Made This
-
I couldn’t find any decent bridging wire at Jaycar either so I used reclaimed wire from a CAT-5 cable. I stripped the insulation completely, twirled the wires, and soldered them onto the contacts. It worked really well. ↩︎
- Fix the activity indicator that is sometimes not clearing when a long running task is finished.
- Fix a bug in which executing a query expression with just the sort key does nothing. I suspect this has something to do with the query planner somehow getting confused if the sort key is used but the partition key is not.
- Fix a bug where
set default-limitsreturns a bad value. - Add a way to describe the table, i.e. show keys, indices, etc. This should also be made available to scripts.
- Add a way to “goto” a particular row, that is select rows just by entering the value of the partition and optionally the sort key.
-
Dynamo-Browse was actually the second TUI tool I made as part of what was called “awstools”. The first was actually an SQS browser. ↩︎
- Audax toolset is now distributed via Homebrew. Check out the Downloads page for instructions.
- A new mark command to mark all, unmark all, or toggle marked rows. The
unmarkcommand is now an alias tomark none. - Query expressions involving the partition and sort key of the main table are now executed as a DynamoDB queries, instead of scans.
- The query expression language now supports conjunction, disjunction, and dot references.
- Fixed a bug which was not properly detecting whether MacOS was in light mode. This was making some highlighted colours hard to see while in dark mode.
- Fixed the table-selection filter, which was never properly working since the initial release.
- Fixed the back-stack service to prevent duplicate views from being pushed.
- Fixed some conditions which were causing seg. faults.
-
Or you can like, comment or subscribe on YouTube if that’s your thing 😛. ↩︎
-
Someone once said that an insane person is one that does the same thing twice and expects different results. That someone has never worked in technology. ↩︎
-
Well, there might be a way using ANSI escape sequences, but that goes against the approach of the framework. ↩︎
- First determine whether the operation is either
=or^=(or whatever else) - If it’s
=and the field on the left is either a partition or sort key, this can be represented as a query - If it’s
^=, first determine whether the operand is a string, (if not, fail) and then determine whether the field on the left is a sort key. If so, then this can be query. - Otherwise, it will have to be a scan.
Spent some time closing off the Dynamo-Browse shortlist. I think I’ve got most of the big ticket items addressed. Here’s a brief update on each one:
Fix the activity indicator that is sometimes not clearing when a long running task is finished.
How long running tasks are dealt with has been completely overhauled. The previous implementation had many opportunities for race conditions, which was probably the cause of the activity indicator showing up when nothing was happening. I rewrote this using a dedicated goroutine for handling these tasks, and the event bus for sending events to the other areas of the app, including the UI layer. Updates and status changes are handled with mutexes and channels, and it just feels like better code as well.
It will need some further testing, especially in real world use against a real DynamoDB database. We’ll see if this bug rears its unpleasant head once more.
Fix a bug in which executing a query expression with just the sort key does nothing. I suspect this has something to do with the query planner somehow getting confused if the sort key is used but the partition key is not.
Turns out that this was actually a problem with the “has prefix” operator. It was incorrectly determining that an expression of the form sort_key ^= "string" with no partition key could be executed as a query instead of a scan. Adding a check to see if the partition key also existed in the expression fixed the problem.
Also made a number of other changes to the query expression. Added the ability to use indexed references, like this[1] or that["thing"]. This has been a long time coming so it’s good to see it implemented. Unfortuntly this only works reliably when a single level is used, so this[1][2] will result in an error. The cause of this is a bug in the Go SDK I’m using to produce the query expressions that are run against the database. If this becomes a problem I look at this again.
I also realised that true and false were not treated as boolean literals, so I fixed that as well.
Finally, the query planner now consider GSIs when it’s working out how to run a query expression. If the expression can be a query over a GSI, it will be executed as one. Given the types of queries I need to run, I’ll be finding this feature useful.
Fix a bug where
set default-limitsreturns a bad value.
This was a pretty simple string conversion bug.
Add a way to describe the table, i.e. show keys, indices, etc. This should also be made available to scripts. Add a way to “goto” a particular row, that is select rows just by entering the value of the partition and optionally the sort key.
These I did not do. The reason is that they’ll make good candidates for scripts and it would be a good test to see if they can be written as one. I think the “goto” feature would be easy enough. I added the ability to get information about the current table in the script, and also for scripts to add new key bindings, so I don’t force any issues here.
The table description would be trickier. There’s currently no real way to display a large block of text (except the status bar, but even there it’s a little awkward). So a full featured description might be difficult. But the information is there, at least to a degree, so maybe something showing the basics would work.
Anyway, the plan now is to use this version for a while to test it out. Then cut a release and update the documentation. That’s a large enough task in and of itself, but I’d really like to get this finished so I can move onto something else.
Mahjong Score Card Device
I’ve recently started playing Mahjong with my family. We’ve learnt how to play a couple of years ago and grown to like it a great deal. I’m not sure if you’re familiar with how the game is scored, and while it’s not complicated, there’s a lot of looking things up which can make scoring a little tedious. So my dad put together a Mahjong scoring tool in Excel. You enter what each player got at the end of a round — 2 exposed pungs of twos, 1 hidden kong of eights, and a pair of dragons, for example — and it will determine the scores of the round and add them to the running totals. It also tracks the winds of the players and the prevailing winds, which are mechanics that can affects how much a player can get during a round. The spreadsheet works quite well, but it does mean we need to keep a bulky laptop around whenever we play.
I wondered if the way we calculated and tracked the scores could be improved. I could do something like build a web-style scorecard, like I did for Finska, but it gets a little boring doing the same stuff you know how to do pretty well. No, if I wanted to do this, I wanted to push myself a little.
I was contemplating building something with an Arduino, maybe with a keypad and a LCD display mounted in a case of some sort. I’ve played around with LCD displays using an Arduino before so it wasn’t something that seemed too hard to do. I was concerned about how well I could achieved the fit and finished I wanted this to have to be usable. Ideally this would be something that I can give to others to use, not be something that would just be for me (where’s the fun in that?). Plus, I didn’t have the skills or the equipment to mount it nicely in an enclosed case that is somewhat portable. I started drawing up some designs for it, but it felt like something I wouldn’t actually attempt.

One day I was perusing the web when I came across the SMART Response XE. From what I gathered, it a device that was built for classrooms around the early 2010s. Thanks to the smartphone, it didn’t become super successful. But hobbyist have managed to get their hands on them and reprogram them to do their own thing. It’s battery powered, had a full QUERTY keyboard and LCD display, is well built since it was designed to be used by children at schools, and feels great in the hand. And since it has an Atmel microprobes, it can be reprogrammed using the Arduino toolchain. Such a device would be perfect for this sort of project.
I bought a couple, plus a small development adapter, and set about trying to build it. I’ll write about how I go about doing it here. As the whole “work journal” implies, this won’t be a nice consistent arc from the idea to the finished project. I’m still very much a novice when it comes to electronics, and there will be setbacks, false starts, and probably long periods where I do nothing. So strap in for a bit of bumping around in the dark.


First Connection Attempt
The way to reprogram the board is to open up the back and slot some pins through the holes just above the battery compartment. From my understanding, these holes expose contact pads on the actual device board that are essentially just an ISP programming interface. In theory, if you had an ISP programmer and a 6 pin adapter, you should be able to reprogram the board.

The first attempt of attempting to connect to the SMART Response XE was not as successful as I hoped. For one thing, the SRXE Development Adapter was unable to sit nicely within the board. This is not a huge issue in and of itself, but it did mean that in order to get any contact with the board, I would have to push down on the device with a fair bit of force. And those pogo pins are very fragile. I think I actually broke the tip of one of them, trying to use an elastic band and tape to keep the board onto the . I hope it does not render the board useless.
The other issue I had is that the arrangement of the 6 pin header on the developer board is incompatible with the pins of the ISP programmer itself. The pins on the ISP programmer are arranged to plugin directly to an Arduino, but on the development board, the pins are the the wrong way round. The left pin on both the male pin on the board and female socket from the IVR programmer are both Vcc, when in order to work, one of them will need to be a mirror image of the other. This means that there’s no way to for the two to connect such that they line up. If the pins on the SMART Response XE were on the back side of the board, I would be able to plug them in directly.
I eventually got some jumper wires to plug the ISP programmer into the correct pins. Pushing down on the board I saw the LEDs on the adapter light up, indicating activity. But when I tried to verify the connection using avrdude, I got no response:
$ avrdude -c usbASP -p m128rfa1
avrdude: initialization failed, rc=-1
Double check the connection and try again, or use -F to override
this check.
avrdude done. Thank you.
So something was still wrong with the connection. It might have been that I’ve damaged one of the pins on the dev board while I was trying to push it down. I’m actually a little unhappy with how difficult it is to use the adapter to connect to the device, and I wondered if I could build one of my own.
Device Adapter Mk. 1
I set about trying just that. I wanted to be able to sit the device on top of it such that the contact points on the board itself will sit on the adapter. I was hoping to make the pins slightly longer than the height of the device such that when I rest it on the adapter, the device was slightly balanced on top of the pins and the board will make contact with gravity alone.
This meant that the pins had to be quite long and reasonably sturdy. Jaycar did not have any pogo pins of the length I needed (or of any length) so I wondered if the pins from a LED would work1. I bought a pack of them, plus a prototyping board, and set about building an adapter for myself. Here the design I came up with:
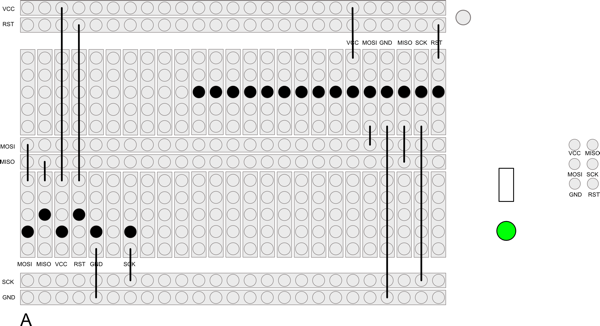
And here is the finished result:


And it’s a dud! The position of the header gets in the way of where the device lines up to rest on the pins. But by far the biggest issue is the pins themselves. I tried placing them in the holes and rested the circuit board on top with a small spacer while I was soldering them. The idea is that after removing the spacer the pins will be higher than the device. I was hoping to cut them down to size a little, but I cut them unevenly, which meant that some of the pins won’t make contact. When I try resting the device on the board I get no rocking, which means that I suspect none of the pins make contact. I’m still not happy with the LED pins either. They don’t seem strong enough to take the weight of the device without bending.
The best thing about it was the soldering, and that’s not great either. I’m not sure I’ll even try this adapter to see if it works.
Next Steps
Before I create a new adapter, I want to try to get avrdude talking with the board first. I think what I’ll try next is resting some nails in the holes and attaching them to alligator clips hooked up to the ISP programmer. If this works, I see if I can set about building another board using the nails. I won’t use the header again as I think it will just get in the way. It might be enough to simply solder some hookup wires directly onto the prototyping board.
Anyway, more to come on this front.
Update 29 Oct 2023: I haven’t revisited this project since this post.
Looking at the “backlog” of things to work on for Dynamo-Browse before I set it aside. I’ll fix a few bugs and add a few small features that I’ve found myself really wanting. The short list is as follows:
I’ll start with these and see how I go.
