
-
It’s amusing that the role of developer on an engineering team can feel like a role in politics, where you’re lobbying for approvals for MRs based on your immediate needs and your promises for things you’ll do in the future. 😏
-
Grafana dashboards should be definable using a DSL, maybe XML. Editing the dashboard manually, exporting the JSON, checking that into Git, and calling it “config-as-code” is self delusional. As if anyone’s going to review a JSON dump of a dashboard.
-
Feeling a little bit restless. Might be time to get a few more stamps in my passport (figuratively speaking).
-
📘 Devlog
Imagen
I won’t bore you with any justification on why I actually built this thing. It’s really nothing more than wanting a harness to play with Google’s Nano Banana. Up until now, I’ve been using Blogging Tools for that, but it lacked any ability to request changes to images in a chat-like interface (so called “multi-step flows”), where the context is preserved. So I made Imagen as a replacement.
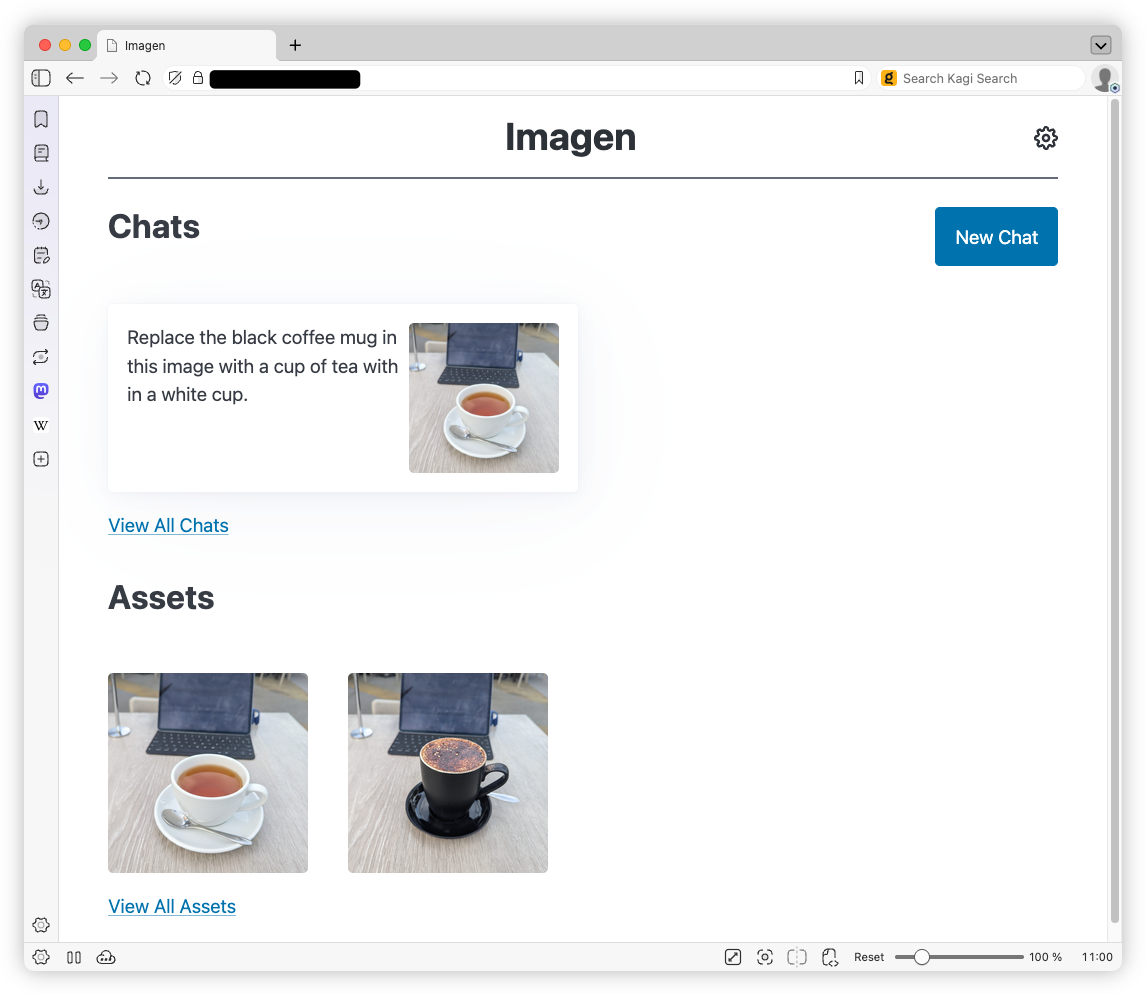
