
-
Implicit Imports To Load Go Database Drivers Considered Annoying (By Me)
I wish Go’s approach to loading database drivers didn’t involve implicitly importing them as packages. At least that way, package authors would be more likely to get the driver from the caller, rather than load a driver themselves.
I’ve been bitten by this recently, twice. I’m using a GitHub Linux driver to build an ARM version of something that needs to use SQLite. As far as I can tell, it’s not possible to build an ARM binary with CGO enabled with these runners (at-least, not without installing a bunch of dependencies — I’m not that desperate yet).
Continue reading → -
Rubber-ducking: On Context
I’m torn between extracting auth credentials in the handler from a Go Context and passing them as arguments to service methods, or just passing the context and having the service methods get it from the Context themselves.
Previously, when the auth credentials just had a user ID, we were doing the former. But we’re now using more information about what the user has access to and if we were to continue doing this, we’ll need to pass more parameters through to the service layer. Not only does this make things a little less neater, it’ll mean the next time we do this, we’ll have to do the whole thing again.
Continue reading → -
Rubberducking: On Context
I’m torn between extracting auth credentials in the handler from a Go Context and passing them as arguments to service methods, or just passing the context and having the service methods get it from the Context themselves.
Previously, when the auth credentials just had a user ID, we were doing the former. But we’re now using more information about what the user has access to and if we were to continue doing this, we’ll need to pass more parameters through to the service layer. Not only does this make things a little less neater, it’ll mean the next time we do this, we’ll have to do the whole thing again.
Continue reading → -
Goland Debugger Not Working? Try Upgrading All The Things
I’ve been having occasional trouble with the debugger in Goland. Every attempt to debug a test would just fail with the following error:
/usr/local/go/bin/go tool test2json -t /Applications/GoLand.app/… API server listening at: 127.0.0.1:60732 could not launch process: EOF Debugger finished with the exit code 1My previous attempts at fixing this — upgrading Go and Goland — did get it working for a while, but recently it’s been happening to me again. And being at the most recent version of Go and Goland, that avenue was not available to me.
Continue reading → -
People Are More Interested In What You're Working On Than You Think

If anyone else is weary about posting about what projects they’re working on, fearing that others would think they’re showing off or something, here’s two bits of evidence that I hope would allay these fears:
Exhibit 1: I’m a bit of a fan of the GMTK YouTube channel. Lots of good videos there about game development that, despite not being a game developer myself, I find facinating. But the playlist I enjoy the most is the one where Mark Brown, the series creator, actually goes through the process of building a game himself. Now, you’re not going to learn how to use Unity from that series (although he does have a video about that), but it’s fun seeing him making design decisions, showing off prototypes, overcoming challenges — both external and self imposed, and seeing it all come together. I’m aways excited when he drops one of these videos, and when I learnt today that he’s been posting dev logs on his Discord, so interested am I in this topic that I immediately signed up as a Patreon supporter.
Continue reading → -
Github Actions, Default Token Permissions, And Publishing Binaries
Looks like Github’s locked down the access rights of the
GITHUB_TOKENrecently. This is the token that’s available to all Github actions by default.After taking a GoReleaser config file from an old project and using it in a new one, I encountered this error when GoReleaser tried to publish the binaries as part of a Github Release:
failed to publish artifacts: could not release: PATCH https://api.github.com/repos/lmika/<project>/releases/139475588: 403 Resource not accessible by integration []After a quick search, I found this Github issue which seemed to cover the same problem. It looks like the way to resolve this is to explicitly add the
Continue reading →content: writepermission to the Github Actions YAML file: -
Thoughts on The Failure of Microsoft Bob
Watching a YouTube video about Microsoft Bob left me wondering if one of the reasons why Bob failed was that it assumed that users, who may have been intimidated by a GUI when they first encountered one, would be intimidated for ever. That their level of skill will always remain one in which the GUI was scary and unusable, and their only success in using a computer is through applications like Bob.
Continue reading → -
Build Indicators
AKA: Das Blinkenlights
Date: 2017 — now
Status: Steady Green
I sometimes envy those that work in hardware. To be able to build something that one can hold and touch. It’s something you really cannot do with software. And yeah, I dabbled a little with Arduino, setting up sketches that would run on prebuilt shields, but I never went beyond the point of building something that, however trivial or crappy, I could call my own.
Continue reading → -
Why I Use a Mac
Why do I use a Mac?
Because I can’t get anything I need to get done on an iPad.
Because I can’t type to save myself on a phone screen.
