
-
Dear AWS,
Deprecate functions in your SDK if you must, but please post a link to the method I should use in its stead. Or tell me it’s no longer supported. Otherwise, I have no recourse but to either search mountains of documentation, or take my chances with what is deprecated.
Sincerely,
lmika
-
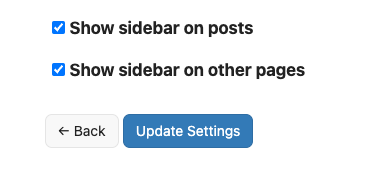
Released version 1.2.0 of Sidebar for Tiny Theme. In this version, the sidebar can now be configured to appear on pages other than just the home page. Options include showing it on the pages of posts, or pages other than posts. With both on, the sidebar will now appear on all pages of the site.
 screenshots
screenshots -
Successfully moved my PeerTube instance over to Hetzner and Coolify, allowing me to shutdown the Linode instance I was using. Net cost savings to me is $0.00, but I’m hoping to use the new Hetzner server for more than just PeerTube.
-
2024 Song of The Year
It’s Christmas Eve once again, which means it’s time for the Song of The Year for 2024. Looking at the new and rediscovered albums for the year, there are quite a few to choose from.
The runners up are pretty much all from Lee Resevere, a new artist I’ve started listening to, and includes:
- Should I Run, by Kristen Martell, arranged by Lee Rosevere
- Miles Wide, from Synths Working Overtime, by Lee Rosevere
- We’ve Been Here Before and Hide Your Heart, from Stationary Loops, by Lee Rosevere
But there can only be one winner, and this year it’s Oxygene, Pt. 20 by Jean-Michel Jarre. 👏
Continue reading → -
That’s it! I’m never going to use a framework that uses Webpack or installs more than 5 Node dev dependencies. Why? Because every time I check it out to work on it, all these dependencies break, and I’m left to spend hours updating them.