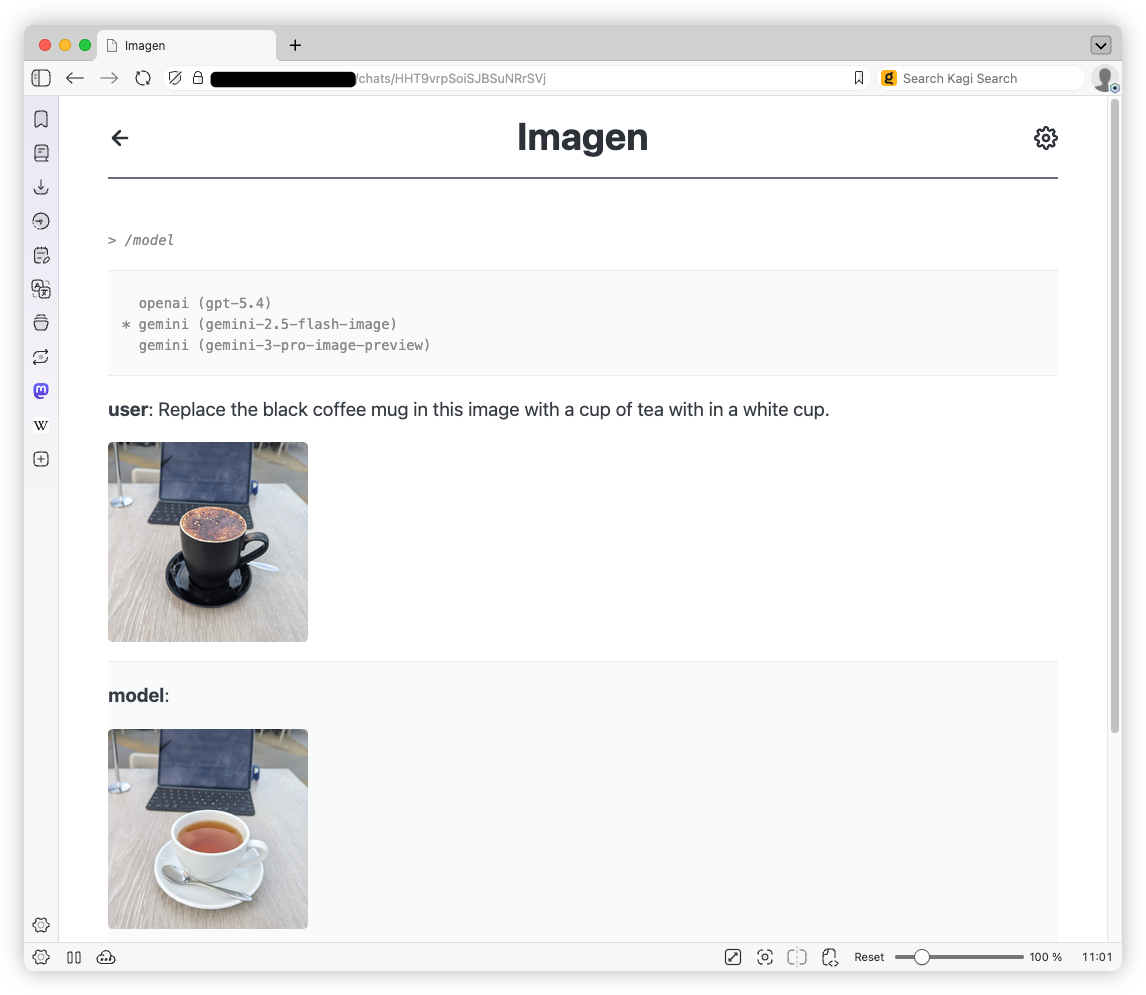
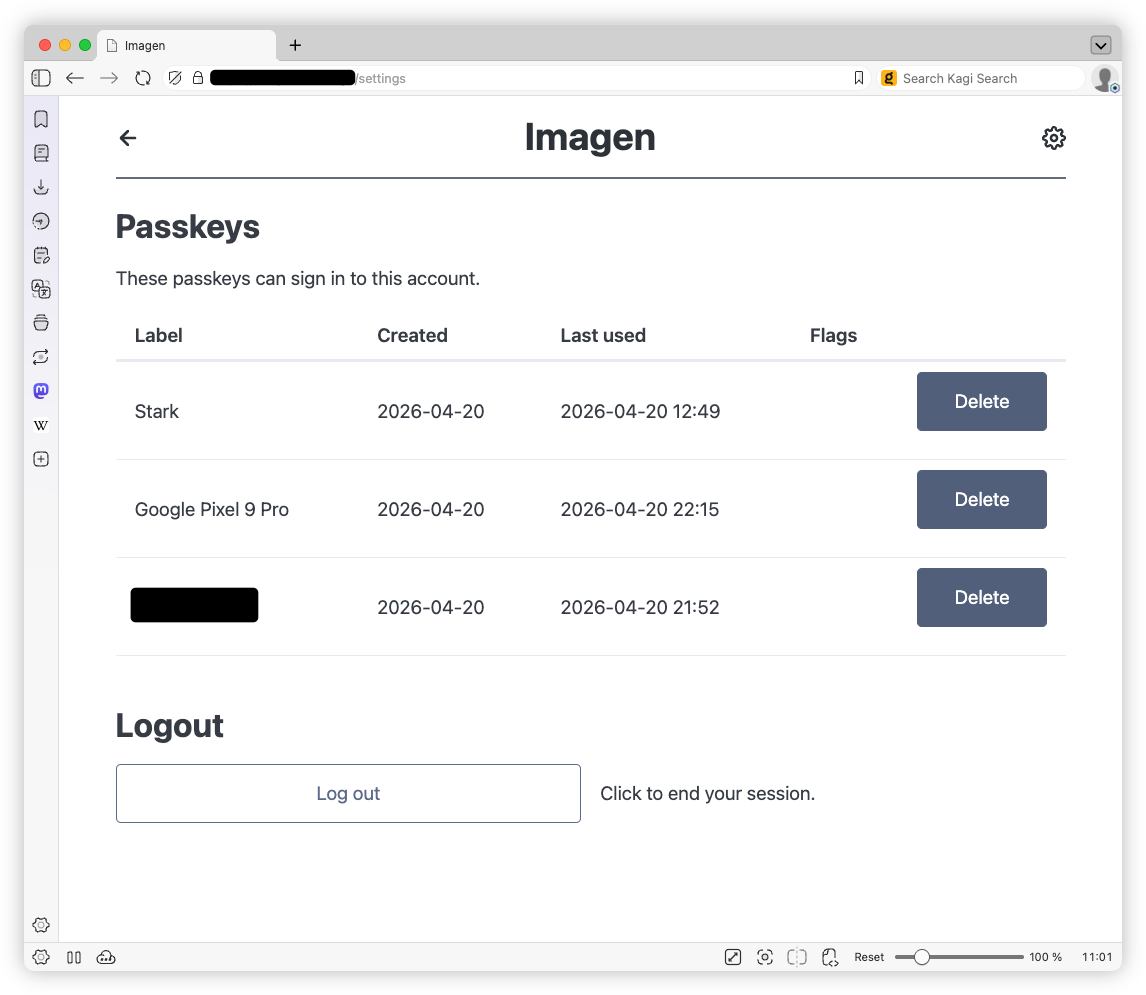
This is a pretty typical chat-based AI model harness. You start a chat requesting an image, maybe uploading one you want modified, click “Send”, and wait for the model to respond. There also exist a bunch of meta commands, entered using the
Continue reading →/prefix, that allow you change the model, and retry or undo the last request. -
Have been playing around with coding agent orchestrators recently, notably Paperclip and Gas Town, just to see what they’re capable of. They’re interesting modes of working in their own respect.
Paperclip, recommend to me by a work colleague, is a bit more polished and has quite a strange approach to interacting with the agents. Basically, you create pretend organisations, with a business goal, org chart, projects, etc. You as the human take on the role of the “board”, and you give instructions to a “CEO” agent who then “hires” a “CTO” agent to do the coding work. This can branch out to other agents taking on other “roles” like marketing or documentation writing, all which do work dispatched either by those further up the org chart or by you, the human. Interacting it feels like buying into the illusion: I found myself writing tickets along the lines of “the board will request…” or “the board has approved…”
Gas Town, by Steve Yegge, is a bit more of a scrappy upstart. The installation process was less polished and when launched, is little more than a Tmux session in-front of a Claude Code instance that has been heavily customised. Based on how Yegge describes it, it feels more automated in how it organises the agents and work, which I took to mean that you can take a more hands off approach, to the extent you feel comfortable. This has not been my experience so far, but to be fair, I’ve only had two interactions with the Mayor so far. What it does seem to have is community. Yegge talks about the group of developers that have taken his idea and have ran ahead with it, spinning it out into things like Gas City which is a project used to build other orchestrators.