Because music software doesn’t exist on Linux.
Because the Bash shell doesn’t exist on Windows (well, it didn’t when I stopped using it).
That’s why I use a Mac.
Continue reading → -
Broadtail
Date: 2021 – 2022
Status: Paused
First project I’ll talk about is Broadtail. I think I talked about this one before, or at least I posted screenshot of it. I started work on this in 2021. The pandemic was still raging, and much of my downtime was watching YouTube videos. We were coming up to a federal election, and I was getting frustrated with seeing YouTube ads from political parties that offend me. This was before YouTube Premium so there was no real way to avoid these ads. Or was there?
Continue reading → -
The AWS Generative AI Workshop
Had an AI workshop today, where we went through some of the generative AI services AWS offers and how they could be used. It was reasonably high level yet I still got something out of it.
What was striking was just how much of integrating these foundational models (something like an LLM that was pre-trained on the web) involved natural language. Like if you building a chat bot to have a certain personality, you’d start each context with something like:
Continue reading → -
Replacing Ear Cups On JBL E45BT Headphones
As far as wearables go, my daily drivers are a pair of JBL E45BT Bluetooth headphones. They’re several years old now and are showing their age: many of the buttons no longer work and it usually takes two attempts for the Bluetooth to connect. But the biggest issue is that the ear cups were no longer staying on. They’re fine when I wear them, but as soon as I take them off, the left cup would fall to the ground.
Continue reading → -
Detecting A Point In a Convex Polygon
Note: there are some interactive elements and MathML in this post. So for those reading this in RSS, if it looks like some formulas or images are missing, please click through to the post.
For reasons that may or may not be made clear lately, I’ve been working on something involving bestagons. I tended to shy away from things like this before, mainly because of the maths involved in tasks like determining whether a point is within a hexagon. But instead of running away once again from things more complex than a grid, I figured it was time to learn this once and for all. So off I went.
Continue reading → -
Can a Single Line Or Even a Single Word Be Considered a Legitimate Blog Post?
-
2023 Year In Review
Well, once more around the sun and it’s time again to look back on the year that was.
Career
Reflecting on the work we did this past year, there were a few highlights. We managed to get a few major things released, like the new billing and resource usage tracking system (not super exciting, but it was still fun to work on). And although the crunch period we had was a little hard — not to mention the 3 AM launch time — it was good to see it delivered on time. We’re halfway through another large change that I hope to get out before the end of summer, so it’ll probably be full steam ahead when I go back to work this week.
Continue reading → -
Day One Waffling
Thinking about my journalling in Day One recently and I’m wondering if it’s time to move it off to something else, maybe Markdown files in a Git repository. Still mulling it over but every time I weigh the two options in my mind, the simpler Markdown approach always wins out.
Plain old Markdown files are just way more versatile and portable than what Day One offers. I can put them in a private Hugo (or Eleventy) site and browse them in a web browser, with the backing of a full HTML renderer that offers, amongst other things, figures with captions (yes, I want them that badly). Making them into a book will be more involved than what Day One offers, but I’ve been a little unhappy with how books from Day One are laid out anyway. Doing it from Markdown files will be pricier and more involved, but at least I’ll have a bit more control over how it looks.1
Continue reading → -
First Impressions of Eleventy
I tend to use Hugo whenever I need a static site. But my magpie tendencies have driven me to take a look at Eleventy, and I can definitely see the appeal.
Going through the Eleventy quick-start guide, I’m quite impressed with how easy it was to setup a bespoke layout for a single site. I’ve done similar things in a few Hugo sites and while I wouldn’t describe it as “hard”, it’s certainly more involved. Hugo’s decent, but it feels quite… engineered. That’s not necessarily a bad thing: putting together something using one of the pre-built themes is quite straightforward. But going beyond a few theme customisations involves a fair bit of work compare to Eleventy.
Continue reading → -
2023 Song of The Year
Well, believe it or not, my standing Christmas Eve Mass organ gig has come around once more1, so it’s time to decide on this year’s Song of The Year. This is the second post in this series, so please see last year’s post on what this nonsense is all about.
This year’s nominees are (not too many this year):
- Wooden Ship, from Antarctica — Suit for guitar and orchestra by Nigel Westlake.
- Penguin Ballet, from Antarctica — Suit for guitar and orchestra by Nigel Westlake. Not really a new track for me, but I’m including it here anyway as it’s been many years since I last heard it2.