Oh, and one more thing: I will need to kill my darlings, namely the other commands in the “audax” repository that I’ve hacked togeather. They’re mildly useful — one of them is used to browse SSM parameters and another is used to view JSON log files — but they’re unloved and barely functional. I’ll move them out of the “audax” repository and rename this repo to “dynamo-browse”, just to make it less confusing for everyone.
I think I’ll take a little break from Dynamo-Browse. There’s a list of small features that are on my TODO list. I might do one or two of them over the next week, then cut and document a release, and leave it for a while.
I’m still using Dynamo-Browse pretty much every day at work, but it feels a little demotivating being the only person that’s using it. Even those at work seem like they’ve moved on. And I can understand that: it’s not the most intuitive bit of software out there. And I get the sense that it’s time to do something new. Maybe an online service or something. 🤔
Finally bit the bullet and got scripting working in Dynamo-Browse. It’s officially in the tool, at least in the latest development version. It’s finally good to see this feature implemented. I’ve been waffling on this for a while, as the last several posts can attest, and it’s good to see some decisions made.
In the end I went with Tamarin as the scripting language. It was fortunate that the maintainer released version 1.0 just as I was about to merge the scripting feature branch into main. I’ve been trying out the scripting feature at work and so far I’ve been finding it to work pretty well. It helps that the language syntax is quite close to Go, but I also think that the room to hide long-running tasks from the user (i.e. no promises everywhere) dramatically simplifies how scripts are written.
As for the runtime, I decided to have scripts run in a separate go-routine. This means they don’t block the main thread and the user can still interact with the tool. This does mean that the script will need to indicate when a long running process is occurring — which they can do by displaying a message in the status line — but I think this is a good enough tradeoff to avoid having a running script lock-up the app. I still need to add a way for the user to kill long-running scripts (writing a GitHub ticket to do this now).
At the moment, only one script can run at any one time, sort of like how JavaScript in the browser works. This is also intentional, as it will prevent a whole bunch of scripts launching go-routines and slowing down the user experience. I think it will help in not introducing any potential synchronisation issues with parallel running scripts accessing the same memory space. No need to build methods in the API to handle this. Will this mean that script performance will be a problem? Not sure at this stage.
I’m also keeping the API intentionally small at this stage. There are methods to query a DynamoDB table, get access to the result set and the items, and do some basic UI and OS things. I’m hoping it’s small enough to be useful, at least at the start, without overwhelming script authors or locking me into an API design. I hope to add methods to the API over time.
Anyway, good to see this committed to.
Poking Around The Attic Of Old Coding Projects
I guess I’m in a bit of a reflective mood these pass few days because I spent the morning digging up an old project that was lying dormant for several years. It’s effectively a clone of Chips Challenge, the old strategy game that came with the Microsoft Entertainment Pack. I was a fan of the game when I was a kid, even though I didn’t get through all the levels, and I’ve tried multiple times to make a clone of it.
The earliest successful clone I can think of was back when I was using Delphi, which I think was my teens. It’s since been lost but I do recall having a version that work and was reasonably true to the original game as possible. It wasn’t a particularly accurate clone: I do recall some pretty significant bugs, and the code itself was pretty awful. But it was nice to be able to do things like design my own levels (I wasn’t as internet savvy back then and I didn’t go looking for level editors for the Microsoft’s release of Chips Challenge). Eventually I stopped working on it, and after a few updates to the family computer, plus a lack of backups or source control, there came a time where I lost it completely.
Years later, I made another attempt at building a clone. I was dabbling in .Net at the time and I think I was working on it as an excuse to learn C#. I think I got the basics of the game and associated level editor working but I didn’t get much further than that. Either I got bored and stopped working on it.
I started the latest clone nine years ago. I can’t remember the original motivation. I was just getting into Go at the time and I think it was both to learn how to build something non-trivial in the language, and to determine how good Go was for building games. Although this is probably just a rationalisation: I’m sure the real reason was to work on something fun on the side.

Over the first five years of its life or so, I worked on it on and off, adding new game elements (tiles, sprites, etc.) and capabilities like level scripts. One thing I am particularly proud of was building a mini-language for selecting game elements using something akin to CSS selectors. Want to select all wall tiles? Use the selector SOLD. How about configuring a water tile to only allow gliders and the player but only if they have the flipper? Set the Immune attribute of the water tile to GLID,PLYR:holding(flippers). This was particularly powerful when working on tile and sprite definitions.
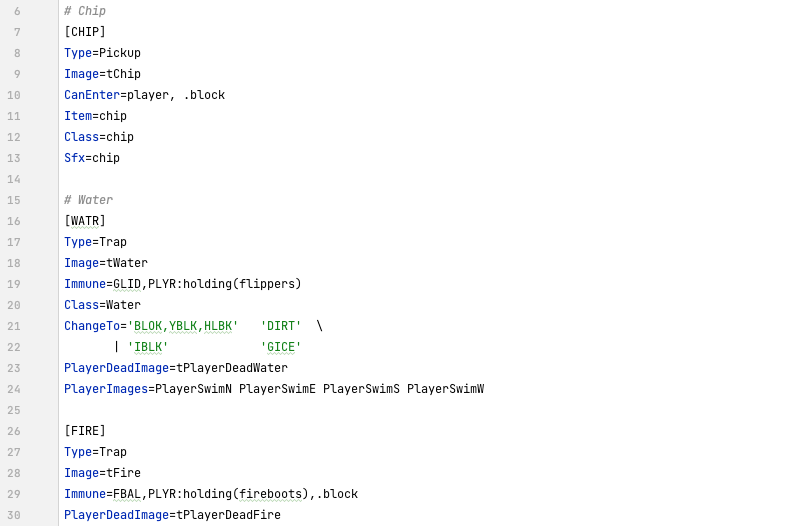
I didn’t put as much effort into content however. As of today, there are only 18 or so unique levels, and about half of them are ones that I consider good. I certainly put little effort into the graphics. Many of the tile images were just taken from the original tile-set and any additional graphics were basically inspirations from that. This blatant copyright violation is probably why this project won’t see the light of day.
I’m impressed on how Go maintains its backwards capability: moving from 1.13 to 1.19 was just a matter of changing the version number in the .mod file. I haven’t updating any of the libraries, and I’m sure the only reason why it still builds is because I haven’t dared to try.
I’ll probably shouldn’t spend a lot of time on this. But it was fun to revisit this for a while.
One final thing: I might write more about projects I’ve long since abandoned or have worked on and haven’t released, mainly for posterity reasons but also because I like reflecting on them later. You never know what you’d wish you documented until you’ve lost the chance to do so.
Spent the day restyling the Dynamo-Browse website. The Terminal theme was fun, but over time I found the site to be difficult to navigate. And if you consider that Dynamo-Browse is not the most intuitive tool out there, an easy to navigate user manual was probably important. So I replaced that theme with Hugo-Book, which I think is a much cleaner layout. After making the change, and doing a few small style fixes, I found it to be a significant improvement.
I also tried my hand at designing a logo for Dynamo-Browse. The blue box that came with the Terminal theme was fine for a placeholder, but it felt like it was time for a proper logo now.
I wanted something which gave the indication of a tool that worked on DynamoDB tables while also leaning into it’s TUI characteristics. My first idea was a logo that looked like the DynamoDB icon in ASCII art. So after attempting to design something that looks like it in Affinity Designer, and passing it through an online tool which generated ASCII images from PNG, this was the result:
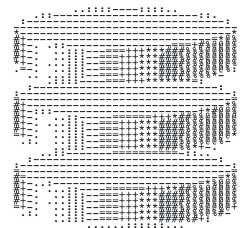
I tried adjusting the colours of final image, and doing a few things in Acorn to thicken the ASCII characters themselves, but there was no getting around the fact that the logo just didn’t look good. The ASCII characters were too thin and too much of the background was bleeding through.
So after a break, I went back to the drawing board. I remembered that there were actually Unicode block characters which could produce filled-in rectangles of various heights, and I wondered if using them would be a nice play on the DynamoDB logo. Also, since the Dynamo-Browse screen consists of three panels, with only the top one having the accent colour, I thought having a similar colour banding would make a nice reference. So I came up with this design:

And I must say, I like it. It does look a little closer to low-res pixel art than ASCII art, but what it’s trying to allude to is clear. It looks good in both light mode and dark mode, and it also makes for a nice favicon.
That’s all the updates for the moment. I didn’t get around to updating the screenshots, which are in dark-mode to blend nicely with the dark Terminal theme. They actually look okay on a light background, so I can probably hold-off on this until the UI is changed in some way.
I’ve been resisting using mocks in the unit tests of Dynamo-Browse, but today I finally bit the bullet and started adding them. There would have just been too much scaffolding code that I needed to write without them. I guess we’ll see if this was a wise decision down the line.
Thinking About Scripting In Dynamo-Browse, Again
I’m thinking about scripting in Dynamo-Browse. Yes, again.
For a while I’ve been using a version of Dynamo-Browse which included a JavaScript interpreter. I’ve added it so that I could extend the tool with a few commands that have been useful for me at work. That branch has fallen out of date but the idea of a scripting feature has been useful to me and I want to include it in the mainline in some way.
The scripting framework works, but there are a few things that I’m unhappy about. The first is around asynchronicity and scheduling. I built the scripting API around the JS event-loop included in interpreter. Much like a web-browser or Node.js, this event-loop allows the use of promises for operations that can be dispatched asynchronously. The interpreter, however, is not ES6 compatible, which means no async/await keywords. The result is that many of the scripts that I’ve been writing are littered with all these then() chains. Example:
const session = require("audax:dynamo-browse/session");
const ui = require("audax:dynamo-browse/ui");
const exec = require("audax:x/exec");
plugin.registerCommand("cust", () => {
ui.prompt("Enter UserID: ").then((userId) => {
return exec.system("lookup-customer-id.sh", userId);
}).then((customerId) => {
let userId = output.replace(/\s/g, "");
return session.query(`pk="CUSTOMER#${customerId}"`, {
table: `account-service-dev`
});
}).then((custResultSet) => {
if (custResultSet.rows.length == 0) {
ui.print("No such user found");
return;
}
session.resultSet = custResultSet;
});
});
Yeah, I know; this is nothing new if you’ve been doing any web-dev or Node in the past, but it still feels a little clunky exposing the execution details to the script writer. Should that be something they should be worried about? Feels like the tool should take on more here.
The second concern involves modules. The JavaScript interpreter implements the require() function which can be used to load a JS module, much like Node.js. But the Node.js standard library is not available. That’s not really the fault of the maintainers, and to be fair to them, they are building out native support for modules. But that support isn’t there now, and I would like to include some modules to do things like access the file system or run commands. Just adding them with non-standard APIs and with name that are the same as equivalent modules in node Node.js feels like a recipe for confusion.
Further exacerbating this is that script authors may assume that they have access to the full Node standard library, or even NPM repositories, when they won’t. I certainly don’t want to implement the entire Node standard library from scratch, and even if the full library was available to me, I’m not sure the use of JavaScript here warrants that level of support.
