
-
On TOON And Human Readable Data Formats
My thoughts on defining human readable formats that are difficult to modify by hand, and taking it out on TOON which is geared towards LLMs. Continue reading →
-
📘 Devlog
Laying The Groundwork For Dynamic Header Images
Making some changes to the Card theme I’m using for this blog. First think I’m considering is a banner image, similar to the one in Scripting News. And like Scripting News, I’m hoping for the image to change occasionally. I’d like the change to happen when the blog is being built, and in order to do this, I need a way to configure this value. I’m hoping to use Blogging Tools to do this, but to actually make use of these values, I’m hoping to use Hugo’s resource data methods.
Continue reading → -
📘 Devlog
Dynamo Browse - Item View Annotations and Asynchronous Tasks
Adding to the UCL extension support in Dynamo Browse the ability to annotate displayed result items, plus scheduling tasks that will be executed in the background. Continue reading →
-
Delta of the Defaults 2025
It’s been two years since I published the default apps I use after listening to Hemispheric Views #97 - Duel of the Defaults. A year later, I published a delta listing the changes I’ve made since that original list. Now that Cup Day is here, it’s time for the update no-one asked for.
Like last year, I’ll simply list the changes. You can see the original list of defaults here.
- Notes: The perennial category, apparently. 😀 I’m all in on Obsidian now, for all notes for work and my personal life, opting to pay for the 10 vault plan, which will become relevant for later categories. Only exception is Google Keep for my shopping lists.
- To-do: Obsidian too.
- Bookmarks: I still have that Linkding instance running on Pikapods, but I haven’t been using that as often as I had been. I tend to use Micro.blog’s Bookmarks feature for this now.
- Presentations: It’s two years and counting since I had to make a presentation. But it’s still iA Presenter, as I’m still paying for it.
- Social Clients: I’ve pulled away from the fediverse a little but I still use Micro.blog to follow Mastodon accounts. I have been spending more time perusing BlueSky, but I don’t want to get into the habit of spending too much time on the socials, so I simply use the browser for that.
- Music: Alto, my own music app, is still my primary music player. I’m no longer using Spotify, electing for YouTube music when I want to stream something. But lately, I’ve been buying most of my music on Qobuz and Bandcamp.
- Weather: Still using the Bureau of Meterology website, but wow, their recent redesign is a shocker. Fortunately the domain for their registered users, which has all the public pages, has been left untouched for now.
- Journalling App: Obsidian. This is where that 10 vault plan comes in handy.
-
📘 Devlog
Godot Game - Level 3-2 and a Rotating Platform
Starting to work on level 3-2, and adding a new rotating platform mechanic, with some thoughts on how to build it. Continue reading →
-
📘 Devlog
UCL - Adding Some Missing Library Functions
-
📘 Devlog
Godot Game - Working On Backdrops
Trying my hand in making some mountainous backdrops for world 3. Continue reading →
-
Ten Pointless Facts About Me
-
State of the Feed Reader
Auditing my RSS feed subscriptions and how frequently they’re being updated. Continue reading →
-
📘 Devlog
