered.
This is not an issue for single commands, but it becomes one when you
start entering multiple commands that prompt for input, such as two
set-attr calls:
set-attr this -S ; set-attr that -S
What happens is that two messages to show the prompt are sent, but only one of them is shown to the user, while the other is simply swallowed.
Fixing this would require some re-engineering, either with how the controllers returning these messages work, or the command handlers themselves. I can probably live with this limitation for now — other than this, the UCL integration is working well — but I may need to revisit this down the line.
Modules
As for UCL itself, I’ve started working on the builtins. I’m planning to have a small set of core builtins for the most common stuff, and the rest implemented in the form of “modules”. The idea is that the core will most likely be available all the time, but the modules can be turned on and off by the language embedder based on what they need or are comfortable having.
Each module is namespaces with a prefix, such as os for operating
system operations, or fs for file-system operations. I’ve chosen the
colon as the namespace separator, mainly so I can reserve the dot for
field dereferencing, but also because I think TCL uses the colon as a
namespace separator as well (I think I saw it in some sample code). The
first implementation of this was simply adding the colon to the list of
characters that make up the IDENT token. This broke the parser as the
colon is also use as the map key/value separator, and the parser
couldn’t resolve maps anymore. I had to extend the “indent” parse
rule to support multiple IDENT tokens separated by colons. The module
builtins are simply added to the environment with there fully-qualified
name, complete prefix and colon, and invoking them with one of these
idents will just “flatten” all these colon-separated tokens into a
single string. Not sophisticated, but it’ll work for now.
There aren’t many builtins for these modules at the moment: just a few for reading environment variables and getting files as list of strings. Dynamo-browse is already using this in a feature branch, and it’s allows me to finally add a long-standing feature I’ve been meaning to add for a while: automatically enabling read-only mode when accessing DynamoDB tables in production. With modules, this construct looks a little like the following:
if (eq (os:env "ENV") "prod") {
set-opt ro
}
It would’ve been possible to do this with the scripting language already used by Dynamo-browse. But this is the motivation of integrating UCL: it makes these sorts of constructs much easier to do, almost as one would do writing a shell-script over something in C.
UCL: Breaking And Continuation
I’ve started trying to integrate UCL into a second tool: Dynamo Browse. And so far it’s proving to be a little difficult. The problem is that this will be replacing a dumb string splitter, with command handlers that are currently returning a tea.Msg type that change the UI in some way.
UCL builtin handlers return a interface{} result, or an error
result, so there’s no reason why this wouldn’t work. But tea.Msg is
also an interface{} types, so it will be difficult to tell a UI
message apart from a result that’s usable as data.
This is a Dynamo Browse problem, but it’s still a problem I’ll need to
solve. It might be that I’ll need to return tea.Cmd types — which
are functions returning tea.Msg — and have the UCL caller detect these
and dispatch them when they’re returned. That’s a lot of function
closures, but it might be the only way around this (well, the
alternative is returning an interface type with a method that returns a
tea.Msg, but that’ll mean a lot more types than I currently have).
Anyway, more on this in the future I’m sure.
Break, Continue, Return
As for language features, I realised that I never had anything to exit
early from a loop or proc. So I added break, continue, and return
commands. They’re pretty much what you’d expect, except that break
can optionally return a value, which will be used as the resulting value
of the foreach loop that contains it:
echo (foreach [5 4 3 2 1] { |n|
echo $n
if (eq $n 3) {
break "abort"
}
})
--> 5
--> 4
--> 3
--> abort
These are implemented as error types under the hood. For example,
break will return an errBreak type, which will flow up the chain
until it is handled by the foreach command (continue is also an
errBreak with a flag indicating that it’s a continue). Similarly,
return will return an errReturn type that is handled by the proc
object.
This fits quite naturally with how the scripts are run. All I’m doing
is walking the tree, calling each AST node as a separate function call
and expecting it to return a result or an error. If an error is return,
the function bails, effectively unrolling the stack until the error is
handled or it’s returned as part of the call to Eval(). So leveraging
this stack unroll process already in place makes sense to me.
I’m not sure if this is considered idiomatic Go. I get the impression
that using error types to handle flow control outside of adverse
conditions is frowned upon. This reminds me of all the arguments against
using expressions for flow control in Java. Those arguments are good
ones: following executions between try and catch makes little sense
when the flow can be explained more clearly with an if.
But I’m going to defend my use of errors here. Like most Go projects,
the code is already littered with all the if err != nil { return err }
to exit early when a non-nil error is returned. And since Go developers
preach the idea of errors simply being values, why not use errors here
to unroll the stack? It’s better than the alternatives: such as
detecting a sentinel result type or adding a third return value which
will just be yet another if bla { return res } clause.
Continuations
Now, an idea is brewing for a feature I’m calling “continuations” that might be quite difficult to implement. I’d like to provide a way for a user builtin to take a snapshot of the call stack, and resume execution from that point at a later time.
The reason for this is that I’d like all the asynchronous operations to
be transparent to the UCL user. Consider a UCL script with a sleep
command:
echo "Wait here"
sleep 5
echo "Ok, ready"
sleep could simply be a call to time.Sleep() but say you’re running
this as part of an event loop, and you’d prefer to do something like
setup a timer instead of blocking the thread. You may want to hide this
from the UCL script author, so they don’t need to worry about
callbacks.
Ideally, this can be implemented by the builtin using a construct similar to the following:
func sleep(ctx context.Context, arg ucl.CallArgs) (any, error) {
var secs int
if err := arg.Bind(&secs); err != nil {
return err
}
// Save the execution stack
continuation := args.Continuation()
// Schedule the sleep callback
go func() {
<- time.After(secs * time.Seconds)
// Resume execution later, yielding `secs` as the return value
// of the `sleep` call. This will run the "ok, ready" echo call
continuation(ctx, secs)
})()
// Halt execution now
return nil, ucl.ErrHalt
}
The only trouble is, I’ve got no idea how I’m going to do this. As mentioned above, UCL executes the script by walking the parse tree with normal Go function calls. I don’t want to be in a position to create a snapshot of the Go call stack. That a little too low level for what I want to achieve here.
I suppose I could store the visited nodes in a list when the ErrHalt
is raised; or maybe replace the Go call stack with an in memory stack,
with AST node handlers being pushed and popped as the script runs. But
I’m not sure this will work either. It would require a significant
amount of reengineering, which I’m sure will be technically
interesting, but will take a fair bit of time. And how is this to work
if a continuation is made in a builtin that’s being called from another
builtin? What should happen if I were to run sleep within a map, for
example?