Never again! 😡
videos -
🔗 Lens
A nice looking meta tag checker by Robb Knight. Finding a good meta tag checker that’s not riddled with ads is difficult. This might be the one I’ll use going forward. I also liked his blog post on how he built it.
links -
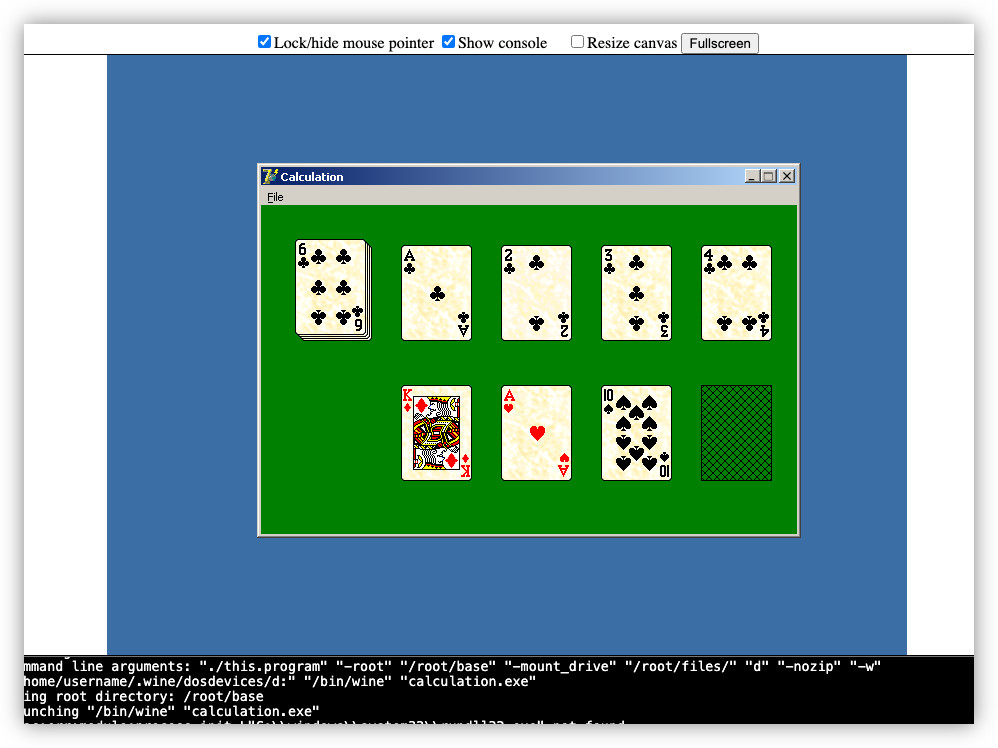
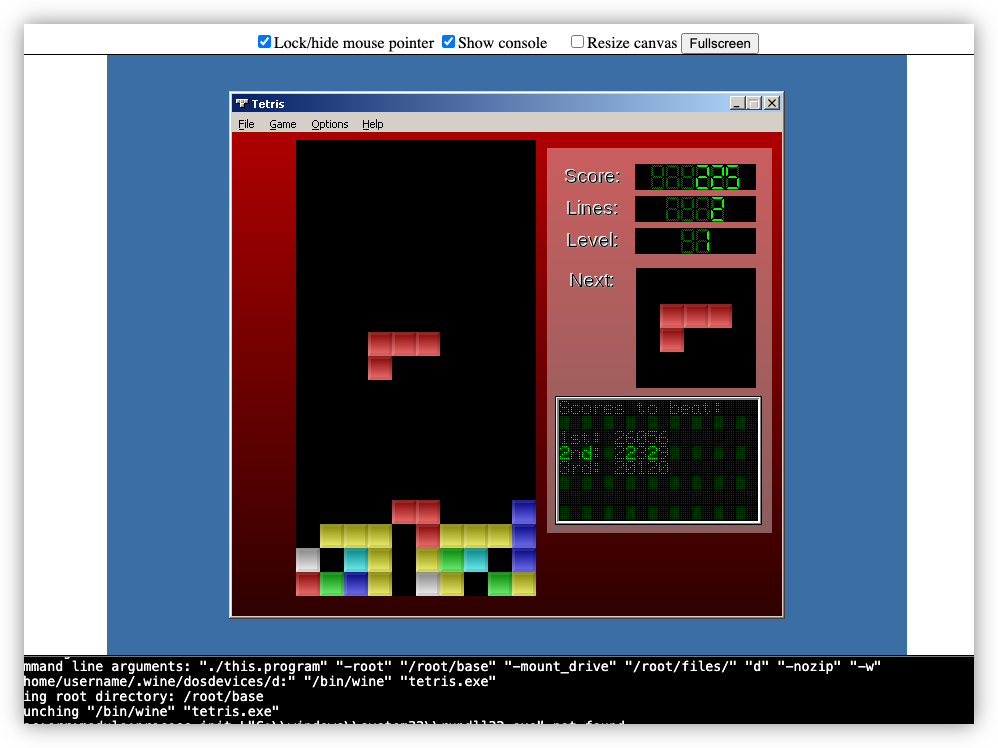
Thought I’d have another go at looking at BoxedWine for making an online archive of my old Delphi projects. They’ve been some significant improvements since the last time I looked at it. They don’t run fast, but that’s fine. As long as they run.
 screenshots old-projects
screenshots old-projects -
It’s a shame that there’s no MacOS release for Alan Wake. I tried playing the Windows version in Crossover yesterday on my M2 Mac Mini, and even with all the graphic settings set to their lowest, I was getting frame rates in the single digits.
-
I wonder if we could convince Ben to order another run of Stratechery mugs shaped like the one he drinks from. I really like my Stratechery mug — it's one I often use — yet the mug he describes here is intriguing.
videos -
One of these days, when I see a car idling while the owner is outside picking up coffee, I’m going to walk over there and turn it off. Or steal it, depending on how annoyed I am. 😏
-
That Which Didn't Make The Cut
I did a bit of a clean-up of my projects folder yesterday, clearing out all the ideas that never made it off the ground. I’d figured it’d be good to write a few words about each one before erasing them from my hard drive for good.