And the winner is: Wooden Ship by Nigel Westlake 👏
Continue reading → -
Test Creek: A Test Story With Evergreen.ink
Had a play with Evergreen.ink this afternoon. It was pretty fun. Made myself a test story called Test Creek which you can try out (the story was written by me but all the images were done using DALL-E).
The experience was quite intuitive. I’ve yet to try out the advanced features, like the Sapling scripting engine, but the basics are really approachable for anyone not interested with any of that.
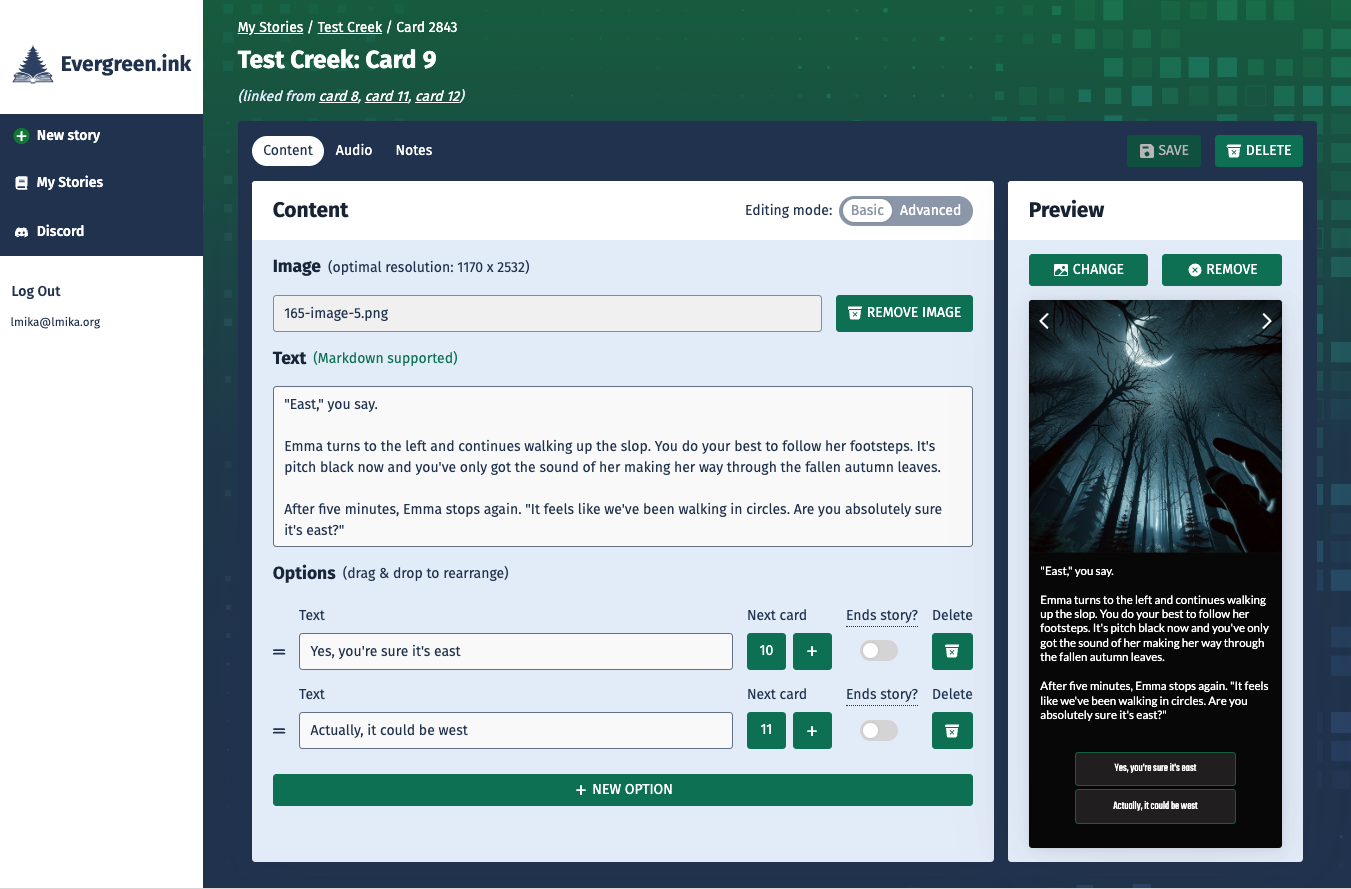
I would recommend not writing too much on a single card. Keep it to maybe two or three paragraphs. Otherwise the text will start to flow over the image, like it does on one of the cards in this story. Evergreen.ink does keep the text legible with a translucent background. But still, it’s just too much text.