So it might be that I’ll have to use something else here. I could
potentially do something using Goroutines: the script is executed on
Goroutine and args.Continuation() does something like pauses it on a
channel. How that would work with a builtin handler requesting the
continuation not being paused themselves I’m not so sure. Maybe the
handlers could be dispatched on a separate Goroutine as well?
A simpler approach might be to just offload this to the UCL user, and
have them run Eval on a separate Goroutine and simply sleeping the
thread. Callbacks that need input from outside could simply be sent
using channels passed via the context.Context. At least that’ll lean
into Go’s first party support for synchronisation, which is arguably a
good thing.
UCL: The Simplifications Paid Off
The UCL simplifications have been implemented, and they seem to be largely successful.
Ripped out all the streaming types, and changed pipes to simply pass the result of the left command as first argument of the right.
"Hello" | echo ", world"
--> "Hello, world"
This has dramatically improved the use of pipes. Previously, pipes could only be used to connect streams. But now, with pretty much anything flowing through a pipe, that list of commands has extended to pretty much every builtins and user-defined procs. Furthermore, a command no longer needs to know that it’s being used in a pipeline: whatever flows through the pipe is passed transparently via the first argument to the function call. This has made pipes more useful, and usable in more situations.
Macros can still know whether there exist a pipe argument, which can
make for some interesting constructs. Consider this variant of the
foreach macro, which can “hang off” the end of a pipe:
["1" "2" "3"] | foreach { |x| echo $x }
--> 1
--> 2
--> 3
Not sure if this variant is useful, but I think it could be. It seems
like a natural way to iterate items passed through the pipe. I’m
wondering if this could extend to the if macro as well, but that
variant might not be as natural to read.
Another simplification was changing the map builtin to accept
anonymous blocks, as well as an “invokable” commands by name.
Naturally, this also works with pipes too:
[a b c] | map { |x| toUpper $x }
--> [A B C]
[a b c] | map toUpper
--> [A B C]
As for other language features, I finally got around to adding support for integer literals. They look pretty much how you expect:
set n 123
echo $n
--> 123
One side effect of this is that an identifier can no longer start with a dash followed by a digit, as that would be parsed as the start of a negative integer. This probably isn’t a huge deal, but it could affect command switches, which are essentially just identifiers that start with a dash.
Most of the other work done was behind the scenes trying to make UCL easier to embed. I added the notion of “listable” and “hashable” proxies objects, which allow the UCL user to treat a Go slice or a Go struct as a list or hash respectively, without the embedder doing anything other than return them from a function (I’ve yet to add this support to maps just yet).
A lot of the native API is still a huge mess, and I really need to tidy it up before I’d be comfortable opening the source. Given that the language is pretty featureful now to be useful, I’ll probably start working on this next. Plus adding builtins. Really need to start adding useful builtins.
Anyway, more to come on this topic I’m sure.
Oh, one last thing: I’ve put together an online playground where you can try the language out in the browser. It’s basically a WASM build of the language running in a JavaScript terminal emulator. It was a little bit of a rush job and there’s no reason for building this other than it being a fun little thing to do.
You can try it out here, if you’re curious.
Simplifying UCL
I’ve been using UCL for several days now in that work tool I mentioned, and I’m wondering if the technical challenge that comes of making a featureful language is crowding out what I set out to do: making a useful command language that is easy to embed.
So I’m thinking of making some simplifications.
The first is to expand the possible use of pipes. To date, the only thing that can travel through pipes are streams. But many of the commands I’ve been adding simply return slices. This is probably because there’s currently no “stream” type available to the embedder, but even if there was, I’m wondering if it make sense to allow the embedder to pass slices, and other types, through pipes as well.
So, I think I’m going to take a page out of Go’s template book and
simply have pipes act as syntactic sugar over sequential calls. The goal
is to make the construct a | b essentially be the same as b (a),
where the first argument of b will be the result of a.
As for streams, I’m thinking of removing them as a dedicated object type. Embedders could certainly make analogous types if they need to, and the language should support that, but the language will no longer offer first class support for them out of the box.
The second is to remove any sense of “purity” of the builtins. You may
recall the indecision I had regarding using anonymous procs with the
map command:
I’m not sure how I can improve this. I don’t really want to add automatic dereferencing of identities: they’re very useful as unquoted string arguments. I suppose I could add another construct that would support dereferencing, maybe by enclosing the identifier in parenthesis.
I think this is the wrong way to think of this. Again, I’m not here to
design a pure implementation of the language. The language is meant to
be easy to use, first and foremost, in an interactive shell, and if that
means sacrificing purity for a map command that supports blocks,
anonymous procs, and automatic dereferencing of commands just to make it
easier for the user, then I think that’s a trade work taking.
Anyway, that’s the current thinking as of now.
Imports And The New Model
Well, I dragged Photo Bucket out today to work on it a bit.
It’s fallen by the wayside a little, and I’ve been wondering if it’s worth continuing work on it. So many things about it that need to be looked at: the public site looks ugly, as does the admin section; working with more than a single image is a pain; backup and restore needs to be added; etc.
I guess every project goes through this “trough of discontent” where the initial excitement has warn off and all you see is a huge laundry list of things to do. Not to mention the wandering eye looking at the alternatives.
But I do have to stop myself from completely junking it, since it’s actually being used to host the Folio Red Gallery. I guess my push to deploy it has entrapped me (well, that was the idea of pushing it out there in the first place).
Anyway, it’s been a while (last update is here) and the move to the new model is progressing. And it’s occurred to me that I haven’t actually talked about the new model (well, maybe I have but I forgot about it).
Previously, the root model of this data structure is the Store. All
images belong to a Store, which is responsible for managing the
physical storage and retrieval of them. These stores can have
sub-stores, which are usually used to hold the images optimised for a
specific use (serving on the web, showing as a thumbnails, etc).
Separate to this was the public site Design which handed properties of
the public site: how it should look, what the title, and description is,
etc.