Godot Game - A Trigger That Reveals Secrets
A new mechanic has been developed to reveal hidden areas in a game when players approach, using an
Area2Dnode that fades tile layers in and out for a smoother experience. Continue reading → -
📘 Devlog
Godot Game - More on Level 3-1
Placing the exit and adding an invulnerability power-up. Continue reading →
-
📘 Devlog
Godot Game - More On Level 3-1
Continuing level 3-1, plus adding some more elements to stop long falls. Continue reading →
-
📘 Devlog
Godot Game - More On Level 3-1
Continuing the build out of the new zone for level 3-1, plus implement a new variant of the balloon with mine entity. Continue reading →
-
📘 Devlog
Godot Game - The Back Third of Level 3-1
Redoing the back third of level 3-1 to be a closer match to the front third. Continue reading →
-
📘 Devlog
Blogging Tools - Podcast Clip Favourites
Finishing off the favourite podcast clips feature. Continue reading →
-
📘 Devlog
Blogging Tools - Podcast Clip Favourites
Working on saving podcast clips from Blogging Tools into a Hugo site, done in the “lab notes” running commentary approach. Continue reading →
-
Hosting's Not the Problem With Distributed Video
The central challenge of open-web distributed video lies in creating a user-friendly experience that can compete with the convenience of platforms like YouTube. Continue reading →
-
Don't Choose To Reuse (Yet)
Designing software for reuse too early leads to unnecessary complexity and maintenance burdens, whereas focusing on immediate needs fosters simplicity and effectiveness. Continue reading →
-
New Theme, Who's Dis
451 words about switching over from Tiny Theme to Mythos. Continue reading →
-
Learning To Like Sentinel Errors In Go
Coming around to returning a result or an error in the Go programming instead of returning nil for both. Continue reading →
-
📘 Devlog
Trying OpenAI Codex to Produce Freelens Logo Creator
Using OpenAI Codex to make a logo generator tool to allow customisation for different clusters in Freelens. Continue reading →
-
📘 Devlog
Dequoter — Something Different Today
A new project called Dequoter was started to unquote a JSON string and filter it, utilizing Go for backend functionality and HTML for the frontend. Continue reading →
-
📘 Devlog
Godot Project — Bricks in Level 2-3 Laid
Just a quick update today. I’ve finished all the brickwork in level 2-3. And it didn’t go too badly. Made one significant mistake which would’ve involved a lot of rework, that I patched up with some single tiles:
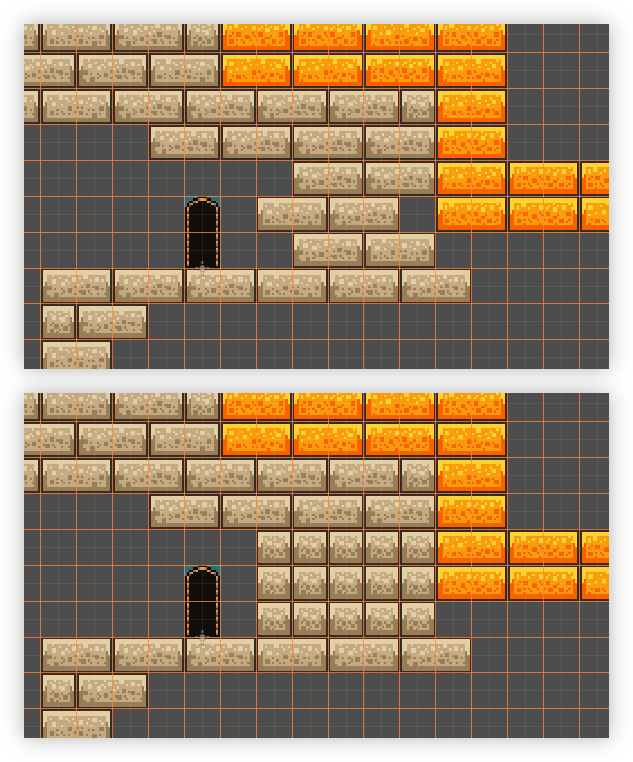
Top: the mistake. Bottom: the fix. Doing the rest of it was pretty dreary work. Godot does have some tools to make this easier, but there was no getting around the level of care needed to place the bricks correctly. But it’s all pretty much done now. And just for comparison to the before screenshots I took when I started, here’s how how the level looks now:
Continue reading → -
📘 Devlog
Shutting Down Nano Journal
With the move to Obsidian for my journalling needs, I shut down my bespoke journalling web-app. I deployed it on 26th August 2024, which makes it just over a year old. I did start using Obsidian on the 20th though, so it didn’t quite make it the entire year. Even so, not bad for something hand made and somewhat neglected. Most things I eventually abandon last way less than that.
Continue reading → -
📘 Devlog
Godot Project — Level 2-3 Update