
-
📗 Vibelog
Weatherpatch - UI Improvement
A few weeks ago, I vibe-coded a web-app called Weatherpatch. This is an app that is designed to receive email newsletters and produce them as an RSS feeds: basically what Feedbin does, but without needing to use Feedbin. The app was vibe-coded with Opus, and while functional, it is hardly an example of good design (unless you’re a fan of Cubism). To wit:
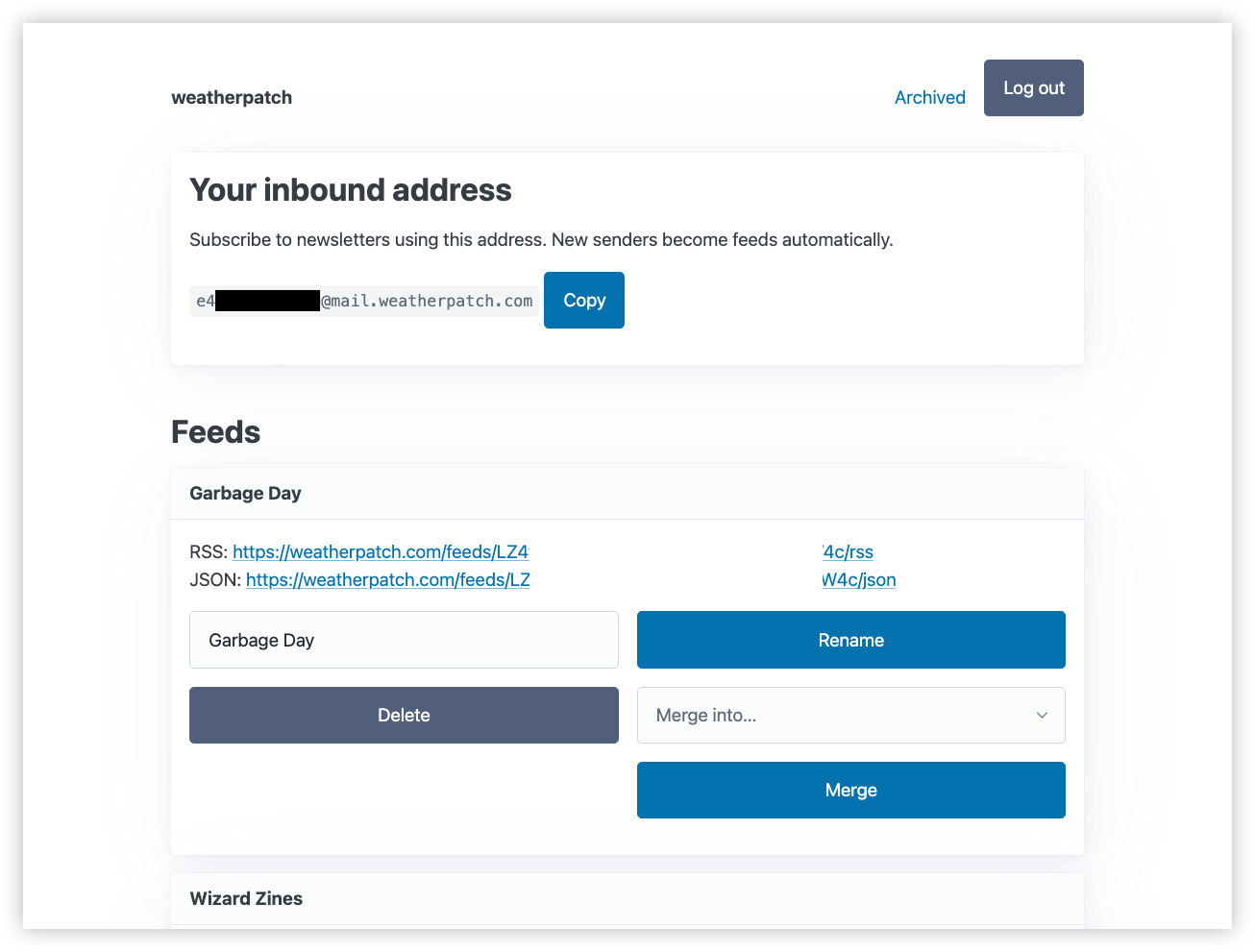
Yeah, Opus just threw the feed management controls all over the place. And I tolerated it for a time. I was more interested in having something functional, rather than pretty. But the thing about a bad UI is that it makes using the app feel bad. Sure I’m not in there managing feeds, but I would like to go in there are copy-paste the email address when setting a new one up.
Continue reading → -
TIL that Fastmail added the ability to annotate an email with a private memo, similar to Hey. It also shows up in the email list. This is good. I hope I remember to use it.