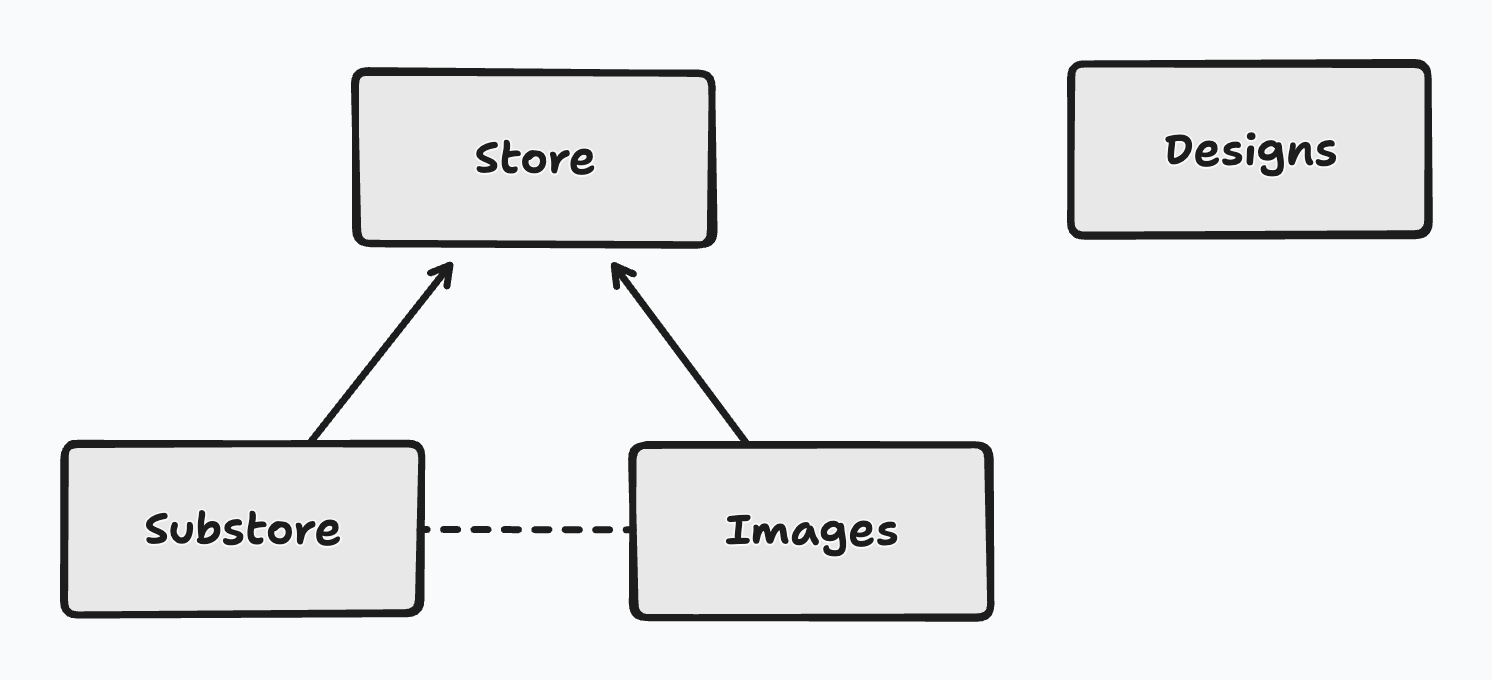
There were some serious issues with this approach: images were owned by stores, and two images can belong to two different stores, but they all belonged to the same site. This made uploading confusing: which store should the image live on? I worked around this by adding the notion of a “primary store” but this was just ignoring the problem and defeated the whole multiple-store approach.
This is made even worse when one considers which store to use for
serving the images. Down the line I was hoping to support virtual domain
hosting, where one could setup different image sites on different
domains that all pointed to the same instance. So imagine how that would
work: one wanted to view images from alpha.example.com and another
wanted to view images from beta.example.com. Should the domains live
on the store? What about the site designs? Where should they live?
The result was that this model could only really ever support one site per Photo Bucket instance, requiring multiple deployments for different sites if one wanted to use a single host for separate photo sites.
So I re-engineered the model to simplify this dramatically. Now, the
route object is the Site:
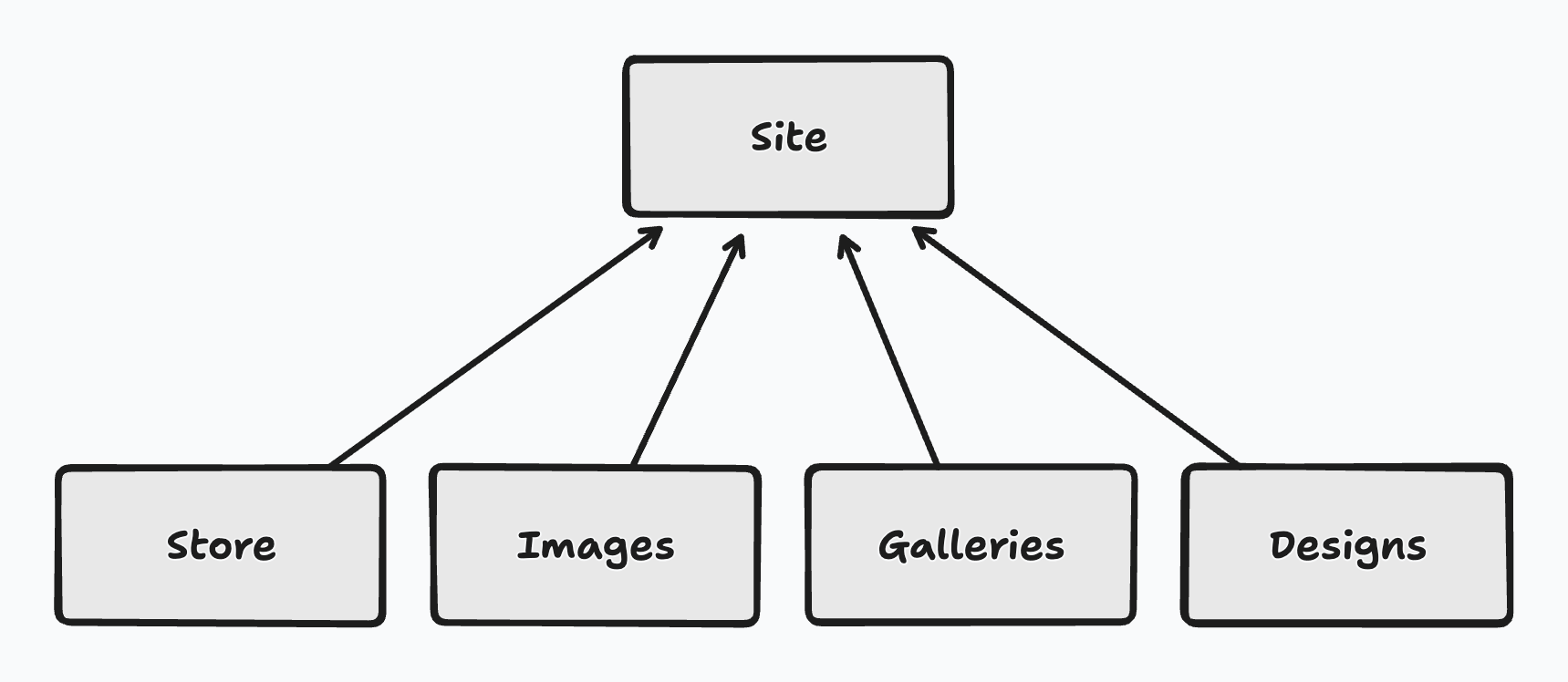
Here, the Site owns everything. The images are associated with sites, not stores. Stores still exist, but their role is now more in-line with what the sub-stores did. When an image is uploaded, it is stored in every Store of the site, and each Store will be responsible for optimising it for a specific use-case. The logic used to determine which Store to use to fetch the image is still in place but now it can be assumed that any Store associated with a site will have the image.