Continue reading → -
Best, First, Favourite
On Reconcilable Difference #221, Merlin and John introduced the concept of “Best, First, Favourite”. For a particular category, which would you consider the best (i.e. closest to a perfect representation of that category, in however you define it), which would you recommend someone who’s interested in starting should experience first, and which one is your favourite.
I thought it was a fun idea, so I’ve put together a few of my own.
Continue reading → -
Idea For Mainboard Mayhem: A Remote Pickup
Sort of in-between projects at the moment so I’m doing a bit of light stuff on Mainboard Mayhem. I had an idea for a new element: a remote control which, when picked up, will allow the player to toggle walls and tanks using the keyboard, much like the green and blue buttons.
I used ChatGGT to come up with some artwork, and it produced something that was pretty decent.

Prompt: pixel art of a remote control with a single red button styled like the tiles found in Chips Challange, rotated 45 degrees to the right. Only issue was that the image was huge — 1024 x 1024 — and the tiles in Mainboard Mayhem were only 32 x 32.
Continue reading → -
A Few Thoughts On Using iA Presenter
Well the “big presentation” was today, the one I thought would be a good canditate for trying out iA Presenter. And after spending the last couple of weeks preparing for it, I’d thought it would be good time to give my thoughts on how it worked for me.
First, I must say that I can appreciate using an app that is opinionated. This is not a drop-in replacement for Keynote1: the app really does try and steer you towards a particular presenting style. They’re quite upfront with this: the example shown on first launch outlines how to prepare the slides and why writing out the entire presentation in full, while leaving slides as the role of accenting your points, makes for better presentation.
Continue reading → -
Resurrecting Untraveller And Finishing The RA-V Mission Posts
It’s been 10 years to the day when I had the opportunity to tour the Pacific as part of my job at the Bureau of Meteorology, the so call “RA-V Missions”. This last month or so, I’ve been writing about them in my journal, trying to get it all down before I forget. I had grand plans of publishing them on a travel blog, which I shelved a couple of months ago.
Continue reading → -
Defaults
I see that Gabz, Robb, and Manique — along with many others — have posted their defaults after listening to Hemispheric Views 097 - Duel of the Defaults!, which was a really fun episode. I thought I’d do the same.
- Mail Client: Fastmail. Web-app on the desktop and app on mobile
- Mail Server: Fastmail
- Notes: Obsidian for work. It was Obsidian for personal use but I’m trying out Notion at the moment.
- To-Do: Obsidian/Notion (todos go in as notes)
- Photo Shooting: Android camera app
- Photo Management: Google Photos
- Calendar: Google Calendar
- Cloud file storage: Google Drive
- RSS: Feedbin. I mainly read it with NetNewsWire but I also use the web-app.
- Contacts: Android contacts app.
- Browser: Safari, Vivaldi
- Chat: Mainly still use Android Messanger for SMS but started using WhatsApp more
- Bookmarks: Linkding running on Pikapods.
- Read It Later: None, but if I were to start, I’d probably try out Feedbin’s RIL service.
- Word Processing: n/a
- Spreadsheets: Google Sheets, Numbers (I don’t do a lot of spreadsheeting)
- Presentations: Keynote, but giving iA Presenter a try at the moment.
- Shopping Lists: Google Keep
- Meal Planning: n/a
- Budgeting & Personal Finance: n/a
- News: ABC1 News, in a web-browser
- Music: Alto (my own music app), Spotify
- Podcasts: Pocketcasts
- Password Management: 1Password
- Photo Editing: Google Photo
- Weather: Bureau of Meterology website.
- Social Clients: Tusky (Mastodon)
- Code Editor: GoLand (Jetbrains in general), Android Studios, or XCode
- Text Editor: Nova
- Hard Quiz Expert Subject: Probably the music of Mike Oldfield.
Scored myself based on the rules of the game and came up with 44 points. It was a little tricky as I’ve got both feet in separate ecosystems.
Continue reading → -
Why I Like Go
This question was posed to me in the Hemispheric Views Discord the other day. It’s a bit notable that I didn’t have an answer written down for this already, seeing that I do have pretty concrete reasons for why I really like Go. So I figured it was time to write them out.
I should preface this by saying that by liking Go it doesn’t mean I don’t use or like any other languages. I don’t fully understand those that need to dislike other languages like they’re football teams. “Right tool for the job” and all that. But I do have a soft-spot for Go and it tends to be my go-to language for any new projects or scripting tasks.
Continue reading →