As to what these orchestrators could actually product, well, I guess it depends on your tolerance of vibe-coded artefacts. So far, I’ve only used these to produce toys and prototypes; nothing that could be considered “serious”. I don’t know if it’s possible to actually make anything really commercial with these. I’m afraid to try myself.
-
Some could say we’re experiencing a power outage, but I prefer to say that I’m involuntarily exercising my UPS. 😛

-
Just had my last consultation with my doctor. For a time I thought I had a doctor, but he’s moving out of the practice. A real shame. It’s always the good ones that leave.
-
I’ve been burned by my designs of something that’s “future proof” so often by now that I’m skeptical of any thought I have along these lines. Future proofing is not a free endeavour, and simplicity and readability are usually the sacrifices made for a design that may or may not be suitable in a future that may or may not actually come. And of course, with these coding agents now on the scene, seemingly unfazed by all this introduce complexity, it doesn’t make the decision any easier.
-
Saw this in a Mastodon reply:
Why do we do the things we pour our life energy into?
I’ve been wondering this myself lately.
-
Reminder to myself: not everything said on a podcast, even “news” based ones, is true or accurate.
Another reminder to myself: even though it may seem to some that the world is very small right now, it’s still bigger than you think.
-
Managed to get a count of how many photos I have in my Google Photo library. The roundabout way I did it was to open a file picker on Vivaldi, select Files, and select Photos from the app banner at the top. Current count is 15,082.
-
People go on about the quality of code generated by AI coding agents, but I just encountered a careless copy-and-paste bug I made that completely screwed me over. So maybe having something that would catch the little details I missed isn’t such a bad thing.
-
go checkout.git build .. Just some of the miss-types I’ve been making in quick succession this morning. -
I think I’m coming round to liking passkeys, but they’ve still got quite a way to go, particularly in their UX. Tried enrolling a passkey for something in Vivaldi for Android. The presented modal was a little unclear as to what device I was actually enrolling. There wasn’t a clear “Passkey” option. Instead, in a menu of four items, I saw NFC card, or USB dongle as the first two. “This device” was the last one.
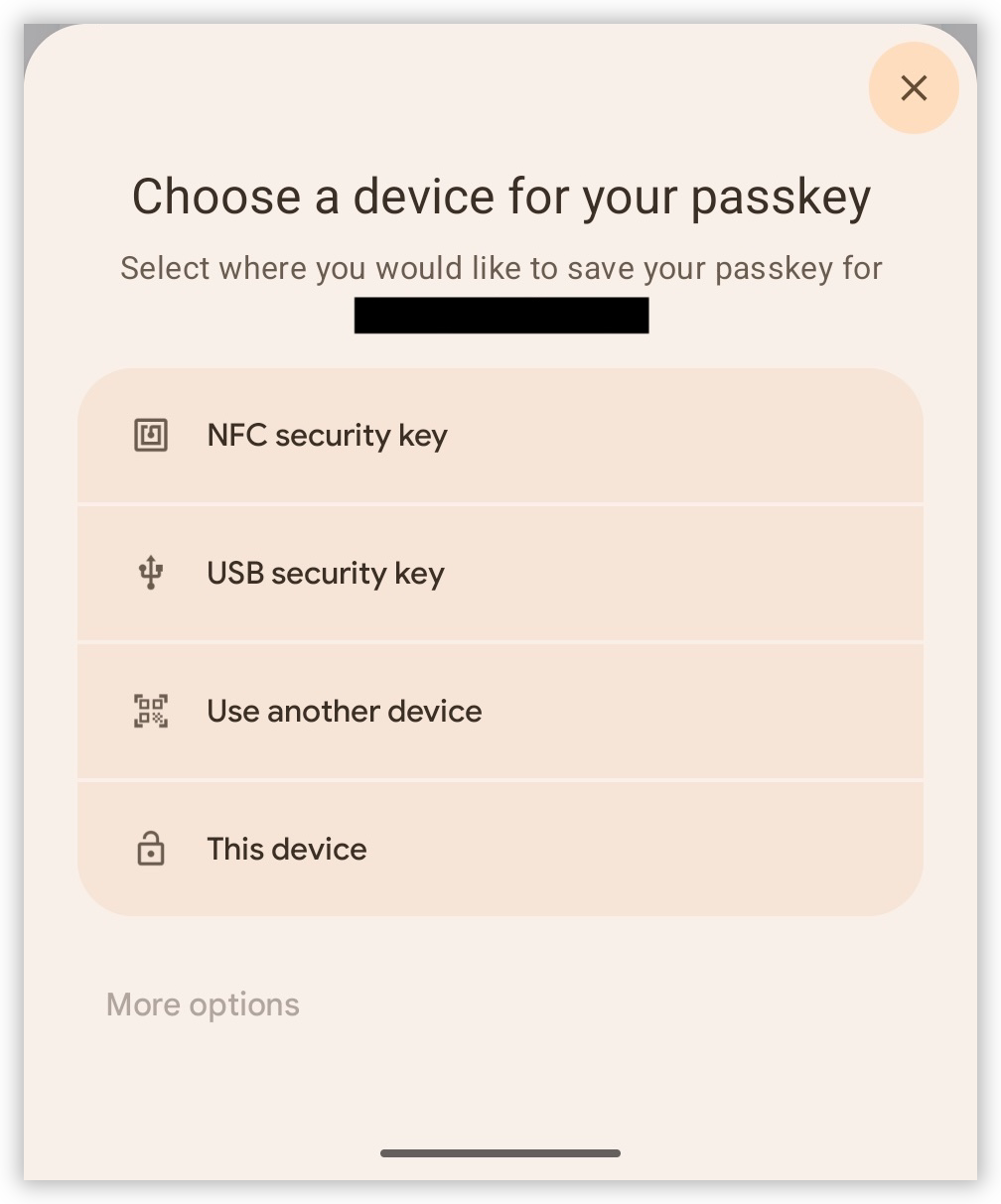
I tapped it and went through the prompts. It seemed like it produced a passkey, but when I tried to login, it wouldn’t present it as a login option. It offered something like “Use other device” or something, but nothing to suggest that it had a passkey on file.