Now, zooming out a little, this could all be a bit of a non-issue. I’ve haven’t really shared this functionality with anyone else, so all this could be of no concern to anyone else other than myself. But even so, I’m am thinking of options other than JavaScript. A viable alternative might be Lua — and Go has a bunch of decent interpreters — but I’m not a huge fan of Lua as a language. Also, Lua’s table structure being used for both arrays and structures seems like a source of confusion, especially when dealing with JSONish data structures like DynamoDB items.
One interpreter that has caught my eye is Tamarin. It’s early in its development already it’s showing some promise. It offers a Go like syntax, which is nice, along with native literals for lists, sets and maps, which is also nice. There’s a bit of a standard library already in place to do things like string and JSON operations. There’s not really anything that interacts with the operating system, but this is actually an advantage as it will mean that I’m free to write these modules myself to do what I need. The implementation looks simple enough which means that it will probably play nicely with Go’s GC and scheduler.
How the example above could look in Tamarin is given below. This assumes that the asynchronous aspects are completely hidden from the script author, resulting in something a little easier to read:
ext.command("cust", func() {
var userId = ui.prompt("Enter UserID: ")
var commandOut = exec.system("lookup-customer-id.sh", userId).unwrap()
var userId = strings.trim_space(commandOut)
var custResultSet = session.query(`pk=$1`, {
"table": "account-service-dev",
"args": [userId]
}).unwrap()
if len(custResultSet.items.length) == 0 {
ui.print("No such user found")
return
}
session.set_result_set(custResultSet)
})
So it looks good to me. However… the massive, massive downside is that it’s not a well-known language. As clunky as JavaScript is, it’s at least a language that most people have heard of. That’s a huge advantage, and one that warrants thinking twice about it before saying “no, thanks”. I’m not expecting Dynamo-Browse to be more popular than sliced bread (I can count on one hand the number of user’s I know are using it), but it would be nice if scripting was somewhat approachable.
One thing in Tamarin’s favour is that it’s close enough to Go that I think others could pick it up relatively easily. It’s also not a huge language — the features can be describe on a single Markdown page — and the fact that the standard library hasn’t been fully fleshed out yet can help keep things small.
I guess the obvious question is why not hide the scheduling aspects from the JavaScript implementation? Yeah, I think that’s a viable thing to do, although it might be a little harder to do than Tamarin. That will still leave the module exception issue though.
So that’s where I am at the moment. I’m not quite sure what I’ll do here, but I might give Tamarin a go, and see if it result in scripts that are easier to read and write.
One could argue that this pontificating over something that will probably only affect me and a handful of other people is even worth the time at all. And yeah, you’re probably right in thinking that it isn’t. To that, I guess the only thing I can respond with is that at least I got a blog post out of it. 🙂
One last concern I do have, regardless of what language I choose, is how to schedule the scripts. If I’m serious about not exposing the specifics of which thread/goroutine is waiting for what to the script author, I’d like to run the script in a separate goroutine from the main event loop. The concern is around start-up time: launching a goroutine is fast, but if I want to execute a script in response to a keystroke, for example, would it be fast enough? I guess this is something I should probably test first, but if it is a little unresponsive, the way I’m thinking of tackling this is having a single running goroutine waiting on a channel for script scheduling events. That way, the goroutine will always be “warm” and they’ll be no startup time associated with executing the script. Something to think about.
Project Exploration: A Check-in App
I’m in a bit of a exploratory phase at the moment. I’ve set aside Dynamo-Browse for now and looking to start something new. Usually I need to start two or three things before I find something that grabs me: it’s very rare that I find myself something to work on that’s exciting before I actually start working on it. And even if I start something, there’s a good chance that I won’t actually finish it.
So it might seem weird that I’d write about these explorations at all. Mainly I do it for prosperity reasons: just something to record so that when look back and think “what was that idea I had?”, I have something to reflect on.
With that out of the way, I do have a few ideas that are worth considering. Yesterday, I’ve started a new Flutter project in order to explore an idea for an app that’s been rattling around in my head for about a month or two.
Basically the idea is this: I keep a very simple check-in blog where I post check-ins for locations that seem useful to recall down the line. At the moment I post these check-ins manually, and usually a few hours after I leave in order to maintain some privacy of my movements. I’ve been entertaining the idea of an app that would do this: I can post a check-in when I arrive but it won’t be published several hours after I leave. The check-ins themselves follow a consistent format so the actual act of filling in the details can be handled by the app by presenting these properties like a regular form. At the same time, I wanted to try something with the Micropub format and possibly the IndieAuth protocol.
So I started playing around with a Flutter app that could do this. I got to the point where I can post new check-ins and they will show up in a test blog. Here are some screenshots:
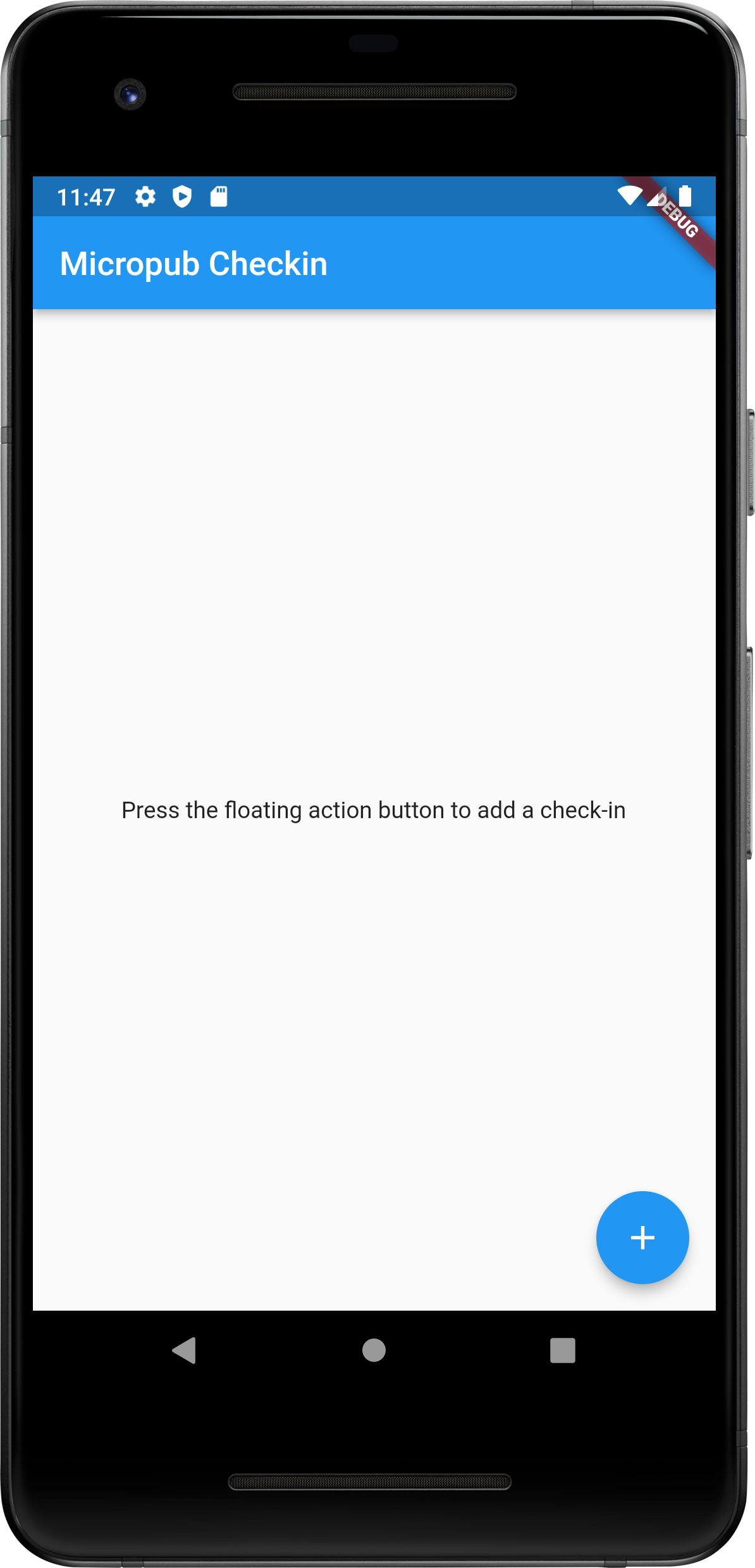
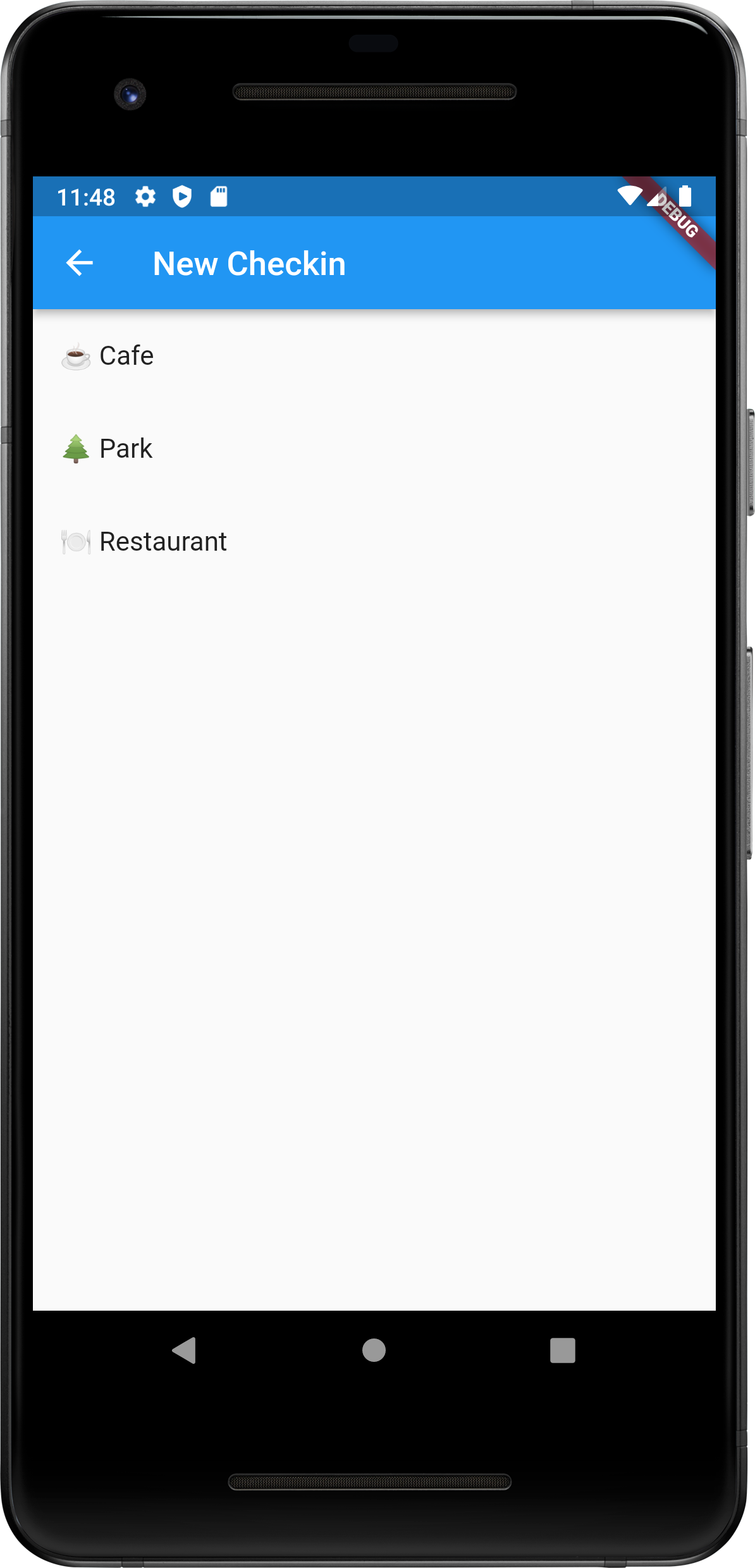
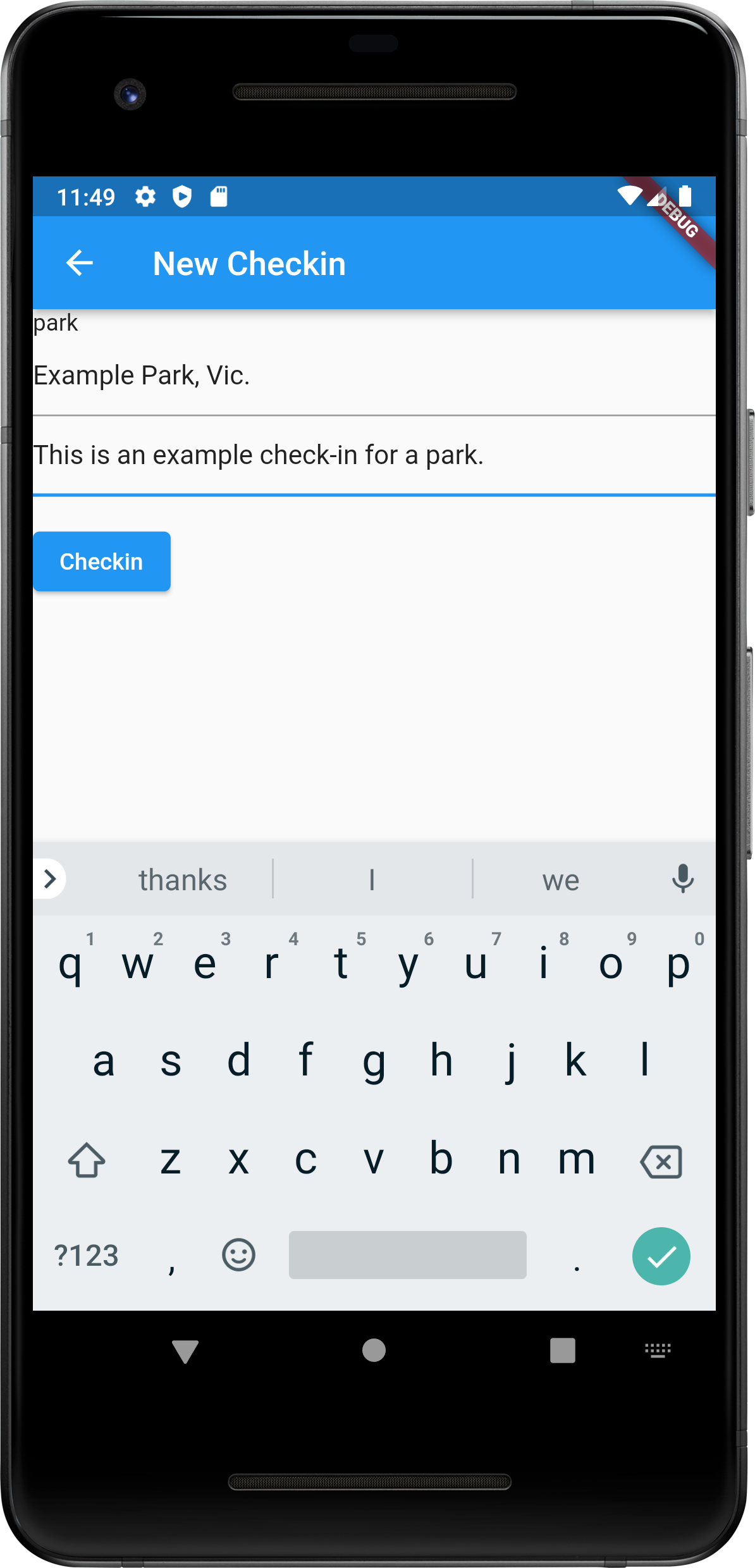

It’s still very early stages at this moment. For one thing, check-ins are published as soon as you press “Checkin”. Eventually they should be stored on the device and then published at a later time. The form for entering checkins should also be slightly different based on the checkin type. Restaurants and cafes should offer a field to enter a star rating, and airport checkins should provide a way to describe your route.
I’m not sure if I will pursue this any further. We’ll see how I feel. But it was good to get something up and running in a couple of hours.
Dynamo-Browse Running With iSH