I suppose the healthiest thing to do would be to just let them go. But what can I say? Should a time come in the future where I wish to revisit them, it’d be better to have something written down than not. It wouldn’t be the first time I wished this was so.
Continue reading → -
I’m happy that Ludo Studio managed to secure a deal for a feature-length Bluey film, plus attractions in Disney parks. But it’s just another example of how the ABC cannot keep nice things. It happened to Kath and Kim too.
Maybe it’s enough that it’s role is more of a launch pad for good media.
-
Oof! Almost deleted my Obsidian notes while cleaning out my work laptop. Fortunately it was a simple move to recover. Ended the year with 581 notes, totalling 8.7 MB. Most of these are Daily Notes, of which 214 were created this year. Thus ends the second full year of using Obsidian for work.
-
Counting down the hours now. 3 to go…
-
Writing documentation for tools that others will need to run over the Christmas break. I remain convinced that documentation is a great way to spot the usability flaws in the tools I write. The question then turns into one of priorities: should I fix the tool, or just explain the flaws in the docs?
-
I’m not a fan of the changes Google made to their Weather app. It assumes you’re interested in saving every location you search for as a favourite, which is not how I use search. And horizontal scrolling for the 10 day forecast? With no date?
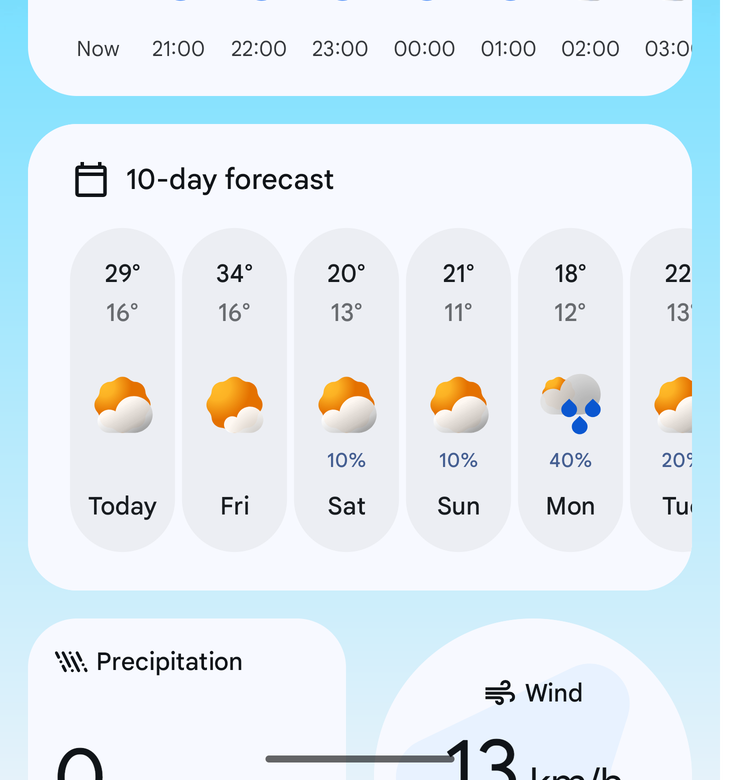
No, sorry. This is a step backwards in design.
screenshots -
Spending the last few days of the year feeding the dragon. My instructions are clear: I must feed the dragon. The dragon must be fed. At no point should I allow the dragon to go hungry.
(“Dragon” here refers to the system I’m running migrations on, a.la. this Rec Diffs episode)
-
Lot of interesting thing scheduled for Go 1.24, but this one looks particularly exciting:
The new Text function can be used to generate cryptographically secure random text strings.
You’d be surprised how often I need to generate random strings. Doing so, without installing a third-party package, is always a bit involved; either generating a UUID and stripping the dashes, or doing a Base64 on a random byte slice. To be given a function to do this from the standard library will be most welcome.
-
If there’s one thing I learnt from all the database querying I’ve been doing today, it’s that all the parallelism in the world doesn’t come close to performing as well as just being physically close to the data.