Now the question of which Store an image should be added to is easy: all the them.
Non-image data, such as Galleries and Designs now live off the Site as well, and if virtual hosting is added, so would the domain that serves that Site.
At least one site needs to be present at all time, and it’s likely most instances will simply have a single Site for now. But this assumption solves the upload and hosting resolution issues listed above. And if multiple site support is needed, a simple site picker can be added to the admin page (the public pages can will rely on the request hostname).
This has been added a while ago, and as of today, has been merged to
main. But I didn’t want to deal with writing the data migration logic
for this, so my plan is to simply junk the existing instance and replace
it with the brand new one. But in order to do so, I needed to export the
photos from the old instance, and import them into the new one.
The export logic has been deployed and I’ve made an export it this
morning. Today, the import logic was finished and merged. Nothing
fancy: like the export it’s only invokable from the command line. But
it’ll do the job for now.
Next steps is to actually deploy this, which I guess will be the ultimate test. Then, I’m hoping to add support for galleries in the public page so I can separate images on the Folio Red Gallery into projects. There’s still no way to add images in bulk to a gallery. Maybe this will give me an incentive to do that next.
UCL: Procs and Higher-Order Functions
More on UCL yesterday evening. Biggest change is the introduction of user functions, called “procs” (same name used in TCL):
proc greet {
echo "Hello, world"
}
greet
--> Hello, world
Naturally, like most languages, these can accept arguments, which use
the same block variable binding as the foreach loop:
proc greet { |what|
echo "Hello, " $what
}
greet "moon"
--> Hello, moon
The name is also optional, and if omitted, will actually make the function anonymous. This allows functions to be set as variable values, and also be returned as results from other functions.
proc makeGreeter { |greeting|
proc { |what|
echo $greeting ", " $what
}
}
set helloGreater (makeGreeter "Hello")
call $helloGreater "world"
--> Hello, world
set goodbye (makeGreeter "Goodbye cruel")
call $goodbye "world"
--> Goodbye cruel, world
I’ve added procs as a separate object type. At first glance, this may seem a little unnecessary. After all, aren’t blocks already a specific object type?
Well, yes, that’s true, but there are some differences between a proc and a regular block. The big one being that the proc will have a defined scope. Blocks adapt to the scope to which they’re invoked whereas a proc will close over and include the scope to which it was defined, a lot like closures in other languages.
It’s not a perfect implementation at this stage, since the set
command only sets variables within the immediate scope. This means that
modifying closed over variables is currently not supported:
\# This currently won't work
proc makeSetter {
set bla "Hello, "
proc appendToBla { |x|
set bla (cat $bla $x)
echo $bla
}
}
set er (makeSetter)
call $er "world"
\# should be "Hello, world"
Higher-Order Functions
The next bit of work is finding out how best to invoke these procs in higher-order functions. There are some challenges here that deal with the language grammar.
Invoking a proc by name is fine, but since the grammar required the
first token to be a command name, there was no way to invoke a proc
stored in a variable. I quickly added a new call command — which takes
the proc as the first argument — to work around it, but after a while,
this got a little unwieldy to use (you can see it in the code sample
above).
So I decided to modify the grammar to allow any arbitrary value to be the first token. If it’s a variable that is bound to something “invokable” (i.e. a proc), and there exist at-least one other argument, it will be invoked. So the above can be written as follows:
set helloGreater (makeGreeter "Hello")
$helloGreater "world"
--> Hello, world
At-least one argument is required, otherwise the value will simply be returned. This is so that the value of variables and literal can be returned as is, but that does mean lambdas will simply be dereferenced:
"just, this"
--> just, this
set foo "bar"
$foo
--> bar
set bam (proc { echo "BAM!" })
$bam
--> (proc)
To get around this, I’ve added the notion of the “empty sub”, which
is just the construct (). It evaluates to nil, and since a function
ignores any extra arguments not bound to variables, it allows for
calling a lambda that takes no arguments:
set bam (proc { echo "BAM!" })
$bam ()
--> BAM!
It does allow for other niceties, such as using a falsey value:
if () { echo "True" } else { echo "False" }
--> False
With lambdas now in place, I’m hoping to work on some higher order
functions. I’ve started working on map which accepts both a list or a
stream. It’s a buggy mess at the moment, but some basic constructs
currently work:
map ["a" "b" "c"] (proc { |x| toUpper $x })
--> stream ["A" "B" "C"]
(Oh, by the way, when setting a variable to a stream using set, it
will now collect the items as a list. Or at least that’s the idea.
It’s currently not working at the moment.)
A more refined approach would be to treat commands as lambdas. The grammar supports this, but the evaluator doesn’t. For example, you cannot write the following:
\# won't work
map ["a" "b" "c"] toUpper
This is because makeUpper will be treated as a string, and not a
reference to an invokable command. It will work for variables. You can
do this:
set makeUpper (proc { |x| toUpper $x })
map ["a" "b" "c"] $makeUpper
I’m not sure how I can improve this. I don’t really want to add automatic dereferencing of identities: they’re very useful as unquoted string arguments. I suppose I could add another construct that would support dereferencing, maybe by enclosing the identifier in parenthesis:
\# might work?
map ["a" "b" "c"] (toUpper)
Anyway, more on this in the future I’m sure.
UCL: First Embed, and Optional Arguments
Came up with a name: Universal Control Language: UCL. See, you have TCL; but what if instead of being used for tools, it can be more universal? Sounds so much more… universal, am I right? 😀
Yeah, okay. It’s not a great name. But it’ll do for now.