Bit of a fun one today. After thinking about how one could go about setting up a small dev environment on the iPad, I remembered that I actually had iSH installed. I’ve had for a while but I’ve never really used it since I never installed tools that would be particularly useful. Thinking about what tools I could install, I was curious as to whether Dynamo-Browse could run on it. I guess if Dynamo-Browse was a simple CLI tool that does something and produces some output, it wouldn’t be to difficult to achieve this. But I don’t think I’d be exaggerating if I said Dynamo-Browse is a bit more sophisticated than your run-of-the-mill CLI tool. Part of this is finding out not only whether building it was possible, but whether it will run well.
Answering the first question involves determining which build settings to use to actually produce a binary that worked. Dynamo-Browse is a Go app, and Go has some pretty decent cross-compiling facilities so I had no doubt that such settings existed. My first thought was a Darwin ARM binary since that’s the OS and architecture of the iPad. But one of the features of iSH is that it actually converts the binary through a JIT before it runs it. And it turns out, after poking around a few of the included binaries using file, that iSH expects binaries to be ELF 32-bit Linux binaries.
Thus, setting GOOS to linux and GOARCH to 386 will produced a binary that would run in iSH:
GOOS=linux GOARCH=386 go build -o dynamo-browse-linux ./cmd/dynamo-browse/
After uploading it to the iPad using Airdrop and launching in in iSH, success!
So, is runs; but does is run well? Well, sadly no. Loading and scanning the table worked okay, but doing anything in the UI was an exercise in frustration. It takes about two seconds for the key press to be recognised and to move the selected row up or down. I’m not sure what the cause of this is but I suspect it’s the screen redrawing logic. There’s a lot of string manipulation involved which is not the most memory efficient. I’m wondering if building the app using TinyGo would improve things.
But even so, I’m reasonably impress that this worked at all. Whether it will mean that I’ll be using iSH more often for random tools I build remains to be seen, but at least the possibility is there.
Update: While watching a re:Invent session on how a company moved from Intel to ARM, they mentioned a massive hit to performance around a function that calculates the rune length of a Unicode character. This is something that this application is constantly doing in order to layout the elements on the screen. So I’m wondering if this utility function could be the cause of the slowdown.
Update 2: Ok, after thinking about this more, I think the last update makes no sense. For one thing, the binary iSH is running is an Intel one, and although iSH is interpreting it, I can’t imagine the slowdowns here are a result of the compiled binary. For another, both Intel and ARM (M1) builds of Dynamo-Browse work perfectly well on desktops and laptops (at least on MacOS systems). So the reason for the slowdown must be something else.
Nee Audax Toolset
I’ve decided to retire the Audax Toolset name, at least for the moment. It was too confusing to explain what it actually was, and with only a single tool implemented, this complexity was unnecessary.
The project is now named after the sole tool that is available: Dynamo-Browse. The site is now at dynamobrowse.app, although the old domain will still work. I haven’t renamed the repository just yet so there will still be references to “audax”, particularly the downloads section. I’m hoping to do this soon.
I think I’m happy with this decision. It really now puts focus on the project, and removes the feeling that another tool had to be built just to satisfy the name.
Most of what’s going on with Audax and Dynamo-Browse is “closing the gap” between the possible queries and scans that can be performed over a DynamoDB table, and how they’re represented in Dynamo-Browse query expression language. Most of the constructs of DynamoDB’s conditions expression language can now be represented. The last thing to add is the size() function, and that is proving to be a huge pain.
The reason is that the IR representation is using the expression builder package to actually put the expression together. These builders uses Go’s type system to enforce which constructs work with each other one. But this clashes with how I built the IR representation types, which are essentially structs implement a common interface. Without having an overarching type to represent an expression builder, I’m left with either using a very broad type like any, or completely ditching this package and doing something else to build the expression.
It feels pretty annoying reaching the brick wall just when I was finishing this off. But I guess them’s the breaks.
One other thing I’m still considering is spinning out Dynamo-Browse into a separate project. It currently sits under the “Audax” umbrella, with the intention of releasing other tools as part of the tool set. These tools actually exist1 but I haven’t been working on them and they’re not in a fit enough state to release them. So the whole Audax concept is confusing and difficult to explain with only one tool available at the moment.
I suppose if I wanted to work on the other tools, this will work out in the end. But I’m not sure that I do, at least not now. And even if I do, I’m now beginning to wonder if building them as TUI tools would be the best way to go.
So maybe the best course of action is to make Dynamo-Browse a project in it’s own right. I think it’s something I can resurrect later should I get to releasing a second tool.
Edit at 9:48: I managed to get support for the size function working. I did it by adding a new interface type with a function that returns a expression.OperandBuilder. The existing IR types representing names and values were modified to inherit this interface, which gave me a common type I could use for the equality and comparison expression builder functions.
This meant that the IR nodes that required a name and literal value operand — which are the only constructs allowed for key expressions — had to be split out into separate types from the “generic” ones that only worked on any OperandBuilder node. But this was not as large a change as I was expecting, and actually made the code a little neater.
Audax Toolset Version 0.1.0
Audax Toolset version 0.1.0 is finally released and is available on GitHub. This version contains updates to Dynamo-Browse, which is still the only tool in the toolset so far.
Here are some of the headline features.