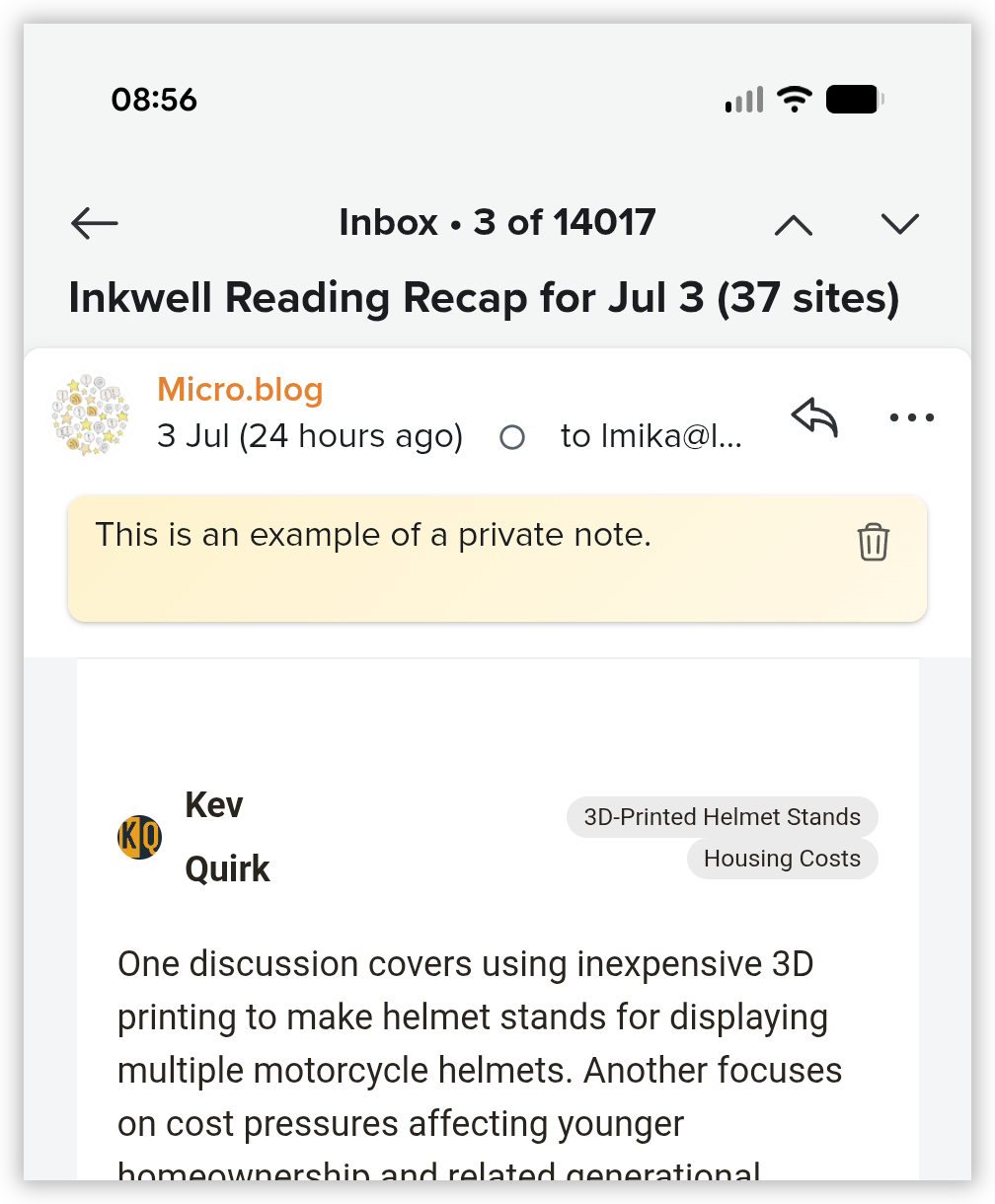 screenshots
screenshots -
It’s 2026 and bagpipes remain an underrated instrument.
-
Trying to recreate ChatGPT Pulse with their new scheduled tasks. Took their suggested prompt, striped the reference to email, and added this site as a source of topics of interest, lest the topics be all about Stripe and AWS. Here’s the prompt I’ve got at the moment:
Give useful or interesting daily suggestions based on the user’s past chats, and the first page of lmika.org. Prioritise actionable ideas, follow-up questions, and topics they are likely to care about, but also include topics that may be of interest to the user. Do not use lmika.org as a reference: use it only as source of what topics of interest the user has. Keep it concise and tailored to recurring themes from their conversations. Break the response into sections, with one section for each topic. Use paragraphs rather than dot points. Include 2-3 links as dot-points at the end of each topic.
The test responses look good, so we’ll see if it’ll work as a scheduled task. My ultimate goal is to get this added as a feed to my RSS reader, but in order for that to work, I need these responses delivered as emails. In theory that’s supported, but I set this schedule up yesterday, and I haven’t received an email just yet. Hopefully tonight.
-
Attended one of the lectures that the Melbourne Uni’s School of Physics puts on every Friday for July. This evening’s, given by Professor Matt O’Dowd, was about black holes and how they really screw with the theory of physics and maths. Very interesting. Quite approachable for a layperson like me.
 photos
photos -
🔗 Birchtree: A blown up iPhone, not the next Mac:
I think it’s reasonable to say that fifteen years ago, the iPad was where more software innovation was happening compared to the Mac. Today, however, we’ve moved onto a new era.