Anyway, I’ve started integrating this language with the admin tool I’m using at work. This tool I use is the impetus for this whole endeavour. Up until now, this tool was just a standard CLI command usable from the shell. But it’s not uncommon for me to have to invoke the tool multiple times in quick succession, and each time I invoke it, it needs to connect to backend systems, which can take a few seconds. Hence the reason why I’m converting it into a REPL.
Anyway, I added UCL to the tool, along with a readline library, and wow, did it feel good to use. So much better than the simple quote-aware string splitter I’d would’ve used. And just after I added it, I got a flurry of requests from my boss to gather some information, and although the language couldn’t quite handle the task due to missing or unfinished features, I can definitely see the potential there.
I’m trying my best to only use what will eventually be the public API to add the tool-specific bindings. The biggest issue is that these “user bindings” (i.e. the non-builtins) desperately need support for producing and consuming streams. They’re currently producing Go slices, which are being passed around as opaque “proxy objects”, but these can’t be piped into other commands to, say, filter or map. Some other major limitations:
- No commands to actually filter or map. In fact, the whole standard library needs to be built out.
- No ability to get fields from hashes or lists, including proxy objects which can act as lists or hashes.
One last thing that would be nice is the ability to define optional arguments. I actually started work on that last night, seeing that it’s relatively easy to build. I’m opting for a style that looks like the switches you’d find on the command line, with option names starting with dashes:
join "a" "b" -separator "," -reverse
--> b, a
Each option can have zero or more arguments, and boolean options can be represented as just having the switch. This does mean that they’d have to come after the positional arguments, but I think I can live with that. Oh, and no syntactic sugar for single-character options: each option must be separated by whitespace (the grammar actually treats them as identifiers). In fact, I’d like to discourage the use of single-character option names for these: I prefer the clarity that comes from having the name written out in full (that said, I wouldn’t rule out support for aliases). This eliminates the need for double dashes, to distinguish long option names from a cluster of single-character options, so only the single dash will be used.
I’ll talk more about how the Go bindings look later, after I’ve used them a little more and they’re a little more refined.
Tool Command Language: Lists, Hashs, and Loops
A bit more on TCL (yes, yes, I’ve gotta change the name) last night. Added both lists and hashes to the language. These can be created using a literal syntax, which looks pretty much looks how I described it a few days ago:
set list ["a" "b" "c"]
set hash ["a":"1" "b":"2" "c":"3"]
I had a bit of trouble working out the grammar for this, I first went with something that looked a little like the following, where the key of an element is optional but the value is mandatory:
list_or_hash --> "[" "]" \# empty list
| "[" ":" "]" \# empty hash
| "[" elems "]" \# elements
elems --> ((arg ":")? arg)* \# elements of a list or hash
arg --> <anything that can be a command argument>
But I think this confused the parser a little, where it was greedily
consuming the key arg and expecting the : to be present to consume the
value.
So I flipped it around, and now the “value” is the optional part:
elems --> (arg (":" arg)?)*
So far this seems to work. I renamed the two fields “left” and “right”, instead of key and value. Now a list element will use the “left” part, and a hash element will use “left” for the key and “right” for the value.
You can probably guess that the list and hash are sharing the same AST types. This technically means that hybrid lists are supported, at least in the grammar. But I’m making sure that the evaluator throws an error when a hybrid is detected. I prefer to be strict here, as I don’t want to think about how best to support it. Better to just say either a “pure” list, or a “pure” hybrid.
Well, now that we have collections, we need some way to iterate over
them. For that, I’ve added a foreach loop, which looks a bit like the
following:
\# Over lists
foreach ["a" "b" "c"] { |elem|
echo $elem
}
\# Over hashes
foreach ["a":"1" "b":"2"] { |key val|
echo $key " = " $val
}
What I like about this is that, much like the if statement, it’s
implemented as a macro. It takes a value to iterate over, and a block
with bindable variables: one for list elements, or two for hash keys and
values. This does mean that, unlike most other languages, the loop
variable appears within the block, rather than to the left of the
element, but after getting use to this form of block from my Ruby days,
I can get use to it.
One fun thing about hashes is that they’re implemented using Go’s
map type. This means that the iteration order is random, by design.
This does make testing a little difficult (I’ve only got one at the
moment, which features a hash of length one) but I rarely depend on the
order of hash keys so I’m happy to keep it as is.
This loop is only the barest of bones at the moment. It doesn’t support
flow control like break or continue, and it also needs to support
streams (I’m considering a version with just the block that will accept
the stream from a pipe). But I think it’s a reasonably good start.
I also spend some time today integrating this language in the tool I was building it for. I won’t talk about it here, but already it’s showing quite a bit of promise. I think, once the features are fully baked, that this would be a nice command language to keep in my tool-chest. But more of that in a later post.
Backlog Proc: A Better JQL
Backlog Proc is a simple item backlog tracker I built for work. I’d like to link them to Jira tickets, so that I know whether a particular backlog item actually has tasks written for them, and what the status of each of those tasks are. I guess these are meant to be tracked by epics, but Jira’s UI for handling such things is a mess, and I’d like to make notes that are only for my own eyes.
Anyway, I’m was using JQL to select the Jira tickets. And it worked,
but the language is a bit verbose. Plus the tool I’m running the
queries in, jira-cli, requires that I add the project ID along with
the things like the epic or fix version.
So I’m started working on a simpler language, one that’s just a tokenised list of ticket numbers. For example, instead of writing:
project = "ABC" and key in (ABC-123 ABC-234 ABC-345)
One could just write:
ABC-123 ABC-234 ABC-345
And instead of writing:
(project = "ABC" and epicLink = "ABC-818") OR (project = "DEF" and epicLink = "DEF-222")
One could just write:
epic:(ABC-818, DEF-222)
(note here the use of OR, in that the sets are unionised; I’m not sure how this would scale for the other constructs).
Key characteristics is that the parser would be able to get the project ID from the query, instead of having the query writer (i.e. me) explicitly add it.
I can also do introspection, such as get the relevant projects, by “unparsing” the query. An advantage of controlling the parser and language. Can’t do that with JQL.
But, of-course, I can’t cover all possible bases with this language just yet, so I’ll need a way to include arbitrary JQL.. So I’ve also added a general “escape” clause to do this:
jql:"project in (bla)"
A Few Other Things
A few other things that is needed for Backlog Proc:
- The landing screen needs to show all the active items regardless of what project they belong to. Bouncing around projects is a bit of a hassle (to be fair, I haven’t spent any time styling the screens beyond what Buffalo generated).