I did eventually enroll my phone the desktop browser. The QR code exchange worked surprisingly well, but again, it was unclear which option I actually wanted. I think the choice was “Use other device.” Use? What do you mean by “use?” Either “Enroll other device” or “Setup other device” would’ve be clearer.
This could just be a Vivaldi/Chrome issue, but really, it would be nice for browser to refine this a little. The technical aspects of passkeys are amazing. It’s the UX that’s holding it back.
-
First proper fog for a while. Saw plenty of people with their cameras out on my walk to the office this morning, for good reason.

-
Hmm, either these barriers received a software update, or I was completely wrong about why PTV staff is attaching printed out “no entry” signs on them. Because…

-
Achieved a pretty decent transfer on my commute home. Train was pulling in at both Anzac and Melbourne Central when I arrived at the platform.
-
I don’t know why I get drawn to motion graphic and animation tools. It’s not like I use them. I guess it’s because if I ever did need to use them, I know there’s one out there that’s featureful and not too expensive. I have something to turn to for all the other creative domains I’ve dabbled in.
-
🔗 The Verge: The creative software industry has declared war on Adobe
Lot of links to high quality creative tools that are free and cheap. Cavalry looks really interesting.
-
Note to anyone else trying to tune caching in your web-app. If you’re using the dev tools, make sure you actually enable the cache. All the cache-related response headers will be ignored until this is done. Hopefully I just saved you the 20 minutes it took for me to diagnose this “problems”. 🤦
-
Today was a bit of a write-off, but I did get out for a walk this afternoon, along the Darebin Creek.


-
Oof! It’s been quite the month. Just came off an 11 day work week, plus a double-barrel cold and Covid infection. Fortunately the weekend is here, so recovery can begin immediately.
-
🔗 Platformer News: The scientific case for being nice to your chatbot:
Being polite to a large language model can feel strange or even silly — roughly equivalent to thanking a toaster. And yet a recent paper from Anthropic lends scientific weight to the theory that chatbots work better when you’re nice to them.
Looks like in this brave new world, we’ll all be saying thank-you to our doors. 😀
-
Interesting behaviour I’ve started to notice in myself when browsing repositories of coding agent skills: I now question whether a given Markdown file is intended for human readers or for agents. Use to be easy:
.mdare for you to read, source files are for machines. You can’t rely on this anymore.