Adjusting The Displayed Columns
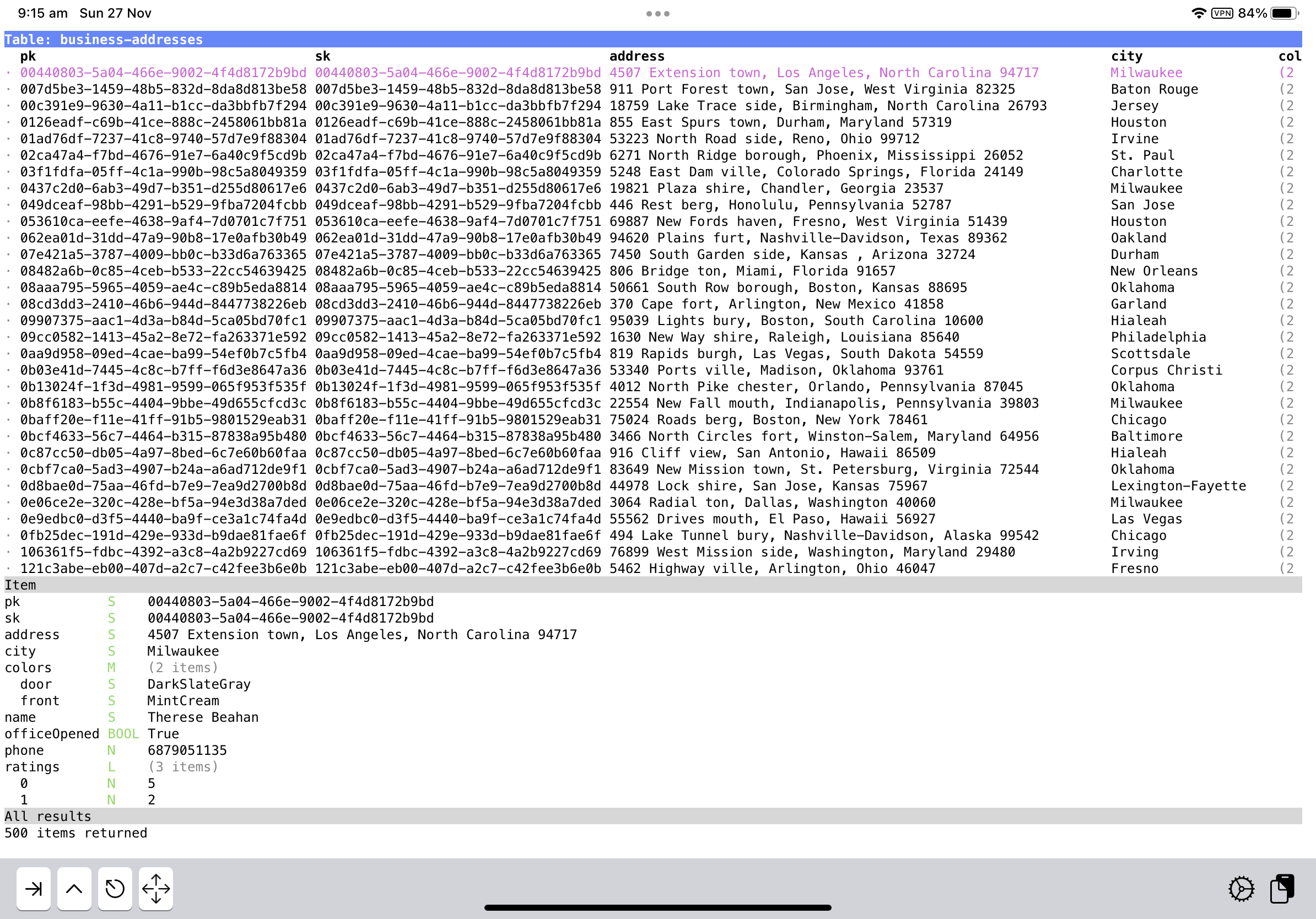
Consider a table full of items that look like the following:
pk S 00cae3cc-a9c0-4679-9e3a-032f75c2b506
sk S 00cae3cc-a9c0-4679-9e3a-032f75c2b506
address S 3473 Ville stad, Jersey , Mississippi 41540
city S Columbus
colors M (2 items)
door S MintCream
front S Tan
name S Creola Konopelski
officeOpened BOOL False
phone N 9974834360
ratings L (3 items)
0 N 4
1 N 3
2 N 4
web S http://www.investorgranular.net/proactive/integrate/open-source
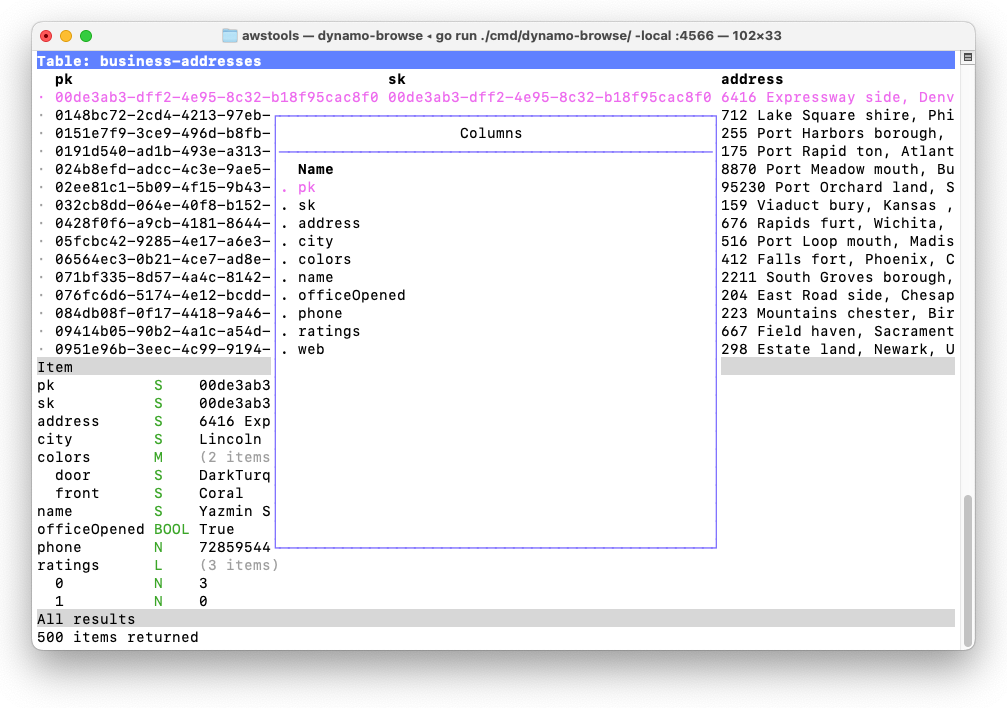
Let’s say you’re interested in seeing the city, the door colour and the website in the main table which, by default, would look something like this:
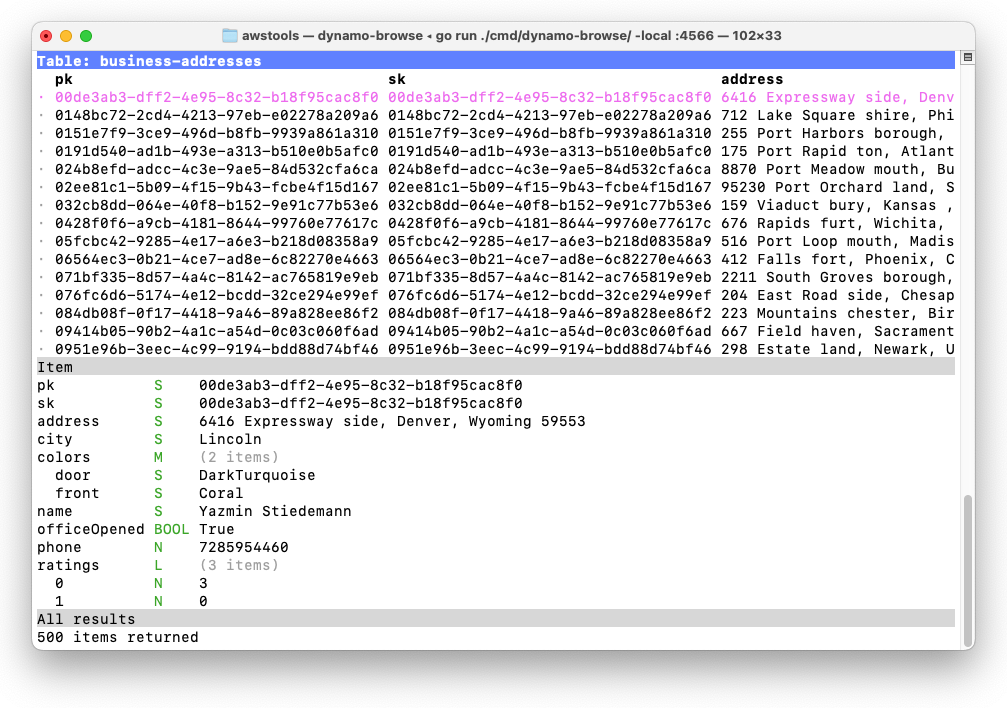
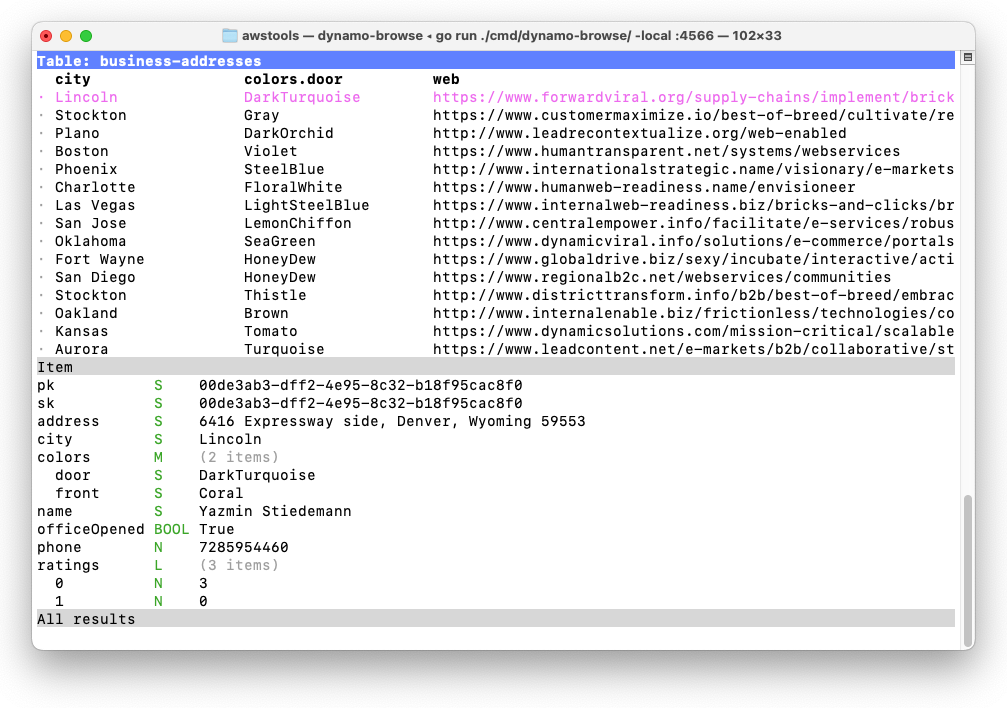
There are a few reasons why the table is laid out this way. The partition and sort key are always the first two columns, followed by any declared fields that may be used for indices. This is followed by all the other top-level fields sorted in alphabetical order. Nested fields are not included as columns, and maps and list fields are summarised with the number of items they hold, e.g. (2 items). This makes it impossible to only view the columns you’re interested in.
Version 0.1.0 now allows you to adjust the columns of the table. This is done using the Fields Popup, which can be opened by pressing f.