- Add back ticket drafts. I enjoyed the flow of drafting all the tickets in one hit, then clicking “Publish” and seeing them come out as a fully specified Jira epic.
- Add the notion of logs, with a “log type”. Such types can include things like “todo” (i.e thing for me to work on), “decision” (a product decision that was agreed on), and “log” (work that was done).
- A way to quickly view the tickets in Jira so I can do batch operations over them.
Tool Command Language: Macros And Blocks
More work on the tool command language (of which I need to come up with a name: I can’t use the abbreviation TCL), this time working on getting multi-line statement blocks working. As in:
echo "Here"
echo "There"
I got a little wrapped up about how I can configure the parser to
recognise new-lines as statement separators. I tried this in the past
with a hand rolled lexer and ended up peppering NL tokens all around
the grammar. I was fearing that I needed to do something like this here.
After a bit of experimentation, I think I’ve come up with a way to
recognise new-lines as statement separators without making the grammar
too messy. The unit tests verifying this so far seem to work.
// Excerpt of the grammar showing all the 'NL' token matches.
// These match a new-line, plus any whitespace afterwards.
type astStatements struct {
First *astPipeline `parser:"@@"`
Rest []*astPipeline `parser:"( NL+ @@ )*"`
}
type astBlock struct {
Statements []*astStatements `parser:"LC NL? @@ NL? RC"`
}
type astScript struct {
Statements *astStatements `parser:"NL* @@ NL*"`
}
I’m still using a stateful lexer as it may come in handy when it comes to string interpolation. Not sure if I’ll add this, but I’d like the option.
Another big addition today was macros. These are much like commands, but instead of arguments being evaluated before being passed through to the command, they’re deferred and the command can explicitly request their evaluation whenever. I think Lisp has something similar: this is not that novel.
This was used to implement the if command, which is now working:
set x "true"
if $x {
echo "Is true"
} else {
echo "Is not true"
}
Of course, there are actually no operators yet, so it doesn’t really do much at the moment.
This spurred the need for blocks. which is a third large addition made today. They’re just a group of statements that are wrapped in an object type. They’re “invokable” in that the statements can be executed and produce a result, but they’re also a value that can be passed around. It jells nicely with the macro approach.
Must say that I like the idea of using macros for things like if over
baking it into the language. It can only add to the “embed-ability” of
this, which is what I’m looking for.
Finally, I did see something interesting in the tests. I was trying the following test:
echo "Hello"
echo "World"
And I was expecting a Hello and World to be returned over two lines.
But only World was being returning. Of course! Since echo is
actually producing a stream and not printing anything to stdout, it
would only return World.
I decided to change this. If I want to use echo to display a message,
then the above script should display both Hello and World in some
manner. The downside is that I don’t think I’ll be able to support
constructs like this, where echo provides a source for a pipeline:
\# This can't work anymore
echo "Hello" | toUpper
I mean, I could probably detect whether echo is connected to a pipe
(the parser can give that information). But what about other commands
that output something? Would they need to be treated similarly?
I think it’s probably best to leave this out for now, and have a new construct for providing literals like this to a pipe. Heck, maybe just having the string itself would be enough:
"hello" | toUpper
Anyway, that’s all for today.
Tool Command Language
I have this idea for a tool command language. Something similar to TCL, in that it’s chiefly designed to be used as an embedded scripting language and chiefly in an interactive context.
It’s been an idea I’ve been having in my mind for a while, but I’ve got the perfect use case for it. I’ve got a tool at work I use to do occasional admin tasks. At the moment it’s implemented as a CLI tool, and it works. But the biggest downside is that it needs to form connections to the cluster to call internal service methods, and it always take a few seconds to do so. I’d like to be able to use it to automate certain actions, but this delay would make doing so a real hassle.
Some other properties that I’m thinking off:
- It should be able to support structured data, similar to how Lisp works
- It should be able to support something similar to pipes, similar to how the shell and Go’s template language works.
Some of the trade-offs that come of it:
- It doesn’t have to be fast. In fact, it can be slow so long as the work embedding and operating it can be fast.
- It may not be completely featureful. I’ll go over the features I’m thinking of below, but I say upfront that you’re not going to be building any cloud services with this. Administering cloud servers, maybe; but leave the real programs to a real language.
Some Notes On The Design
The basic concept is the statement. A statement consists of a command, and zero or more arguments. If you’ve used a shell before, then you can imagine how this’ll look:
firstarg "hello, world"
--> hello, world
Each statement produces a result. Here, the theoretical firstarg will
return the first argument it receives, which will be the string "hello, world"
Statements are separated by new-lines or semicolons. In such a sequence, the return value of the last argument is returned:
firstarg "hello" ; firstarg "world"
--> world
I’m hoping to have a similar approach to how Go works, in that semicolons will be needed if multiple statements share a line, but will otherwise be unnecessary. I’m using the Participal parser library for this, and I’ll need to know how I can configure the scanner to do this (or even if using the scanner is the right way to go).
The return value of statements can be used as the arguments of other statements by wrapping them in parenthesis:
echo (firstarg "hello") " world"
--> hello world
This is taken directly from TCL, except that TCL uses the square brackets. I’m reserving the square brackets for data structures, but the parenthesis are free. It also gives it a bit of a Lisp feel.
Pipelines
Another way for commands to consume the output of other commands is to
build pipelines. This is done using the pipe | character:
echo "hello" | toUpper
--> HELLO
Pipeline sources, that is the command on the left-most side, can be either commands that produce a single result, or a command that produces a “stream”. Both are objects, and there’s nothing inherently special about a stream, other than there some handling when used as a pipeline. Streams are also designed to be consumed once.
For example, one can consider a command which can read a file and produce a stream of the contents:
cat "taleOfTwoCities.txt"
--> It was the best of times,
--> it was the worst of times,
--> …
Not every command is “pipe savvy”. For example, piping the result of a
pipeline to echo will discard it:
echo "hello" | toUpper | echo "no me"
--> no me
Of course, this may differ based on how the builtins are implemented.
Variables
Variables are treated much like TCL and shell, in that referencing them is done using the dollar sign:
set name "josh"
--> "Josh"
echo "My name is " $name
--> "My name is Josh"
Not sure how streams will be handled with variables but I’m wondering if they should be condensed down to a list. I don’t like the idea of assigning a stream to a variable, as streams are only consumed once, and I feel like some confusion will come of it if I were to allow this.