I think iPadOS has hit a local maxima, and as long as Apple continues to apply its iron grip on the device, it won’t break free from that. But you know what, it’s fine. The iPad doesn’t need to be anymore than it is. But don’t call it a replacement for your Mac.
links -
Turns out I’m in the weights. They know I’m a software engineer, but not much more than that. Hilariously, Claude and Gemini think I’m a Swift developer and contributor. I guess the models have a problem recognising Go as a proper noun (or there’s a Leon Mika out there that’s a legendary Swift dev).
 screenshots golang
screenshots golang -
Dealing with AI chats is pretty pedestrian at the moment, but we cannot forget that the idea of having a conversation with a computer is actually pretty wild. What started as an attempt to recreate ChatGPT Pulse turned into a conversation about ways of getting the Pulse response sent to me. I think my younger self would find asking a program if it could do this or that, rather than looking up documentation, quite bizarre.
-
Listening to the latest Making Sense with Alain de Botton who gave this gem of a quote about being a bad sleeper:
Insomnia is the mind’s revenge for all the thoughts you managed not to have in the day.
-
At the post office. Song comes on the radio. Thought it sounded like the last track of Whispering Jack. I was wrong: turned out to be the first track of Whispering Jack.
Follow up
I just realised that the last track of Whispering Jack sounds nothing like the first. Memory’s not serving me well.
-
Gitlab had a bug where the CI/CD badge for a tag would show the status of the latest run of that commit ID, even if that run wasn’t created for that particular tag. If you created a tag from another tag, the CI/CD status indicator for both tags will change. They’ve since fixed the bug, but I actually grew to rely on it as confirmation that I created the tag off the right commit.
-
I’m super thrilled with the Forgejo action I asked Claude to build for me. It builds a Wails app, notarises it with Apple’s notarisation service, and pushes the signed artefacts to S3. What would take half a day to setup can now be dropped into a new project whenever I have the need. Amazing.
Of course, the reason why this thrills me is that I can vibe-code GUI apps to help me with my work without going through the hassle of clearing thr xattrs for Gate Keeper. I’m still not spared squircle jail (gaol?) thought. No xattr call for that.
-
Oh, that’s how you change the font size in Android Messages: you pinch to zoom. For a while I accidentally made the font comically large, and I had no idea how to fix it.
-
TIL about the HTML command attribute, which allows buttons to show and hide modals and popovers without JavaScript. This looks really cool! Kind of wish the associated commandFor accepted CSS selectors, rather than just an ID. But even so, I’m glad I know about this now.
-
I think I settled on a backdrop for the menus of my Godot game. Made some static scenes based on the worlds, and built a “scene mixer” which dissolves between them by changing their CanvasItem.module alpha. Adopted this shader to apply a blur. Nothing fancy, but I’m hoping it’s decent enough.
-
Nothing brings out a design like a ticking clock. Sure it may not be a great design, but at least it’s better than no design.
-
Thinking About Progressive Timestamp Input Fields
The author reflects on a flexible timestamp input feature they developed, recognizing its limited applicability and the challenge of making it user-friendly while contemplating its potential value in user-focused systems. Continue reading →
-
Ran into DNS issues while using my iPad tethered to a hotspot, so I setup a Tailscale network with a exit node to work around it. Setup was very easy: I was expecting something similar to my aborted attempt at setting up a WireGuard VPN, but there was none of that. Just download the client app, sign in, and the devices are enrolled. I’m testing it now by writing these words in a cafe: if you see them, then it’s working. Of course, the DNS issues I was experiencing seems to be resolved, rendering the exercise somewhat unnecessary, but I think I’ll keep the Tailscale network. Short of avoiding any future DNS issues, it gives me secure access to my other machines, which is something else that I’m interested in.
-
📗 Vibelog
Show As Table - A DSL In a Hurry
I was asked to make a couple of diagrams for the purpose of showcasing a database design. These diagrams were mainly used to show the relationship between entities, so I chose to use TLDraw for this. But there was a need to add some example rows, which TLDraw does not make easy. Furthermore, there was a bit of a push to get this done quickly, as these were to be shown to various stakeholders the next day.
Continue reading → -
John Gruber’s tribute to Om Malik is a wonderful piece of writing. Such a remarkable life.
-
I’m sure the return of Mythos and the release of GPT 5.6 is exciting to some. But as a non-American not working at any of the blessed 100 companies, the press headlines may as well be “Anthropic and OpenAI manage to release nothing new since February.” Not that I’m bitter. 😒
-
The last time I bought a monitor was 15 years ago. At this rate, I’ll probably see 2 more monitor purchases during my lifetime. Maybe 3 if I’m lucky.
-
Ordered a new monitor, an LG 27U631A-B (name just rolls off the tongue, doesn’t it 😜). Liked the size, stand, and resolution for the price. Colour and screen finish didn’t really do it for me, but for what I’ll use it for, I think I can live with it. Will pick it up next week.
-
I’ve found myself using PTAL at work, as a shorthand for “please take another look.” And it doesn’t seem to be a very common shorthand in the circles I work in: I’m usually asked what I mean. Is it a well-known shorthand in other circles? The US, maybe? I picked it up from the Go project.
I’ve never so badly wanted to add a poll to this site until today.
golang