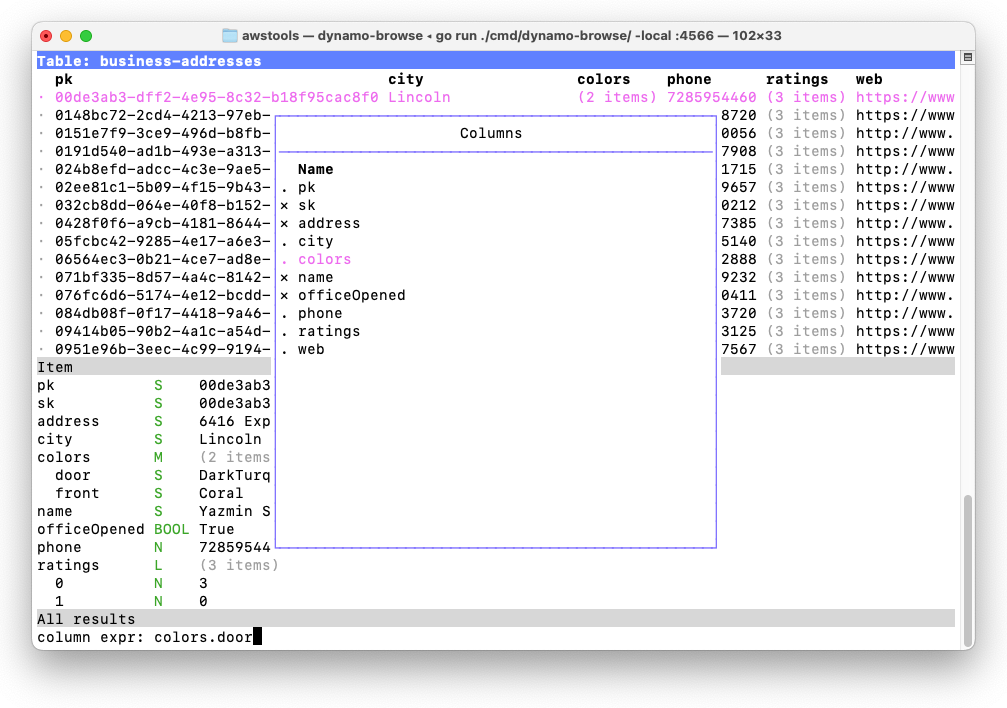
While this popup is visible you can show columns, hide them, or move them left or right. You can also add new columns by entering a Query Expression, which can be used to reveal the value of nested fields within the main table. It’s now possible to change the columns of the table to be exactly what you’re interested in:
Read-only Mode And Result Limits
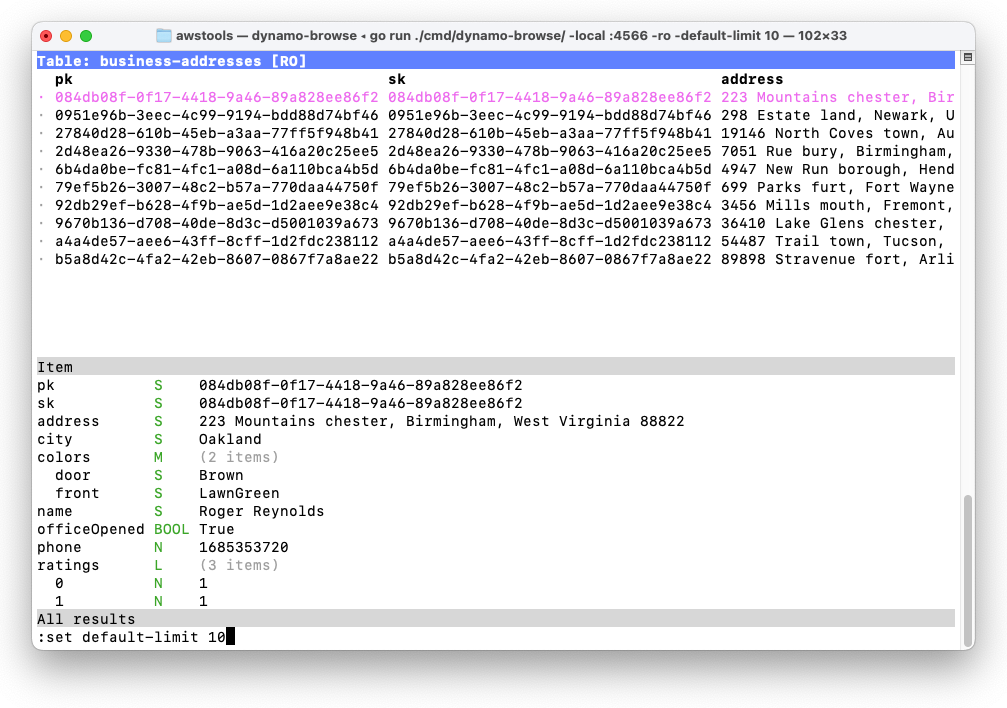
Version 0.1.0 also contains some niceties for reducing the impact of working on production tables. Dynamo-Browse can now be started in read-only mode using the -ro flag, which will disable all write operations — a useful feature if you’re paranoid about accidentally modifying data on production databases.
Another new flag is -default-limit which will change the default number of items returned from scans and queries from 1000 to whatever you want. This is useful to cut down on the number of read capacity units Dynamo-Browse will use on the initial scans of production tables.
These settings are also changeable from while Dynamo-Browse using the new set command:
Progress Indicators And Cancelation
Dynamo-Browse now indicates running operations, like scans or queries, with a spinner. This improves the user experience of prior versions of Dynamo-Browse, which gave no feedback of running operations whatsoever and would simply “pop-up” the result of such operations in a rather jarring way.
With this spinner visible in the status bar, it is also now possible to cancel an operation by pressing Ctrl-C. You have the option to view any partial results that were already retrieved at the time.
Other Changes
Here are some of the other bug-fix and improvements that are also included in this release:
Full details of the changes can be found on GitHub. Details about the various features can also be found in the user manual.
Finally, although it does not touch on any of the features described above, I recorded a introduction video on the basics of using Dynamo-Browse to view items of a DynamoDB table:
No promises, but I may record further videos touching on other aspects of the tool in the future. If that happens, I’ll make sure to mention them here.1
Putting the final touches on the website for the upcoming release of Audax Toolset v0.1.0, and I’m finding myself a bit unhappy with it. Given that Dynamo-Browse is the only tool in this “suite”, it feels weird putting together a landing page with a whole lot of prose about this supposed collection of tools. There’s no great place to talk more about Dynamo-Browse right there on the landing page.
Part of me is wondering whether it would be better focusing the site solely on Dynamo-Browse, and leave all this Audax Toolset stuff on the back-burner, at least until (or unless) another tool is made available through this collection. I’m wondering if I’ll need to rearrange the codebase to do this, and spin out the other commands currently in development into separate repositories.
Bridging The Confidence Gap
I had to do some production work with DynamoDB this morning. It wasn’t particularly complicated work: run a query, get a couple of rows, change two attributes on each one. I could have used Dynamo-Browse to do this. But I didn’t. Despite building a tool designed for doing these sorts of things, and using it constantly for all sorts of non-prod stuff, I couldn’t bring myself to use it on a production database.
I’m wondering why this is. It’s not like I have any issues with using Dynamo-Browse for the non-prod stuff. Sure there a bugs, and things that the tool can’t do yet, but I haven’t (yet) encountered a situation where the tool actually corrupted data. I also make sure that the code that touches the database is tested against a “real” instance of DynamoDB (it’s actually a mock server running in Docker).
Yet I still don’t have the confidence to use it on a production database. And okay, part of me understands this to a degree. I’ve only been using this tool for a handful of months, and when it comes to dealing with production data, having a sense of caution, bordering on a small sense of paranoia, is probably healthy. But if I can’t be confident that Dynamo-Browse will work properly when it matters the most, how can I expect others to have that confident?
So I’d like to get to the bottom of this. After a bit of thought, I think there are three primary causes of my lack of confidence here.
The first is simple: there are features missing in the tool that are needed to do my job. Things such as running a query over an index, or the ability to impose a conditional check on updates. This is a legitimate concern in my opinion: if you need to do something, and Dynamo-Browse doesn’t support it, then you can’t use Dynamo-Browse to do that thing, plain and simple. It’s also the easiest concern to address: either add the feature, or say that feature is unsupported and don’t expect people to use Dynamo-Browse if they need it.
I think the second cause is a lack of insight into what the tool is actually doing. Even though I built the tool and tested it during development, there’s always this feeling of uncertainty in the back of my head while I’m using it when the stakes are high. That feeling of “when I do this, although I think the tool will behave this way, how will the tool actually behave?” Part of this, I think, comes from a decade and a half of being burned by technology as part of my job, and growing a healthy (?) sense of distrust for it.1
I’m sure some of this will resolve itself as I continue to use Dynamo-Browse, but the only approach I know of gaining assurance that the tool is working as intended is if the tool tells me what it’s doing. Logging will help here, but I think some features that provide the user the ability to check what’s going to happen prior to actually doing it would be useful as well.
The third cause is probably a lack of controlled end-to-end testing. There does exists a suite of unit tests with a decent (maybe not good, but decent) level of coverage, but it does not extend to the UI layer, which is a little problematic. It might be that more testing of the application as a whole would help here.
This means more manual testing, but it might also be possible to setup some automated testing of the entire tool end-to-end here as well. What’s going for me is the fact that Dynamo-Browse runs in the terminal, and is responsible for rendering the UI and handling the event loop instead of palming this off to the OS. Looking at some of the features that Bubble Tea offers, it might be possible to run the application headless, and simulate use by pumping in keyboard events. Verifying that the UI is such may be a little difficult, but what I can test is what is actually read from and written to the database, which is what I’m mostly interested in.
I’m still unsure as to what I’ll do to address these three causes of concern. This is still a hobby project that I do in my spare time, and some of the mundane tasks, like more manual testing, sound unappealing. On the other hand, I do want to use this tool for my job, and I want others to use it as well. So I can’t really complain that others choose not to use it if I cannot feel comfortable using it when it matters most. So I probably should do some of each. And who knows, I may actually get some enjoyment out of doing it. I certainly would get some enjoyment from knowing that others can rely on it.
Things Dynamo-Browse Need
I’m working with dynamo-browse a lot this morning and I’m coming up with a bunch of usability shortcomings. I’m listing them here so I don’t forget.
The query language needs an in operator, such as pk in ("abc", "123"). This works like in in all the other database services out there, in that the expression effectively becomes `pk = “abc” or pk = “123”. Is this operator supported natively in DynamoDB? 🤔 Need to check that.
Likewise, the query language needs something to determine whether an attribute contains a substring. I believe DynamoDB expressions support this natively, so it probably makes sense to use that.
Longer term, it would be nice to include the results of the current result set in the expression. For example, assuming the current result set has these records:
pk sk thing place category
11 aa rock home geology
22 bb paper home art
33 cc scissors home utensils
and you want to effectively query for the rows where pk is equal to the set of pk in the current result set, having a way to do that in the expression language would save a lot of copy-and-pasting. An example might be pk in @pk or something similar, which could produce a result set of the form:
pk sk thing place category
11 aa rock home geology
11 ab sand beach ~
22 bb paper home art
22 bc cardboard shops ~
33 cc scissors home utensils
33 cd spoon cafe ~
Another way to do this might be to add support for filters, much like the expressions in JQ. For example, the second result set could be retrieved just by using a query expression of the form place = "home" | fanout pk, which could effectively do the following pesudo-code:
firstResultSet := query("place = 'home')
secondResultSet := newResultSet()
for pk in resultSet['pk'] {
secondResultSet += query("pk = ?", pk)
}
For dealing with workspaces, a quick way to open up the last workspace that you had opened would be nice, just in case you accidentally close Dynamo-Browse and you want to restore the last session you had opened. Something like screen -r. I think in this case having workspace files stored in the temporary directory might be a problem. Maybe having some way to set where workspace files are stored by default would work? 🤔
For dealing with marking rows, commands to quickly mark or unmark rows in bulk. There’s already the unmark command, but something similar for marking all rows would be good. This could be extended to only mark (or unmark) certain rows, such as those that match a particular substring (then again, using filters would work here as well).