Maybe I can take the Perl approach and use a different variable
“context”, where you have a variable with a @ prefix which will
reference a stream.
set file (cat "eg.text")
echo @file
\# Echo will consume file as a stream
echo $file
\# Echo will consume file as a list
The difference is subtle but may be useful. I’ll look out for instances where this would be used.
Attempting to reference an unset variable will result in an error. This may also change.
Other Ideas
That’s pretty much what I have at the moment. I do have some other ideas, which I’ll document below.
Structured Data Support: Think lists and hashes. This language is to be used with structured data, so I think it’s important that the language supports this natively. This is unlike TCL which principally works with strings and the notion of lists feels a bit tacked on to some extent.
Both lists and hashes are created using square brackets:
\# Lists. Not sure if they'll have commas or not
set l [1 2 3 $four (echo "5")]
\# Maps
set m [a:1 "b":2 "see":(echo "3") (echo "dee"):$four]
Blocks: Yep, containers for a groups of statements. This will be used for control flow, as well as for definition of functions:
set x 4
if (eq $x 4) {
echo "X == 4"
} else {
echo "X != 4"
}
foreach [1 2 3] { |x|
echo $x
}
Here the blocks are just another object type, like strings and stream,
and both if and foreach are regular commands which will accept a
block as an argument. In fact, it would be theoretically possible to
write an if statement this way (not sure if I’ll allow setting
variables to blocks):
set thenPart {
echo "X == 4"
}
if (eq $x 4) $thenPart
The block execution will exist in a context, which will control whether
a new stack frame will be used. Here the if statement will simply use
the existing frame, but a block used in a new function can push a new
frame, with a new set of variables:
proc myMethod { |x|
echo $x
}
myMethod "Hello"
--> "Hello
Also note the use of |x| at the start of the block. This is used to
declare bindable variables, such as function arguments or for loop
variables. This will be defined as part of the grammar, and be a
property of the block.
Anyway, that’s the current idea.
Photo Bucket Update: Exporting To Zip
Worked a little more on Photo Bucket this week. Added the ability to export the contents of an instance to a Zip file. This consist of both images and metadata.
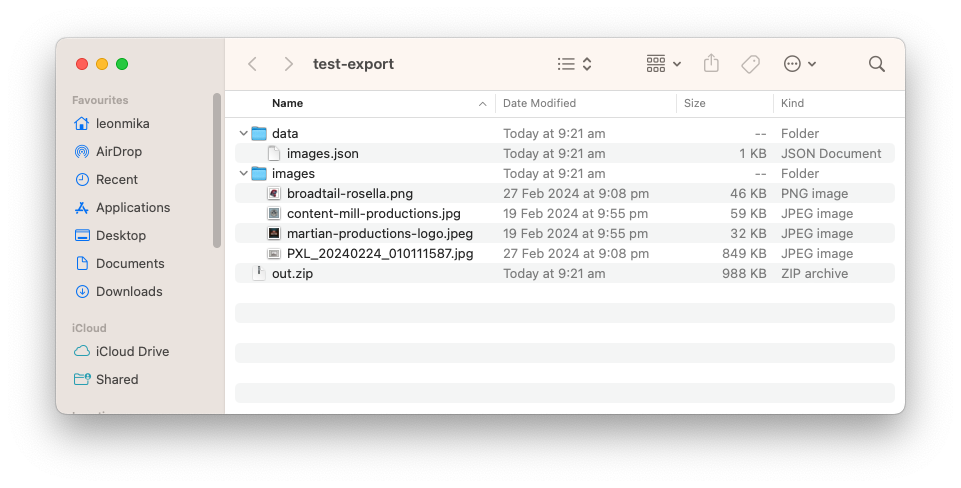
I’ve went with lines of JSON file for the image metadata. I considered a CSV file briefly, but for optional fields like captions and custom properties, I didn’t like the idea of a lot of empty columns. Better to go with a format that’s a little more flexible, even if it does mean more text per line.
As for the images, I’m hoping the export to consist of the “best quality” version. What that means will depend on the instance. The idea is to have three tiers of image quality managed by the store: “original”, “web”, and “thumbnail”. The “original” version is the untouched version uploaded to the store. The “web” version is re-encoded from the “original” and will be slightly compressed with image metadata tags stripped out. The “thumbnail” version will be a small, highly compressed version suitable for the thumbnail. There is to be a decision algorithm in place to get an image given the desired quality level. For example, if something needed the “best quality” version of an image, and the “original” image is not available, the service will default to the “web” version (the idea is that some of these tiers will be optional depending on the need of the instances).
This is all partially working at the moment, and I’m hoping to rework all this when I replace how stores and images relate to each other (This is what I’m starting on now, and why I built export now since this will be backwards incompatible). So for the moment the export simply consists of the “web” version.
I’ve got unit tests working for this as well. I’m trying a new approach for unit testing in this project. Instead of using mocks, the tests are actually running against a fully instantiated versions of the services. There exists a servicestest package which does all the setup (using temporary directories, etc) and tear down of these services. Each individual unit test gets the services from this package and will run tests against a particular one.
This does mean all the services are available and exercised within the tests, making them less like unit tests and more like integrations tests. But I think I prefer this approach. The fact that the dependent services are covered gives me greater confidence that they’re working. It also means I can move things around without changing mocks or touching the tests.
That’s not to say that I’m not trying to keep each service their own component as much as I can. I’m still trying to follow best practice of component design: passing dependencies in explicitly when the services are created, for example. But setting them all up as a whole in the tests means I can exercise them while they serve the component being tested. And the dependencies are explicit anyway (i.e. no interfaces) so it makes sense keeping it that way for the tests as well. And it’s just easier anyway. 🤷
Anyway, starting rework on images and stores now. Will talk more about this once it’s done.
Photo Bucket Update: More On Galleries
Spent a bit more time working on Photo Bucket this last week1, particularly around galleries. They’re progressing quite well. I’m made some strides in getting two big parts of the UI working now: adding and removing images to galleries, and re-ordering gallery items via drag and drop.
I’ll talk about re-ordering first. This was when I had to bite the bullet and start coding up some JavaScript. Usually I’d turn to Stimulus for this but I wanted to give HTML web components a try. And so far, they’ve been working quite well.