It might be nice for refresh to keep your current row and column position, instead of going to the top-left. And it would also be nice to have a way to refresh credentials (could possiably be handled using the scripting framework).
And finally, if I have any doubt that the feature to hide or rearrange columns would not be useful, there was an instance today where I wish this feature was around. So, keep working on that.
I’m sure there will be more ideas. If so, I’ll post them here.
Overlay Composition Using Bubble Tea
Working on a new feature for Dynamo-Browse which will allow the user to modify the columns of the table: move them around, sort them, hide them, etc. I want the feature to be interactive instead of a whole lot of command incantations that are tedious to write. I also kind of want the table whose columns are being manipulated to be visible, just so that the affects of the change would be apparent to the user while they make them.
This is also an excuse to try something out using Bubble Tea — the TUI framework I’m using — which is to add the ability to display overlays. These are UI elements (the overlay) that appear above other UI elements (the background). The two are composed into a single view such that it looks like the overlay is obscuring parts of the background, similar to how windows work in MacOS.
Bubble Tea doesn’t have anything like this built in, and the way views are rendered in Bubble Tea doesn’t make this super easy. The best way to describe how views work is to think of them as “scanlines.” Each view produces a string with ANSI escape sequences to adjust the style. The string can contain newlines which can be used to move the cursor down while rendering. Thus, there’s no easy way position the cursor at an arbitrary position and render characters over the screen.1
So, I thought I’d tackle this myself.
Attempt 1
On the surface, the logic for this is simple. I’ll render the background layer up to the top most point of the overlay. Then for each scan line within the top and bottom border of the overlay, I’ll render the background up to the overlay’s left border, then the contents of the overlay itself, then the rest of the background from the right border of the overlay.
My first attempt was something like this:
line := backgroundScanner.Text()
if row >= c.overlayY && row < c.overlayY+c.overlayH {
// When scan line is within top & bottom of overlay
compositeOutput.WriteString(line[:c.foreX])
foregroundScanPos := row - c.overlayY
if foregroundScanPos < len(foregroundViewLines) {
displayLine := foregroundViewLines[foregroundScanPos]
compositeOutput.WriteString(lipgloss.PlaceHorizontal(
c.overlayW,
lipgloss.Left,
displayLine,
lipgloss.WithWhitespaceChars(" ")),
)
}
compositeOutput.WriteString(line[c.overlayX+c.overlayW:])
} else {
// Scan line is beyond overlay boundaries of overlay
compositeOutput.WriteString(line)
}
Here’s how that looked:
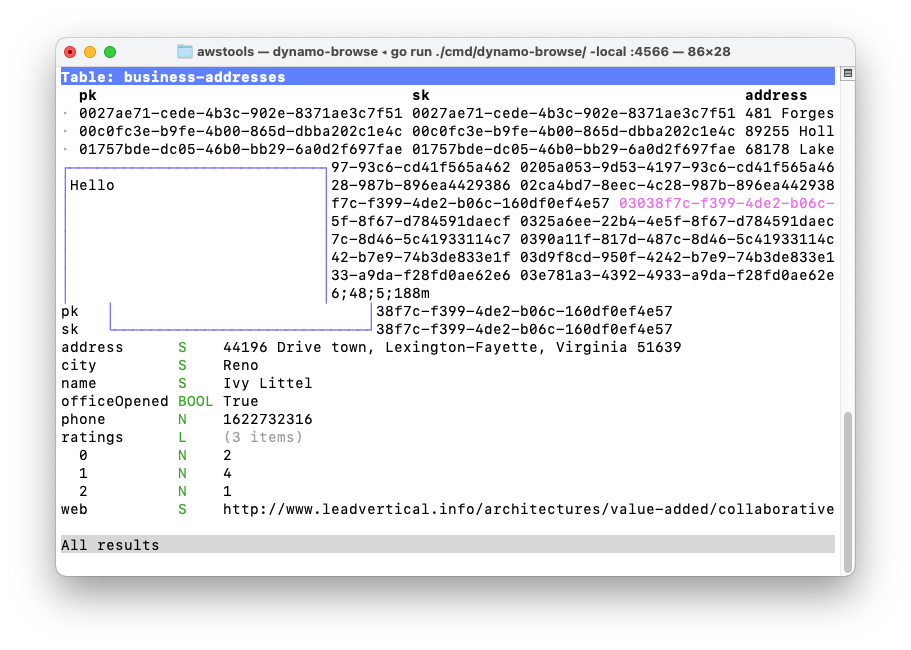
Yeah, not great.
Turns out I forgot two fundamental things. One is that the indices of Go strings works on the underlying byte array, not runes. This means that attempting to slice a string between multi-byte Unicode runes would produce junk. It’s a little difficult to find this in the Go Language Guide apart from this cryptic line:
A string’s bytes can be accessed by integer indices 0 through len(s)-1
But it’s relatively easy to test within the Go playground:
package main
import "fmt"
func main() {
fmt.Println("世界😀😚🙃😇🥸😎"[1:6]) // ��界
fmt.Println(string([]rune("世界😀😚🙃😇🥸😎")[1:6])) // 界😀😚🙃😇
}
The second issue is that I’m splitting half-way through an ANSI escape sequence. I don’t know how long the escape sequence is to style the header of the item view, but I’m betting that it’s longer than 5 bytes (the overlay is to be position at column 5). That would explain why there’s nothing showing up to the left of the overlay for most rows, and why the sequence 6;48;5;188m is there.
Attempt 2
I need to modify the logic so that zero-length escape sequences are preserved. Fortunately, one of Bubble Tea’s dependency is reflow, which offers a bunch of nice utilities for dealing with ANSI escape sequences. The function that looks promising is truncate.String, which will truncate a string at a given width.
So changing the logic slightly, the solution became this:
// When scan line is within top & bottom of overlay
compositeOutput.WriteString(truncate.String(line, uint(c.overlayX)))
foregroundScanPos := r - c.overlayY
if foregroundScanPos < len(foregroundViewLines) {
displayLine := foregroundViewLines[foregroundScanPos]
compositeOutput.WriteString(lipgloss.PlaceHorizontal(
c.overlayW,
lipgloss.Left,
displayLine,
lipgloss.WithWhitespaceChars(" "),
))
}
rightStr := truncate.String(line, uint(c.foreX+c.overlayW))
compositeOutput.WriteString(line[len(rightStr):])
The results are a little better. At least the left side of the overlay looked OK now:
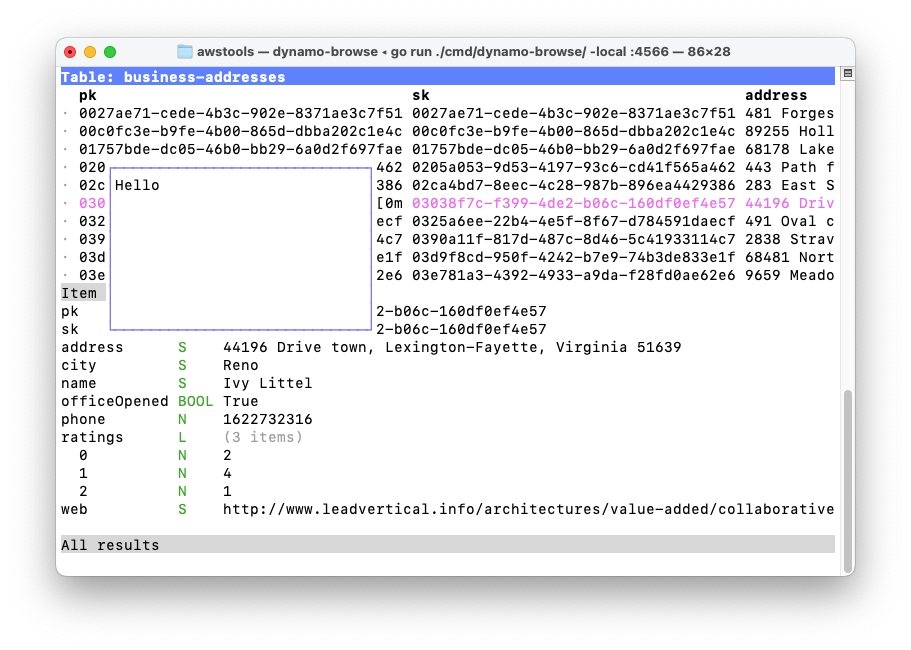
But there are still problems here. Notice the [0m at the right side of the overlay on the selected row. I can assure you that’s not part of the partition key; take a look at the item view to see for yourself. And while you’re there, notice the header of the item view? That should be a solid grey bar, but instead it’s cut off at the overlay.
I suspect that rightStr does not have the proper ANSI escape sequences. I’ll admit that the calculation used to set rightStr is a bit of a hack. I’ll need to replace it with a proper way to detect the boundary of an ANSI escape sequence. But it’s more than just that. If an ANSI escape sequence starts off at the left side of the string, and continues on “underneath” the overlay, it should be preserved on the right side of the overlay as well. The styling of the selected row and the item view headers are examples of that.
Attempt 3
So here’s what I’m considering: we “render” the background underneath the overlay to a null buffer while recording any escape sequences that were previously set on the left, or were changed underneath the overlay. We also keep track of the number of visible characters that were seen. Once the scan line position reached the right border of the overlay, we replay all the ANSI escape sequences in the order that were found, and then render the right hand side of the scan line from the first visible character.
I was originally considering rendering these characters to a null reader, but what I actually did was simply count the length of visible characters in a loop. The function to do this looks like this:
func (c *Compositor) renderBackgroundUpTo(line string, x int) string {
ansiSequences := new(strings.Builder)
posX := 0
inAnsi := false
for i, c := range line {
if c == ansi.Marker {
ansiSequences.WriteRune(c)
inAnsi = true
} else if inAnsi {
ansiSequences.WriteRune(c)
if ansi.IsTerminator(c) {
inAnsi = false
}
} else {
if posX >= x {
return ansiSequences.String() + line[i:]
}
posX += runewidth.RuneWidth(c)
}
}
return ""
}
And the value set to rightStr is changed to simply used this function:
rightStr := c.renderBackgroundUpTo(line, c.foreX+c.overlayW)
Here is the result:
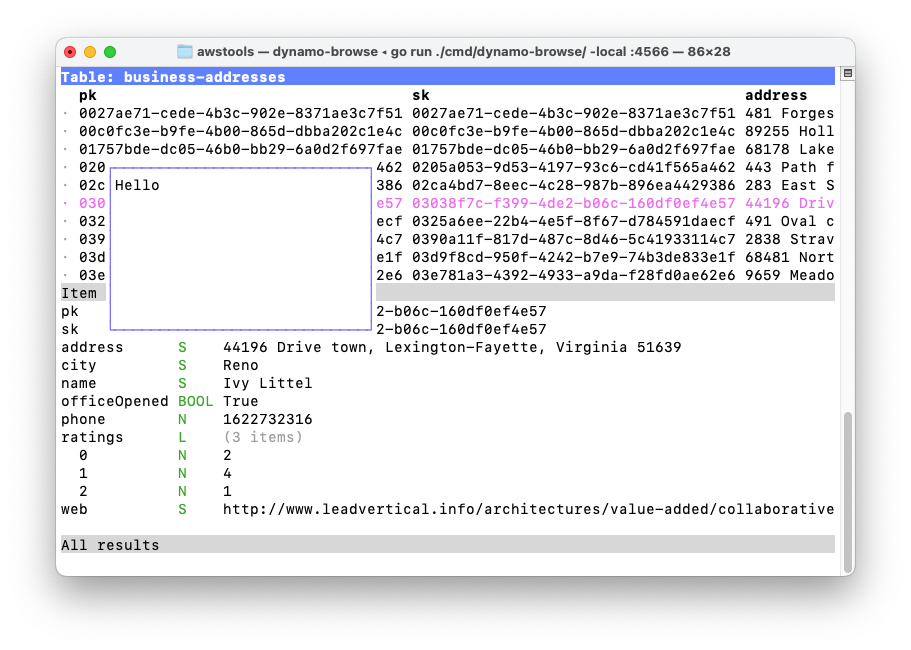
That looks a lot better. Gone are the artefacts from splitting in ANSI escape sequences, and the styling of the selected row and item view header are back.