The gallery page is generated server-side into the following HTML:
<main>
<pb-draggable-imageset href="/_admin/galleries/1/items" class="image-grid">
<pb-draggable-image position="0" item-id="7">
<a href="/_admin/photos/3">
<img src="/_admin/img/web/3">
</a>
</pb-draggable-image>
<pb-draggable-image position="1" item-id="4">
<a href="/_admin/photos/4">
<img src="/_admin/img/web/4">
</a>
</pb-draggable-image>
<pb-draggable-image position="2" item-id="8">
<a href="/_admin/photos/1">
<img src="/_admin/img/web/1">
</a>
</pb-draggable-image>
</pb-draggable-imageset>
</main>
Each <pb-draggable-image> node is a direct child of an <pb-draggable-imageset>. The idea is that the user can rearrange any of the <pb-draggable-image> elements within a single <pb-draggable-imageset> amongst themselves. Once the user has moved an image onto to another one, the image will signal its new position by firing a custom event. The containing <pb-draggable-imageset> element is listening to this event and will respond by actually repositioning the child element and sending a JSON message to the backend to perform the move in the database.
A lot of this was based on the MDN documentation for drag and drop and it follows the examples quite closely. I did find a few interesting things though. My first attempt at this was to put it onto the <pb-draggable-image> element, but I wasn’t able to get any drop events when I did. Moving the draggable attribute onto the <a> element seemed to work. I not quite sure why this is. Surely I can’t think of any reason as to why it wouldn’t work. It may had something else, such as how I was initialising the HTTP components.
Speaking of HTML components, there was a time where the custom component’s connectedCallback method was being called before the child <a> elements were present in the DOM. This was because I had the <script> tag in the the HTML head and configured to be evaluated during parsing. Moving it to the end of the body and loading it as a module fixed that issue. Also I found that moving elements around using element.before and element.after would actually call connectedCallback and disconnectedCallback each time, meaning that any event listeners registered within connectedCallback would need to be de-registered, otherwise events would be handled multiple times. This book-keeping was slightly annoying, but it worked.
Finally, there was moving the items with the database. I’m not sure how best to handle this, but I have that method that seems to work. What I’m doing is tracking the position of each “gallery item” using a position field. This field would be 1 for the first item, 2 for the next, and so on for each item in the gallery. The result of fetching items would just order using this field, so as long as they’re distinct, they don’t need to be a sequence incrementing by 1, but I wanted to keep this as much as possible.
The actual move involves two update queries. The first one will update the positions of all the items that are to shift left or right by one to “fill the gap”. The way it does this is that when an item is moved from position X to position Y, the value of position between X and Y would be changed by +1 if X > Y, or by –1 if Y > X. This is effectively the same as setting position X to X + 1, and so on, but done using one UPDATE statement. The second query just sets the position of item X to Y.
So that’s moving gallery items. I’m not sure how confident I am with this approach, but I’ve been testing this, both manually and by writing unit tests. It’s not quite perfect yet: I’m still finding bugs (I found some while coming up with these screencasts). Hopefully, I’ll be able to get to the bottom of them soon.
The second bit of work was to actually add and remove images in the gallery themselves. This, for the moment, is done using a “gallery picker” which is available in the image details. Clicking “Gallery” while viewing an image will show the list of galleries in the system, with toggles on the left. The galleries an image already belongs to is enabled, and the user can choose the galleries they want the image to be in by switching the toggles on and off. These translate to inserts and remove statements behind the scenes.
The toggles are essentially just HTML and CSS, and a bulk of the code was taken from this example, with some tweaks. They look good, but I think I may need to make them slightly smaller for mouse and keyboard.
I do see some downside with this interaction. First, it reverses the traditional idea of adding images to a gallery: instead of doing that, your selecting galleries for an image. I’m not sure if this would be confusing for others (it is modelled on how Google Photos works). Plus, there’s no real way to add images in bulk. Might be that I’ll need to add a way to select images from the “Photos” section and have a dialog like this to add or remove them all from a gallery. I think this would go far in solving both of these issues.
So that’s where things are. Not sure what I’ll work on next, but it may actually be import and export, and the only reason for this is that I screwed up the base model and will need to make some breaking changes to the DB schema. And I want to have a version of export that’s compatible with the original schema that I can deploy to the one and only production instance of Photo Bucket so that I can port the images and captions over to the new schema. More on this in the future, I’m sure.
-
Apparently I’m more than happy to discuss work in progress, yet when it comes to talking about something I’ve finished, I freeze up. 🤷 ↩︎
Photo Bucket Galleries and Using the HTML Popover API
Spent a bit more on Photo Bucket this evening. Tonight I started working on galleries, which’ll work more or less like albums.
At the moment you can create a gallery and add a photo to it. Most of the work so far has been backend so the UI is pretty rough. Eventually you’ll be able to do things like rearrange photos within galleries, but for the moment they’ll just be added to the end.
I did need to add some modals to the UI, such as the New Gallery model that’s shown for the gallery name. This gave me the opportunity to try out the new popover API. And yeah, it does exactly what it says on the tin: add the popover attribute to an element and it becomes a working popover (at least in the latest version of Vivaldi). Must say it’s impressive that this is now possible with HTML alone.
The initial version of the modals used a <div> for the popover target. And while that worked, there were some small annoyances. First was that the form within the popover didn’t get focus when the popover was displayed. It would be nice to click “New” and start typing out the gallery name. But this is a small thing that’s easily solvable with JavaScript, so it’s no big deal.
The second, slightly larger one, was that dismissing the popover by clicking outside of it will not eat the input. If you were to click a sidebar link while the New Gallery model is opened, you’ll end up on that newly selected page. I’m not a fan of this. Dismissing the popover feels like its own user gesture, and I fear the user accidentally activating things when all they’re trying to do is dismiss the popover (it’s not in place now, but I am planning to dim the background when the Create Gallery modal is visible).
Fortunately, there’s a simple solution to this. It turns out that replacing the <div> element with a <dialog> element would solves both problems. It works seamlessly with the new popover attributes, yet showing the dialog will give focus to the form, and will eat the click when the user dismisses it.
Perfect. Looks like I’ve delayed the need for JavaScript a little longer (it will come eventually; it always will).
Spent some time this evening working on my image hosting tool. It’s slowly coming along, but wow do I suck at UI design (the “Edit Photo” screen needs some rebalancing).
Working on one of the admin sections of the project I was alluding to yesterday. Here’s a screencast of how it’s looking so far.
The styling and layout is not quite final. I’m focusing more on functionality, and getting layout and whitespace looking good always takes time. But compared to how it looked before I started working on it this morning, I think it’s a good start.
In the end it took significantly more time to write about it then to actually do it, but the dot product approach seems to work.
So I guess today’s beginning with a game of “guess the secret password requirements.” 😒