I can probably work with this. I’m hoping to use this to provide a way to customise the columns with the table view. It’s most likely going to power other UI elements as well.
Intermediary Representation In Dynamo-Browse Expressions
One other thing I did in Dynamo-Browse is change how the query AST produced the actual DynamoDB call.
Previously, the AST produced the DynamoDB call directly. For example, if we were to use the expression pk = "something" and sk ^= "prefix", the generated AST may look something like the following:
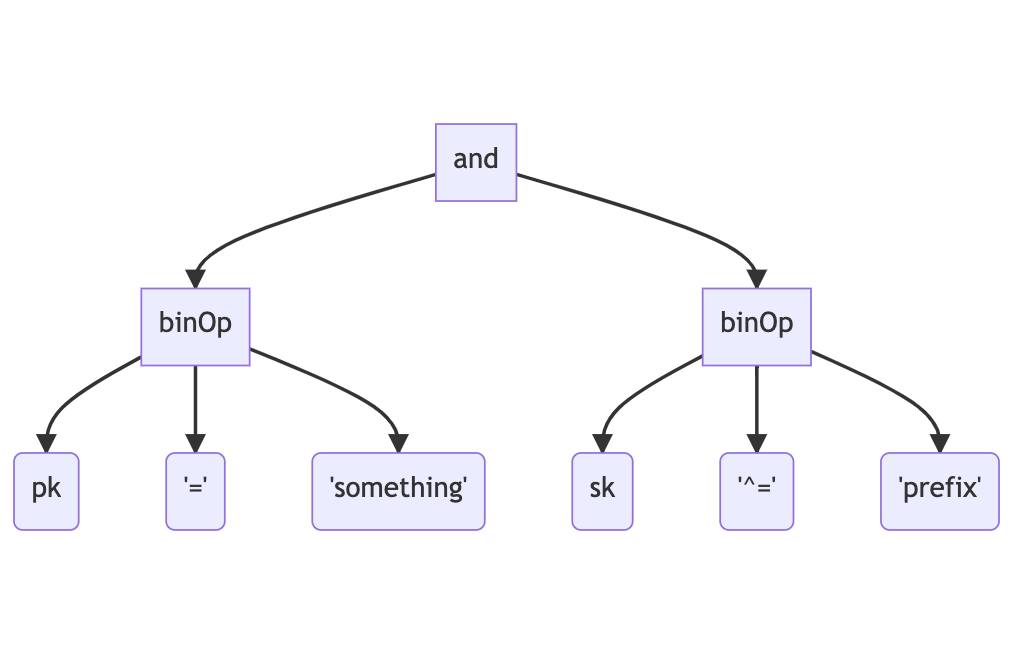
The AST will then be traversed to determine whether this could be handled by either running a query or a scan. This is called “planning” and the results of this will determine which DynamoDB API endpoint will be called to produce the result. This expression may produce a call to DynamoDB that would look like this:
client.Query(&dynamodb.QueryInput{
TableName: "my-table-name",
KeyConditionExpression: "#0 = :0 and beings_with(#1, :1)",
ExpressionAttributeNames: map[string]string{
"#0": "pk",
"#1": "sk",
},
ExpressionAttributeValues: map[string]types.AttributeValue{
":0": &types.StringAttributeValue{ Value: "something" },
":1": &types.StringAttributeValue{ Value: "prefix" },
},
})
Now, instead of determining the various calls to DynamoDB itself, the AST will generate an intermediary representation, something similar to the following:
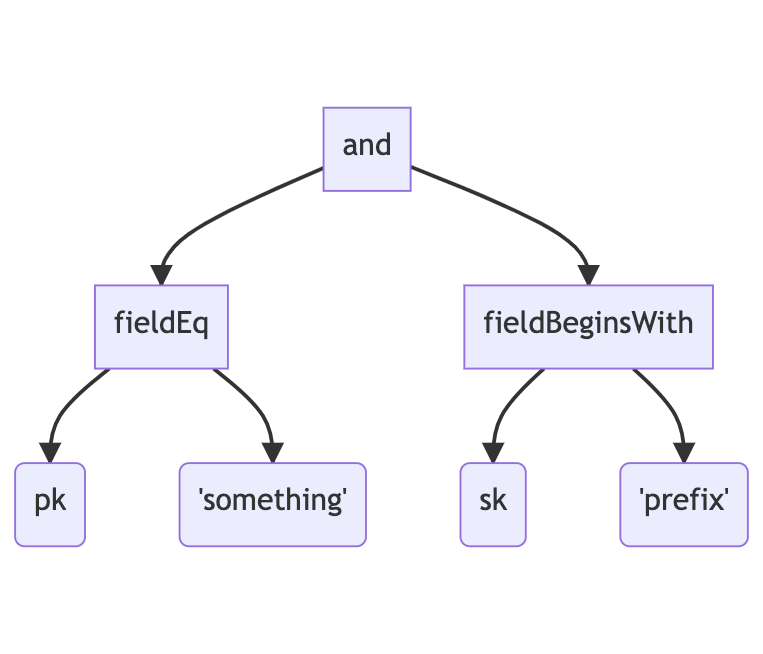
The planning traversal will now happen off this tree, much like it did over the AST.
For such a simple expression, the benefits of this extra step may not be so obvious. But there are some major advantages that I can see from doing this.
First, it simplifies the planning logic quite substantially. If you compare the first tree with the second, notice how the nodes below the “and” node are both of type “binOp”. This type of node represents a binary operation, which can either be = or ^=, plus all the other binary operators that may come along. Because so many operators are represented by this single node type, the logic of determining whether this part of the expression can be represented as a query will need to look something like the following:
This is mixing various stages of the compilation phase in a single traversal: determining what the operator is, determining whether the operands are valid (^= must have a string operand), and working out how we can run this as a query, if at all. You can imagine the code to do this being large and fiddly.
With the IR tree, the logic can be much simpler. The work surrounding the operand is done when the AST tree is traverse. This is trivial: if it’s = then produce a “fieldEq”; if it’s ^= then produce a “fieldBeginsWith”, and so on. Once we have the IR tree, we know that when we encounter a “fieldEq” node, this attribute can be represented as a query if the field name is either the partition or sort key. And when we encounter the “fieldBeginsWith” node, we know we can use a query if the field name is the sort key.
Second, it allows the AST to be richer and not tied to how the actual call is planned out. You won’t find the ^= operator in any of the expressions DynamoDB supports: this was added to Dynamo-Browse’s expression language to make it easier to write. But if we were to add the “official” function for this as well — begins_with() — and we weren’t using the IR, we would need to have the planning logic for this in two places. With an IR, we can simply have both operations produce a “fieldBeginsWith” node. Yes, there could be more code encapsulated by this IR node (there’s actually less) but it’s being leverage by two separate parts of the AST.
And since expressions are not directly mappable to DynamoDB expression types, we can theoretically do things like add arithmetic operations or a nice suite of utility functions. Provided that these produce a single result, these parts of the expression can be evaluated while the IR is being built, and the literal value returned that can be used directly.
It felt like a few other things went right with this decision. I was expecting this to take a few days, but I was actually able to get it built in a single evening. I’m also happy about how maintainable the code turned out to be. Although there are two separate tree-like types that need to be managed, both have logic which is much simpler than what we were dealing with before.
All in all, I’m quite happy with this decision.
Letting Queries Actually Be Queries In Dynamo-Browse
I spent some more time working on dynamo-browse over the weekend (I have to now that I’ve got a user-base 😄).
No real changes to scripting yet. It’s still only me that’s using it at the moment, and I’m hoping to keep it this way until I’m happy enough with the API. I think we getting close though. I haven’t made the changes discussed in the previous post about including the builtin plugin object. I’m thinking that instead of a builtin object, I’ll use another module instead, maybe something like the following:
const ext = require("audax:ext");
ext.registerCommand("thing", () => console.log("Do the thing"));
The idea is that the ext module will provide access to the extension points that the script can implement, such as registering new commands, etc.
At this stage, I’m not sure if I want to add the concept of namespaces to the ext module name. Could help in making it explicit that the user is accessing the hooks of “this” extension, as opposed to others. It may leave some room for some nice abilities, like provide a way to send messages to other extensions:
// com.example.showTables
// This extension will handle events which will prompt to show tables.
const ext = require("audax:ext/this");
ext.on("show-tables", () => {
ui.showTablePrompt();
});
// com.example.useShowTables
// This extension will use the "show-tables" message "com.example.showTables"
const showTables = require("audax:ext/com.example.showTables");
showTables.post("show-tables");
Then again, this might be unnecessary given that the JavaScript module facilities are there.
Anyway, what I actually did was start work on making queries actually run as queries against the DynamoDB table. In the released version, running a query (i.e. pressing ? and entering a query expression) will actually perform a table scan. Nothing against scans: they do what they need to do. But hardly the quickest way to get rows from DynamoDB if you know the partition and sort key.
So that’s what I’m working on now. Running a query of the form pk = "something" and sk = "else" where pk and sk are the partition and sort keys of the table will now call the dynamodb.Query API.
This also works with the “begins with” operator: pk = "something" and sk ^= "prefix". Since sk is the sort key, this will be executed as part of a query to DynamoDB.
This also works if you were to swap the keys around, as in sk = "else" and pk = "something". Surprisingly the Go SDK that I’m using does not support allow expressions like this: you must have the partition key before the sort key if you’re using KeyAnd. This touches on one of the design goals I have for queries: the user shouldn’t need to care how the expression actually produces the result. If it can do so by running an actual query against the table, then it will; if not, it will do a scan. Generally, the user shouldn’t care either way: just get me the results in the most efficient way you can think of!
That said, it might be necessary for the user to control this to an extent, such as requiring the use of a scan if the planner would normally go for a query. I may add some control to this in the expression language to support this. But these should be, as a rule, very rarely used.
Anyway, that’s the biggest change that’s happening. There is something else regarding expressions that I’m in the process of working on now. I’ll touch on that in another blog post.